Research
Current Research Topics
 |
Visual Attention and Saliency DetectionVisual attention is the selection process in human vision which directs the gaze to the currently most interesting data. These might be salient regions which "pop out" of the image automatically, as in the picture on the left (bottom-up), or cues which are of current interest due to pre-knowledge about the target object or the scene (top-down). |
 |
Human Behavior AnalysisHuman Behavior is an interplay of affective, cognitive, and behavioral responses of humans, and understanding human behavior is essential for many tasks of human computer interaction. We are especially interested in tasks such as gesture recognition, in particular sign language recognition, emotion/affect recognition, and personality recognition. |
 |
Object Discovery and Object Proposal GenerationObject discovery is the task of finding unknown objects in a scene. Humans can easily distinguish objects from background without apparent effort, however, it is a challenging problem in machine vision with a chicken and egg problematic: how to tell what the objects are if their properties and features are not known? We propose approaches, inspired by the human visual system, to find object candidates in images and videos. |
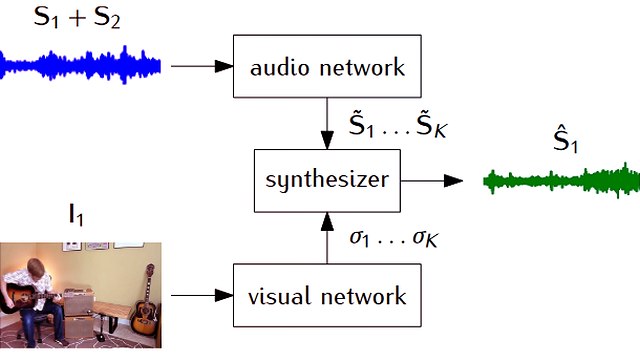 |
Multi-modal/Audio-Visual Signal ProcessingOur world is complex and using different senses helps humans to grasp different aspects of the world. Similarly, investigating multiple data modalities enables AI systems to exploit the advantages of each modality. Since modalities are often complementory, this offers plenty of opportunities to improve the system performance. We investigate and combine different modalities, such as audio-visual data or depth data to face the challenges of real-world data. |
Former Research Topics
 |
Active Perception (former project)Active Perception is the task of actively controlling the sensors of a system, e.g., a robot, to focus on regions of potential interest in the sensor date. The objective of active perception is to maximize the amount of information about the world. We develop information-theoretic and decision-theoretic approaches to plan where to look next. |
 |
Object Pose Estimation in Point Clouds (former project)Object pose estimation aims at estimating the 3D location and 3D orientation of an object in a 3D environment. It is an important prerequisite for object manipulation of a robot or for better understanding the spatial arrangement of objects in a scene. We develop deep-learning based methods for object pose estimation on 3D point cloud data. |
Object and Person Tracking (former project)Object tracking is an important task in many computer vision and robotic applications. It is especially difficult if not only the object but also the camera is mobile, as for tracking from a mobile robot. We are currently working on robust tracking methods which are based on a combination of feature saliencies and Particle filters. A special case is person tracking. It is necessary for mobile robots which have to follow a person as well as for robots which guide a person and which have to make sure that the guided person is still following. |
|
 |
Visual Simultaneous Localization And Mapping (former project)Visual Simultaneous Localization and Mapping (SLAM) is the task of automatically creating a map of the environment from image data without knowing the current exact position of the camera. It is usually of interest for mobile robots but can also be applied to hand-held cameras. We developed a visual SLAM system which finds salient landmarks, tracks them over frames and redetects them when returning to a known position. Active camera control improves the system performance. |