Semantic Systems
Department of InformaticsSemantic Systems (SEMS)
Photo: UHH/Denstorf
18 October 2021, by David Mosteller
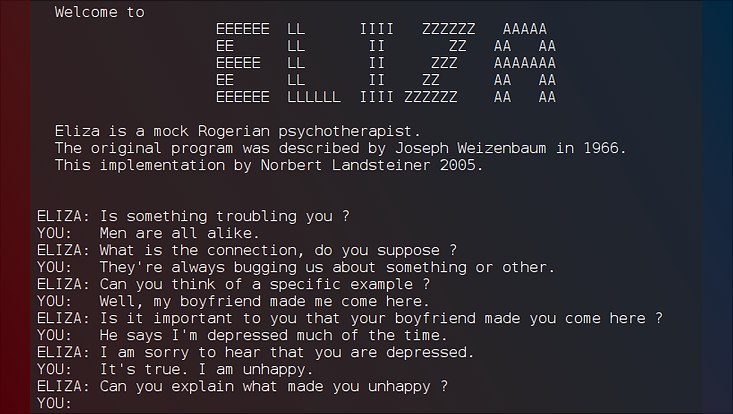
Photo: Unknown author, Public domain, via Wikimedia Commons
Written by Rostislav Nedelchev with feedback from Prof. Ricardo Usbeck and Prof. Jens Lehmann.
Currently, human judges have to evaluate dialogues’ quality. As a consequence, performing such evaluations at scale is usually expensive. Previous articles by Rostislav Nedelchev (https://sda-research.medium.com/evaluating-chit-chat-using-language-models-96118f42a78d) briefly introduced chatbots and their automatic evaluation using language models like GPT2, BERT, and XLNet. There, we discussed the importance of open-domain dialogue systems. We showed how probabilities inferred by the language model (LM) correlate with human evaluation scores. And hence, they are suitable for estimating dialogue quality.
Our novel work investigates using a deep-learning model trained on the General Language Understanding Evaluation (GLUE) benchmark to serve as a quality indication of open-domain dialogues. The aim is to use the various GLUE tasks as different perspectives on judging the quality of conversation, thus reducing the need for additional training data or responses that serve as quality references. Due to this nature, the method can infer various quality metrics and derive a component-based overall score.
Read the full blog post here https://sda-research.medium.com/how-to-evaluate-chat-quality-using-standard-nlp-benchmarks-f12b329e678c !
Read the full paper here https://jens-lehmann.org/files/2021/emnlp_dialogue_quality.pdf
Find the full open-source code here: https://github.com/SmartDataAnalytics/proxy_indicators