Knowledge Technology Corpora
This page contains selected corpora created by the Knowledge Technology Group.
Deictic Gestures Dataset for HRI

This dataset is a computer vision and video dataset built for training and evaluating downstream deictic (pointing) gesture recognition models in human-robot interaction (HRI) settings. Traditional gesture data collection requires expensive human recording sessions, which severely limits data scale and diversity. This dataset addresses that bottleneck by mixing real human data with realistic, image-to-video generated synthetic videos to train more robust models.
License:
This corpus is distributed under the Creative Commons CC BY-NC-ND 4.0 license. Please cite the paper below if you make use of the dataset in your own work.
Reference:
H. Ali, D. Jirak, L. Müller, and S. Wermter, Prompt-to-Gesture: Measuring the Capabilities of Image-to-Video Deictic Gesture Generation, 2026 International Conference on Automatic Face and Gesture Recognition (FG), arXiv:2604.14953.
Data:
The data is available at the following link: Prompt-to-Gesture.
Open Vocabulary Image Classification Datasets

Due to the free-form nature of the open vocabulary image classification task, special annotations are required for image sets used for evaluation purposes. Three such image datasets are presented here:
- World: 272 images of which the grand majority are originally sourced (have never been on the internet) from 10 countries by 12 people, with an active focus on covering as wide and varied concepts as possible, including unusual, deceptive and/or indirect representations of objects,
- Wiki: 1000 Wikipedia lead images sampled from a scraped pool of 18K,
- Val3K: 3000 images from the ImageNet-1K validation set, sampled uniformly across the classes.
License:
This corpus is distributed under the Creative Commons CC BY-NC-SA 4.0 license. Please cite the below paper if you make use of any of the datasets in your own work.
Reference:
P. Allgeuer, K. Ahrens, and S. Wermter (2025), Unconstrained Open Vocabulary Image Classification: Zero-Shot Transfer from Text to Image via CLIP Inversion. In IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), arxiv:2407.11211.
Data:
The data is available at the following links:
NOVIC: Unconstrained Open Vocabulary Image Classification
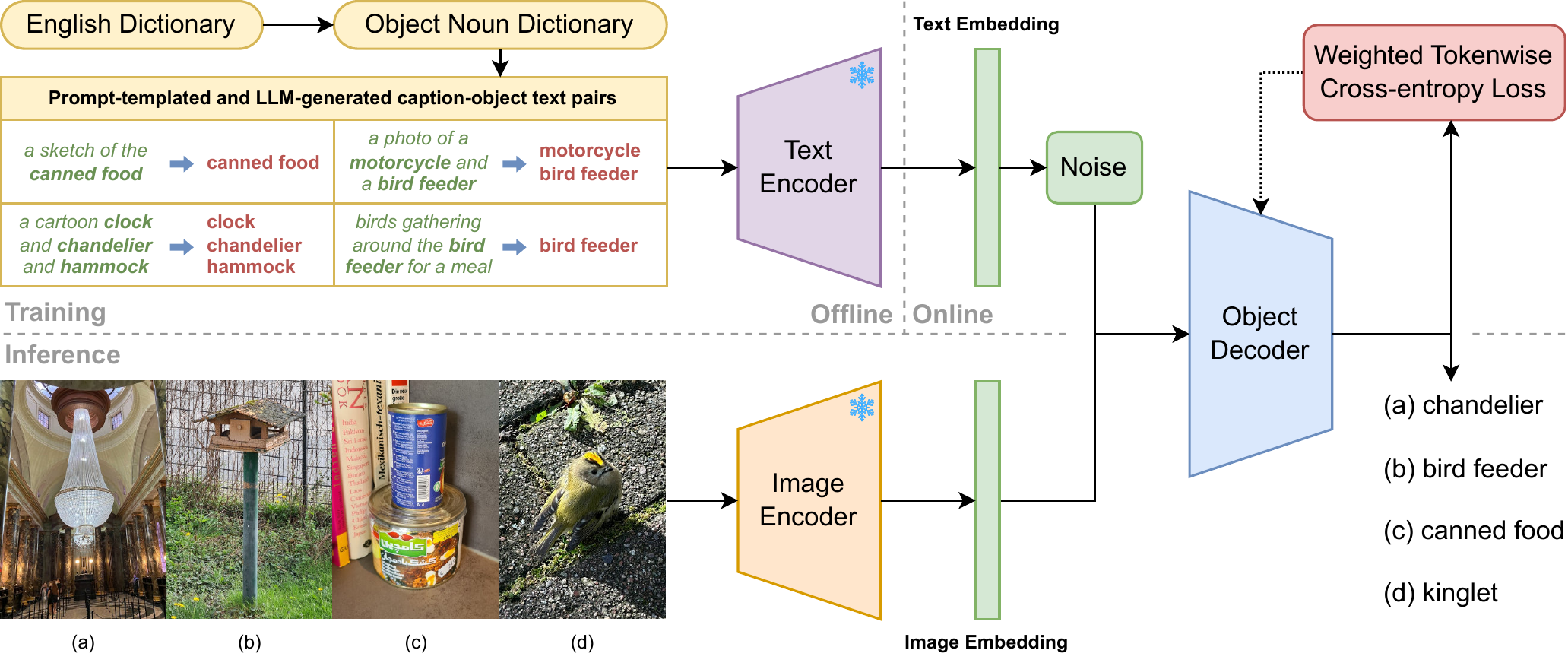
This corpus contains data files that were generated as part of the NOVIC paper (see below for reference). This includes the complete Object Noun Dictionary, the exact templates used for the multiset prompt templating strategy, and a large dataset of 1.8M LLM-generated and templated captions assorted by target noun. The captions were generated based on all of the target nouns in the Object Noun Dictionary.
License:
This corpus is distributed under the Creative Commons CC BY-NC-SA 4.0 license. Please cite the below paper if you make use of any of the data in your own work.
Reference:
P. Allgeuer, K. Ahrens, and S. Wermter (2025), Unconstrained Open Vocabulary Image Classification: Zero-Shot Transfer from Text to Image via CLIP Inversion. In IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), arxiv:2407.11211.
Data:
The data is available at the following links:
v-NICO-World-LL Dataset

The v-NICO-World-LL is a dataset created for object recognition in continual learning. It is recorded in a controlled virtual environment in Blender with a 3D model of the humanoid robot NICO. Objects are placed in the robot’s left hand. The fingers are positioned so that it looks as if the robot is holding the object. The robot’s arm is moving smoothly in a 10-s animation by manipulating an elbow, a wrist, and a palm joint, as well as three shoulder joints. RGB images are rendered with 24 fps. The image resolution is 256 × 256 pixels. The dataset consists of 95 objects belonging to 10 categories: ball, book, bottle, cup, doughnut, glasses, pen, pocket watch, present, and vase. The objects are manipulated in front of 20 different backgrounds, divided into four background complexities, each with five different background instances. These different background complexities allow the controlled evaluation of how LL models respond to different degrees of environmental conditions. Both real-world and artificially created backgrounds are used. In total, the dataset consists of 1,900 videos, each having 240 frames, resulting in 456,000 RGB images.
License:
This corpus is distributed under the Creative Commons CC BY-NC-ND 4.0 license. If you use this corpus, you agree (i) to use the corpus for research purpose only, and (ii) to cite the following reference in any works that make any use of the dataset.
Reference:
A. Logacjov, M. Kerzel, and S. Wermter, “Learning Then, Learning Now, and Every Second in Between: Lifelong Learning With a Simulated Humanoid Robot,” Frontiers in Neurorobotics, vol. 15, p. 78, 2021, doi: 10.3389/fnbot.2021.669534.
Data:
The data is available at the following link: v NICO World LL dataset.
GLips - German Lipreading Dataset
 The German Lipreading dataset consists of 250,000 publicly available videos of the faces of speakers of the Hessian Parliament, which was processed for word-level lip reading using an automatic pipeline. The format is similar to that of the English language Lip Reading in the Wild (LRW) dataset, with each H264-compressed MPEG-4 video encoding one word of interest in a context of 1.16 seconds duration, which yields compatibility for studying transfer learning between both datasets. Choosing video material based on naturally spoken language in a natural environment ensures more robust results for real-world applications than artificially generated datasets with as little noise as possible. The 500 different spoken words ranging between 4-18 characters in length each have 500 instances and separate MPEG-4 audio- and text metadata-files, originating from 1018 parliamentary sessions. Additionally, the complete TextGrid files containing the segmentation information of those sessions are also included. The size of the uncompressed dataset is 16GB.
The German Lipreading dataset consists of 250,000 publicly available videos of the faces of speakers of the Hessian Parliament, which was processed for word-level lip reading using an automatic pipeline. The format is similar to that of the English language Lip Reading in the Wild (LRW) dataset, with each H264-compressed MPEG-4 video encoding one word of interest in a context of 1.16 seconds duration, which yields compatibility for studying transfer learning between both datasets. Choosing video material based on naturally spoken language in a natural environment ensures more robust results for real-world applications than artificially generated datasets with as little noise as possible. The 500 different spoken words ranging between 4-18 characters in length each have 500 instances and separate MPEG-4 audio- and text metadata-files, originating from 1018 parliamentary sessions. Additionally, the complete TextGrid files containing the segmentation information of those sessions are also included. The size of the uncompressed dataset is 16GB.
License:
Copyright of original data: Hessian Parliament (https://hessischer-landtag.de). This corpus is distributed under the Creative Commons CC BY-NC-ND 4.0 license. If you use this corpus, you agree (i) to use the corpus for research purpose only, and (ii) to cite the following reference in any works that make any use of the dataset.
Reference:
Gerald Schwiebert, Cornelius Weber, Leyuan Qu, Henrique Siqueira, Stefan Wermter (2022) A Multimodal German Dataset for Automatic Lip Reading Systems and Transfer Learning. arXiv:2202.13403.
Data:
The data is hosted at the Center for Sustainable Research Data Management and available at this Download link.
Augmented Extended Train Robots Dataset

The Augmented Extended Dataset used in the paper Enhancing a Neurocognitive Shared Visuomotor Model for Object Identification, Localization, and Grasping With Learning From Auxiliary Tasks published in the IEEE TCDS journal, 2020.
This dataset is an extension of the Extended Train Robots (ETR) dataset. The ETR is a 3D block world dataset, with commands describing pick and place scenarios. The user commands a robot to allocate simple block structures. These commands are translated into a tree-structured Robot Command Language (RCL). The dataset was human-annotated with natural language commands after showing them a simulated scene before and after a given block was allocated.
The original ETR dataset contains pictures of a simulated environment, however, this does not provide enough variation on the visual layout, nor does it match realistic views. To overcome this limitation, we built this dataset where the layouts were constructed from the ground up through augmented reality. 3D computer-generated blocks were superimposed rather imprecisely on checkerboard pattern images captured in the real world. For testing purposes as well as the acquisition of the NICO arm's joint coordinates, we constructed a simulated environment using the MuJoCo simulator. Images of the NICO robot in the simulated environment from multiple views were captured and can be found in the simulated dataset (SimVisionMultimodalCSV). The translation dataset (LanguageTranslationMultimodalCSV) contains translations from natural language commands in English to RCL.
The data is fully augmented for the purpose of neural multitask learning. Noisy versions of the samples are also provided in the dataset.
Annotations
The dataset contains CSV annotations and image/speech data, distributed as such:
- VisionMultimodalCSV Contains the object detection annotations (bounding boxes surrounding the blocks and their classes). The augmented-reality images are found here as well
- SimVisionMultimodalCSV Contains the object detection annotations (bounding boxes surrounding the blocks and their classes). The simulated NICO images are found here as well
- LanguageTranslationMultiomdalCSV Contains the natural language instructions for manipulating the blocks along with their equivalent RCL translations
- FusionMultimodalCSV Contains the NICO arm's joint coordinates for reaching an object. The corresponding layouts (VisionMultimodalCSV) and commands (LanguageTranslationMultimodalCSV) are linked to the scenes in the annotation files
- SpeechMultimodalCSV Contains Synthetic WaveNet voices using the Google cloud's Text-to-Speech. Note that the speech data has not been utilized in this project but may be useful for future work on audiovisual integration.
License:
This corpus is distributed under the Creative Commons CC BY-NC-SA 4.0 license. Cite our paper if you make use of the dataset in your own work (Reference below)
Reference:
Kerzel, M., Abawi, F., Eppe, M., & Wermter, S. (2020). Enhancing a Neurocognitive Shared Visuomotor Model for Object Identification, Localization, and Grasping With Learning From Auxiliary Tasks. In IEEE Transactions on Cognitive and Developmental Systems (TCDS).
Data (preprocessed):
EDAs: Emotional Dialogue Acts Corpus
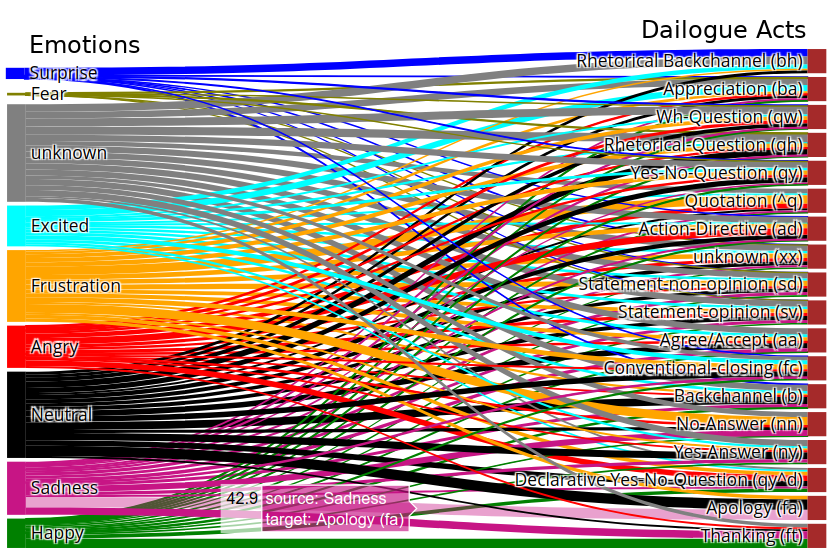
With the growing demand for human-computer/robot interaction systems, detecting the emotional state of the user can heavily benefit a conversational agent to respond at an appropriate emotional level. The research in emotion recognition is growing very rapidly and many datasets are available, such as text-based, speech- or vision-level, and multimodal emotion data. However, few conversational multi-modal emotion recognition datasets are available.
We annotated two popular multi-modal emotion datasets: IEMOCAP and MELD. We analyzed the co-occurrence of emotion and dialogue act labels and discovered specific relations. For example, Accept/Agree dialogue acts often occur with the Joy emotion, Apology with Sadness, and Thanking with Joy. We make the Emotional Dialogue Act (EDA) corpus publicly available to the research community for further study and analysis.
Corpus
Emotional Dialogue Act data contains dialogue act labels for existing emotion multi-modal conversational datasets.
Dialogue act provides an intention and performative function in an utterance of the dialogue. For example, it can infer a user's intention by distinguishing Question, Answer, Request, Agree/Reject, etc. and performative functions such as Acknowledgement, Conversational-opening or -closing, Thanking, etc.
MELD contains two labels for each utterance in a dialogue: Emotions and Sentiments.
- Emotions -- Anger, Disgust, Sadness, Joy, Neutral, Surprise and Fear.
- Sentiments -- positive, negative and neutral.
IEMOCAP contains only emotion but at two levels: Discrete and Fine-grained Dimensional Emotions.
- Discrete Emotions: Anger, Frustration, Sadness, Joy, Excited, Neutral, Surprise and Fear.
- Fine-grained Dimensional Emotions: Valence, Arousal and Dominance.
References
Bothe, C., Weber, C., Magg S., & Wermter, S. (2019). Enriching Existing Conversational Emotion Datasets with Dialogue Acts using Neural Annotators. arXiv preprint arXiv:1912.00819. 
More Information
To have access to this corpus, please visit our website: https://github.com/bothe/EDAs/
Embodied Multi-modal Interaction in Language learning (EMIL) data collection
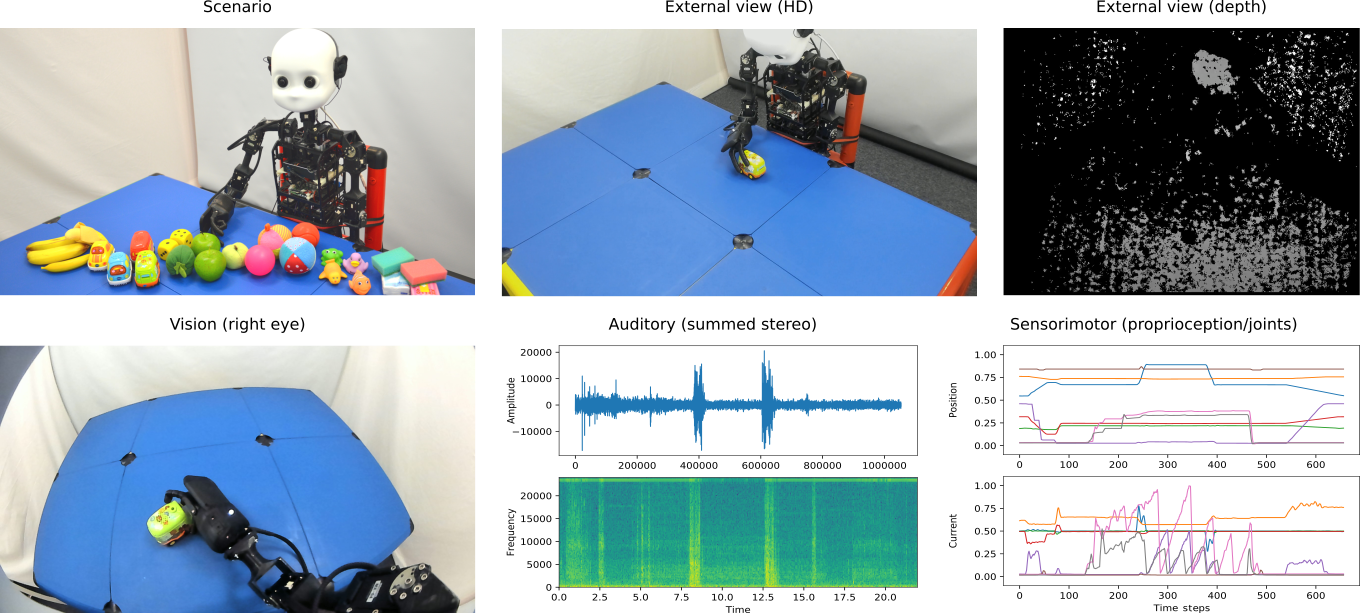
In this first set, the developmental robot NICO is mimicking an infant that interacts with objects and receives a linguistic label after an interaction. The interaction follows usual interaction schemes of 12--24 month-old infants on toy-like objects.
NICO includes two HD RGB cameras, stereo auditory perception, and interaction capabilities of a 3.5-year-old child, including six DOF arms and hands with multi-grip fingers and tactile sensors. In interactions with objects, the robot's hands as well as the whole upper body provide perception on a sensorimotor level and at the same time introduce the interaction imprecision and self-occlusion in a way our infants show.
In the setup, NICO is seated in a child-sized chair at a table, interacting with the right hand and facing the head downwards during the experiment, while a human places a small object on the table at a fixed position. A predefined action is carried out on the object, e.g., lifting it up or scooting it across the table. During the robot's actions, a continuous multi-modal recording encompasses continuous streams of visual information from the left and right robot camera as well as from the external experimenter, stereo audio information, and proprioceptive information from the robot's body. Finally, the experimenter provides a linguistic label.
Annotations
The dataset is annotated with
- the used interaction category and object,
- a ground truth for the object position (rectangular bounding box) with object-tracking tasks.
License:
This corpus is distributed under the Creative Commons CC BY-NC-SA 3.0 DE license. If you use this corpus, you have to agree with the following items:
- To cite our reference in any of your papers that make any use of the database. The references are provided at the end of this page.
- To use the corpus for research purpose only.
- To not provide the corpus to any second parties.
Reference:
Heinrich, S., Kerzel, M., Strahl, E., & Wermter, S. (2018). Embodied Multi-modal Interaction in Language learning: the EMIL data collection. In Proceedings of the ICDL-EpiRob Workshop on Active Vision, Attention, and Learning (ICDL-Epirob 2018 AVAL).
Data (preprocessed):
Active Exploration Object Dataset
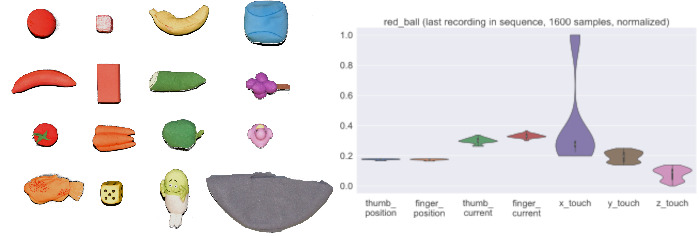
Recognition of real object properties is vital to avoid danger, e.g., a soft object needs to be grasped firmly to avoid slippage while fragile objects require a soft grasp. Haptic perception is also relevant when identifying objects in the absence of visual information, e.g., when a robot is picking up an occluded object. However, haptic perception is complex: in contrast to visual perception, haptic perception requires motor actions to actively explore an object. In humans, the resulting haptic perception is mediated by several different sensory subsystems ranging from different tactile sensing cells in the skin to proprioception of position and forces in joints, tendons, and muscles. Likewise, for robotic agents, signals from specialized types of tactile sensors, position and currents of motors need to be integrated to facilitate haptic perception.
Object Classification
We created a haptic dataset with 83200 haptic measurements, based on 100 samples of each of 16 different objects, every sample containing 52 measurements. We develop a series of neural models (MLP, CNN, LSTM) that integrate the haptic sensory channels to classify explored objects. As an initial baseline, our best model achieves a 66.6% classification accuracy over 16 objects using 10-fold crossvalidation. Further information on the model evaluations and the specific parametrization are described in the reference paper.
Dataset recordings:
- The NICO robots is placed at a table with the left palm open
- Data sampling starts when an object is placed into the robot hand
- In total 16 objects were used
- Data stored:
- the position of index fingers
- position of the thumb
- current in finger motor
- current in thumb motor
- x-,y-, and z-forces in the tactile sensor embedded into the thumb
- Each data collection sample (1600 per object) has a fixed length of 52 time steps
License
- To cite our reference in any of your papers that make any use of the database. The references are provided at the end of this page.
- To use the corpus for research purpose only.
- To not provide the corpus to any second parties.
Download dataset: Kerzel_IJCNN_2019_data.zip
For further inquiries contact: {kerzel, strahl}@informatik.uni-hamburg.de
Reference: Kerzel M., Strahl E., Gaede C., Gasanov E. & Wermter S. (2019). Neuro-Robotic Haptic Object Classification by Active Exploration on a Novel Dataset, Proceedings of the International Joint Conference on Neural Networks (IJCNN), in print.
Multi Person Command Gesture Data

Understanding complex scenes with multiple people still poses problems to current computer vision approaches. Experiments with application-specific motion, such as gesture recognition scenarios, are often constrained to single person scenes in the literature. Therefore, we conducted a study to address the challenging task of detecting salient body motion in scenes with more than one person. We introduced an approach to combine Kinect recordings of one person into artificial scenes with multiple people. This corpus accompanies said study and consist of the raw Kinect frames (single-person recordings) and also a dataset package with multi-person scenes.
Raw data package
The raw Kinect sequences of single-person recordings show 8 command gestures for Human-Robot Interaction (HRI) and one contrast class with Passive body positions and different minimal body movement. We recorded 6 people, each performing the gestures listed below. One person was female, five were male, and the age ranged from 25 to 34 years. In total, all participants combined performed 568 instances of gestures, yielding a total number of 43,034 frames. These frames are labeled with bounding boxes of the full body and bounding boxes of the head.
Gesture Descriptions:
- Abort - 62 Sequences: Lift the hand to the height of the throat and then sliding across the throat before lowering the hand again.
- Check - 66 Sequences: Lifting up the hand and drawing a large check sign in the air .
- Circle - 72 Sequences. Moving the hand in a large circle so that the full circle is visible to the Kinect.
- Doublewave - 66 Sequences: Raising both arms and waving with lower arms synchronously.
- Point - 110 Sequences. Lifting up the hand and pointing to the side, away from the body.
- Stop - 53 Sequences: Raising hand to the front, inner hand facing outwards, fingers pointing up, fingers closed.
- Wave - 62 Sequences. Waving with one hand.
- X (Cross) - 63 Sequences: Lifting up the hand and drawing a large cross symbol in the air.
- Passive - 14 longer Sequences: Different versions of non-gestures: Directly facing the sensor, being slightly turned towards one side, hands hanging down or hands attached to the body. Some recordings include slow movement of the feet or the upper torso. The main difference to the active gesture recording is that none of these passive recordings include strong arm movement.
The size of the raw dataset is 10.7 GB and is only available via request to one of the authors of the reference below.
Synthesized Kinect data
The dataset contains synthesized Kinect data of scenes with zero people up to 3 people in the scene, with up to one person performing a gesture. The dataset is split into train, validation and test sets. In total, the dataset containts 2600 samples, where each sample consists of 15 frames and one teacher frame which acts as the sample's label.
License
This corpus is distributed under the Creative Commons CC BY-NC-SA 3.0 DE license. If you use this corpus, you have to agree with the following items:
- To cite our reference in any of your papers that make any use of the database. The references are provided at the end of this page.
- To use the corpus for research purpose only.
- To not provide the corpus to any second parties.
Download dataset: MultiPersonGestures_Kinect.zip
Code and further descriptions available on Github
For further inquiries contact: jirak@informatik.uni-hamburg.de
Reference (Open Access):
OMG-Emotion Dataset

This dataset is composed of Youtube videos which are about a minute in length and are annotated taking into consideration a continuous emotional behavior. The videos were selected using a crawler technique that uses specific keywords based on long-term emotional behaviors such as "monologues", "auditions", "dialogues" and "emotional scenes".
After the videos were selected, we created an algorithm to identify if the video has at least two different modalities which contribute for the emotional categorization: facial expressions, language context, and a reasonably noiseless environment. We selected a total of 420 videos, totaling around 10 hours of data.
Annotations and Labels
We used the Amazon Mechanical Turk platform to create an utterance-level annotation for each video, exemplified in the Figure below. We assure that for each video we have a total of 5 different annotators. To make sure that the contextual information was taken into consideration, the annotator watched the whole video in a sequence and was asked, after each utterance, to annotate the arousal and valence of what was displayed. We provide a gold standard for the annotations. This results in trustworthy labels that are truly representative of the subjective annotations from each of the annotators, providing an objective metric for evaluation. That means that for each utterance we have one value of arousal and valence. We then calculate the Concordance Correlation Coefficient (CCC) for each video, which represents the correlation between the annotations and varies from -1 (total disagreement) to 1 (total agreement).
Evaluation Protocol
We release the dataset with the gold standard for arousal and valence as well as the individual annotations for each reviewer, which can help the development of different models. We calculate the final CCC against the gold standard for each video. We also distribute the transcripts of what was spoken in each of the videos, as the contextual information is important to determine gradual emotional change through the utterances. The participants are encouraged to use crossmodal information in their models, as the videos were labeled by humans without distinction of any modality.
We also make available to the participating teams a set of scripts which will help them to pre-process the dataset and evaluate their model during the training phase.
References
Barros, P., Churamani, N., Lakomkin, E., Siqueira, H., Sutherland, A., & Wermter, S. (2018). The omg-emotion behavior dataset. arXiv preprint arXiv:1803.05434.
More Information
For more information, please visit our website: https://github.com/knowledgetechnologyuhh/OMGEmotionChallenge
NICO-object interaction data (NICO-OI)

We recorded 60 object-hand interactions, at 30 frames per seconds from the perspective of the NICO robot.
NICO (Neuro-Inspired COmpanion) is a developmental robot, which is used in research on multi-modal human-robot interaction and neuro-cognitive, and includes two HD RGB cameras and interaction capabilities of a 3.5-year-old child. In interactions with objects, the robot's hands are naturally introducing huge occlusions, making the tracking of object-manipulation-effects from the visual perspective difficult.
The recordings include different push, pull, grasp, and lift actions on a broad range of toy objects that show diverse behaviour when interacted with, such as rolling away, bouncing on the table, or changing their morphology. Compared to other SOTA object-tracking datasets, the conditions on object scale and in-plane-rotation are particularly difficult.
Annotations
The dataset is annotated with a ground truth for the object position (rectangular bounding box) with object-tracking tasks.
License:
This corpus is distributed under the Creative Commons CC BY-NC-SA 3.0 DE license. If you use this corpus, you have to agree with the following items:
- To cite our reference in any of your papers that make any use of the database. The references are provided at the end of this page.
- To use the corpus for research purpose only.
- To not provide the corpus to any second parties.
Reference:
When using this dataset please cite:
Data:
Gesture Commands for Robot InTeraction (GRIT)
 Gestures constitute a crucial element in human communication, as well as in human-robot interaction, thus, gesture recognition has been a field of particular interest in computer science. More specifically, dynamic gesture recognition is a challenging task, since it requires the accurate detection of the body parts involved in the gesture, their tracking and the interpretation of their sequential movement.
Gestures constitute a crucial element in human communication, as well as in human-robot interaction, thus, gesture recognition has been a field of particular interest in computer science. More specifically, dynamic gesture recognition is a challenging task, since it requires the accurate detection of the body parts involved in the gesture, their tracking and the interpretation of their sequential movement.
To evaluate our systems on a dynamic command gesture recognition task, we designed, recorded and organized the TsironiGR corpus. This corpus contains nine command gestures for Human-Robot Interaction (HRI): Abort, Circle, Hello, No, Stop, Turn Right, Turn Left, and Warn. Six different subjects were recorded, each one performing at least ten times the same gesture. We recorded a total of 543 sequences. Each of the gesture sequences is segmented and labeled with one of the nine classes. The gestures were captured by an RGB camera with a resolution of 640x480, recorded with a frame rate of 30 FPS.
The gesture descriptions are provided below:
-
Abort - 57 Sequences -It is a gesture that requires the motion of the hand in front of the throat with the palm facing downwards. - Circle - 60 Sequences - This gesture is a cyclic movement starting from the shoulder with the arm and the index finger
being stretched out. The movement is taking place in front of the body of the user while he/she is facing the direction of the capturing sensor. - Hello - 59 Sequences - As its name denotes, it is the typical greeting gesture, with the hand waving while facing the direction of the robot. The waving starts from the elbow rotation.
- No - 62 Sequences - To perform this gesture the arm and the index finger need to be stretched out towards the direction of the robot and then the repeating wrist rotation alternately to the right and the left.
- Turn Left - 62 Sequences - As the name of gesture denotes, the arm is pointing to the left.
- Turn Right - 60 Sequences - In the same sense as Turn Left, this gesture consists of the arm pointing to the right.
- Stop - 60 Sequences - The gesture includes raising the arm in front of the body with the palm facing the robot.
- Turn - 63 Sequences - This gesture is a cyclic movement starting with a rotation from the elbow including the simultaneous rotation of the wrist with the index finger stretched pointing downwards. The signature of this movement seems like a circle.
- Warn - 60 Sequences - This gesture firstly requires raising the hand in front of the body having an angle between the upper and the lower arm greater than 90 degrees and then rotating the elbow while the palm is being stretched out.
License:
This corpus is distributed under the Creative Commons CC BY-NC-SA 3.0 DE license. If you use this corpus, you have to agree with the following
- To cite our reference in any of your papers that make any use of the database. The references are provided at the end of this page.
- To use the corpus for research purpose only.
- To not provide the corpus to any second parties.
Contact:
To have access to this corpus, please send an e-mail with your name, affiliation and research summary
Reference:
| Tsironi, E., Barros, P., Weber, C., & Wermter, S. (2017). An analysis of convolutional long short-term memory recurrent neural networks for gesture recognition. Neurocomputing, 268, 76-86. |
Embodied Language Learning NICO-2-Objects Dataset

Embodied Language Learning NICO-2-Objects dataset consists of pairs of visual observations and joint values of NICO's left arm for the actions with their corresponding textual descriptions as NICO interacts with objects in a tabletop set-up. The robot actions are described as sequences of joint angle values, which are realised with an inverse kinematics solver, while the visual input is gathered from the egocentric perspective of NICO. The textual descriptions are organised word-by-word with one-hot encoding. The dataset is generated in a virtual environment realised with Blender (www.blender.org). The simulation is based on a URDF model of the NICO robot. For every action, there are only two objects present on the table. The dataset has 864 pairs of action-object arrangement in total, which are then split into training and test sets. The original dataset involves only the cubes of six different colours. However, six toy objects of the same colour are also included for variety.
Licence:
This corpus is distributed under the Creative Commons CC BY-NC-ND 4.0 license. If you use this corpus, you agree (i) to use the corpus for research purpose only, and (ii) to cite the following reference in any works that make any use of the dataset.
Reference:
Ozan Özdemir, Matthias Kerzel, and Stefan Wermter. Embodied language learning with paired variational autoencoders. In 2021 IEEE International Conference on Development and Learning (ICDL), pages 1–6. IEEE, Aug 2021.
Data:
The dataset is available at: Embodied Language Learning NICO-2-Objects
NAO Camera hand posture Database (NCD)

To evaluate computational models in a realistic human-robot interaction scenario, we designed and recorded a database using the camera of a small, 58cm tall, NAO robot with four different hand postures.
For each hand posture between 400 and 500 images where collected, each one with a dimension of 640x480 pixels. In each image, the hand was is present in different
positions, not always in the centralized, and sometimes with occlusion of some
fingers.
Evaluation Protocol
A random training, validation and testing split must be generated using 70% of the images in each posture for training the model and 30% as testing. We calculate the mean and standard deviation of the F1-score for 30 experiments.
License:
This corpus is distributed under the Creative Commons CC BY-NC-SA 3.0 DE license. If you use this corpus, you have to agree with the following items:
- To cite our reference in any of your papers that make any use of the database. The references are provided at the end of this page.
- To use the corpus for research purpose only.
- To not provide the corpus to any second parties.
References:
Jirak, D., Wermter, S. (2018). Sparse Autoencoders for Posture Recognition. In Proceedings of International Joint Conference on Neural Networks, (pp. 2359-2548) 
Barros, P., Magg, S., Weber, C., & Wermter, S. (2014). A multichannel convolutional neural network for hand posture recognition. In International Conference on Artificial Neural Networks (pp. 403-410)
Contact:
To have access to this corpus, please send an e-mail with your name, affiliation and research summary