Software
This page contains selected Open Source software projects created by the Knowledge Technology Group.
NOVIC: Unconstrained Open Vocabulary Image Classification
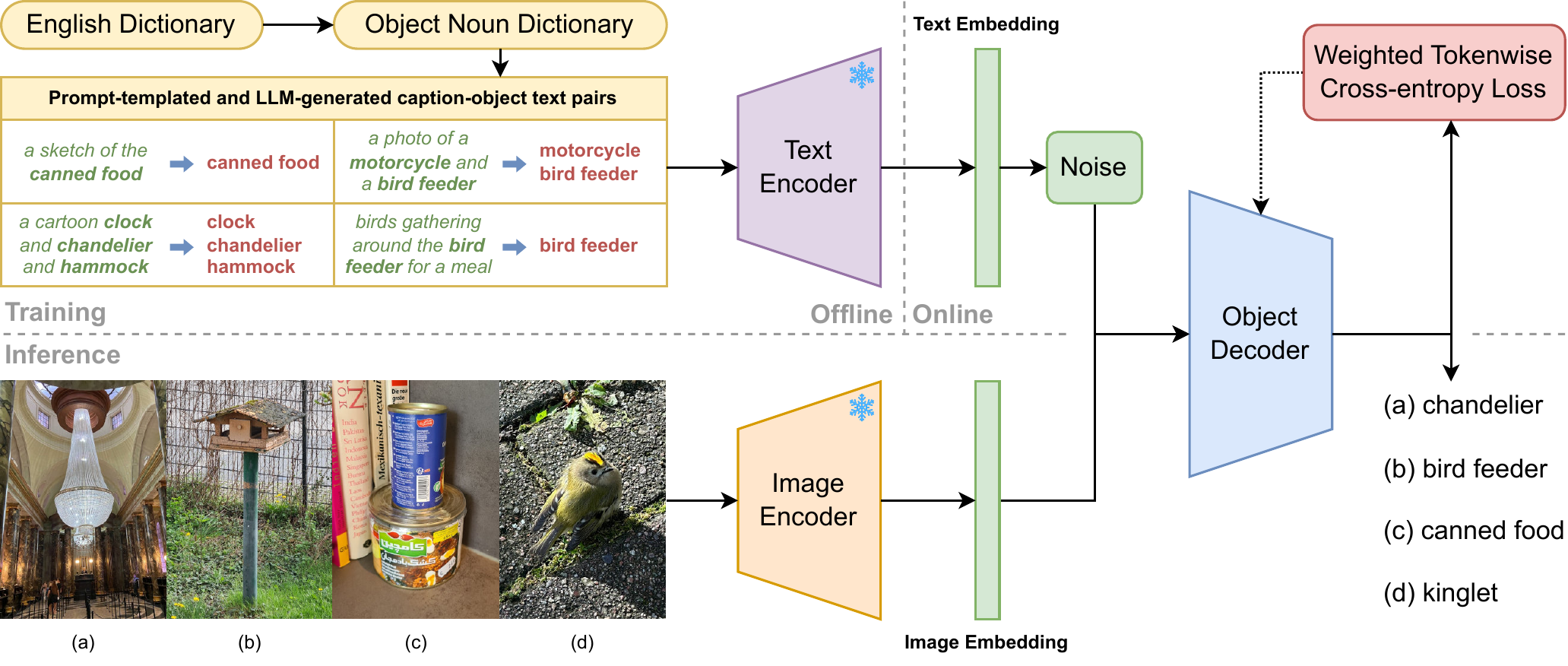
This is the code release corresponding to the WACV 2025 paper "Unconstrained Open Vocabulary Image Classification: Zero-Shot Transfer from Text to Image via CLIP Inversion". Given an image and nothing else (i.e. no prompts or candidate labels), NOVIC can generate an accurate fine-grained textual classification label in real-time, with coverage of the vast majority of the English language. Check out the Live Demo!
Source Code:
https://github.com/pallgeuer/novic
Contact:
Philipp Allgeuer, Kyra Ahrens, Stefan Wermter
Reference:
Philipp Allgeuer, Kyra Ahrens, Stefan Wermter (2025). Unconstrained Open Vocabulary Image Classification: Zero-Shot Transfer from Text to Image via CLIP Inversion. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV 2025).
Open access CVF WACV 2025 Paper
https://arxiv.org/abs/2407.11211
When Robots Get Chatty

This is the code release corresponding to the paper "When Robots Get Chatty: Grounding Multimodal Human-Robot Conversation and Collaboration". The NICOL robot is equipped with human-like social and cognitive competencies, for the purpose of open-ended human-robot conversation and collaboration. A modular and extensible methodology for grounding an LLM with the sensory perceptions and capabilities of a physical robot is implemented, and multiple deep learning models are integrated throughout the architecture.
Source Code:
https://github.com/pallgeuer/chatty_robots
Contact:
Philipp Allgeuer, Hassan Ali, Stefan Wermter
Reference:
Philipp Allgeuer, Hassan Ali, Stefan Wermter (2024). When Robots Get Chatty: Grounding Multimodal Human-Robot Conversation and Collaboration. In: Proceedings of the 33rd International Conference on Artificial Neural Networks (ICANN 2024), Best Paper Award.
https://link.springer.com/chapter/10.1007/978-3-031-72341-4_21
https://arxiv.org/abs/2407.00518
Agentic Skill Discovery
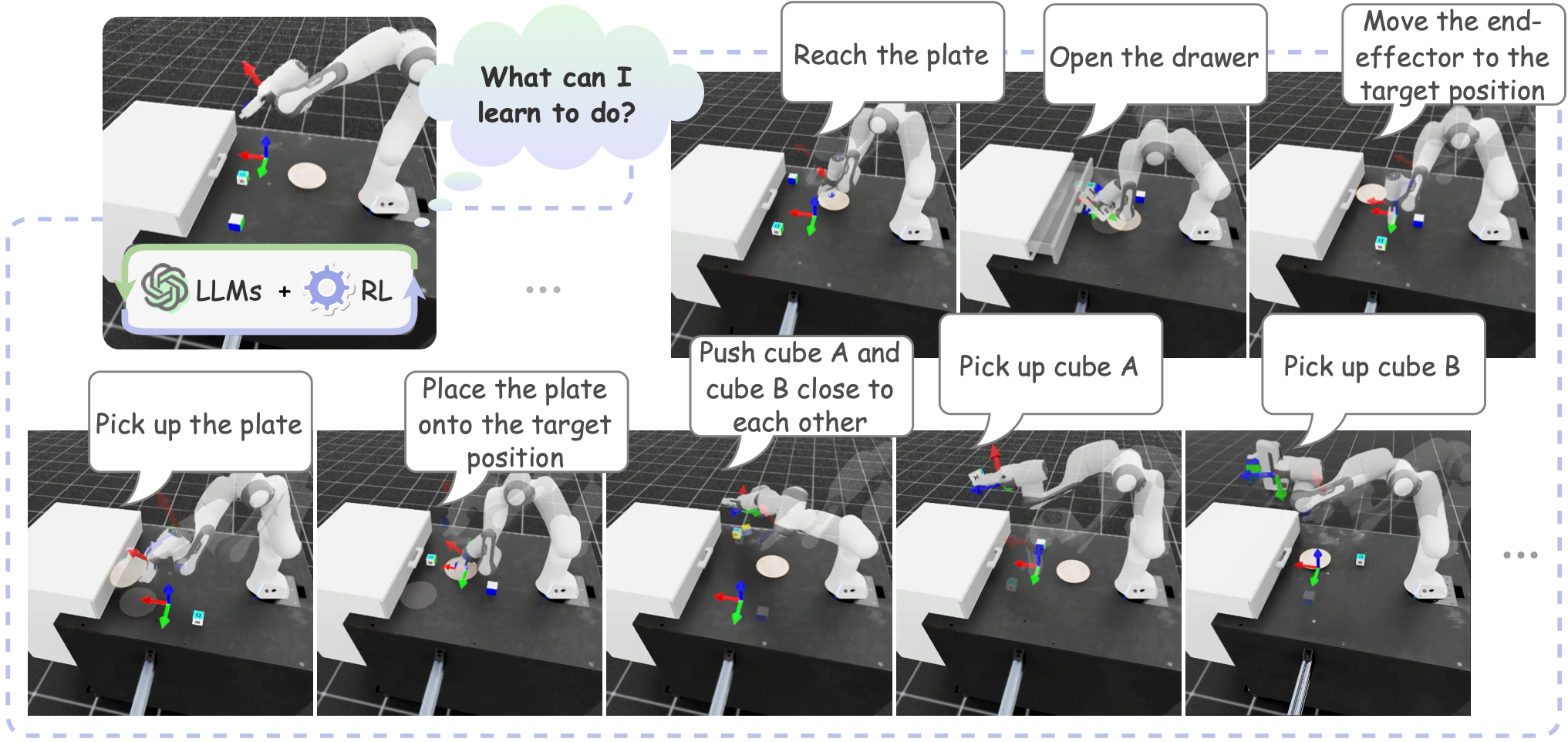
This is the source code (Python/IsaacSim) of agentic skill discovery, a framework driven by LLMs to generate task proposals based on the scene description and the robot's configurations. For each task, reinforcement learning processes develop the necessary policies, guided by LLM-derived success and reward functions. An independent vision-language model ensures the reliability of learned behaviors.
Source Code:
https://github.com/xf-zhao/Agentic-Skill-Discovery
Contact:
Xufeng Zhao, Cornelius Weber, Stefan Wermter
Reference:
Zhao, Xufeng, Cornelius Weber, Stefan Wermter (2024) Agentic Skill Discovery. https://arxiv.org/abs/2405.15019
CrossT5
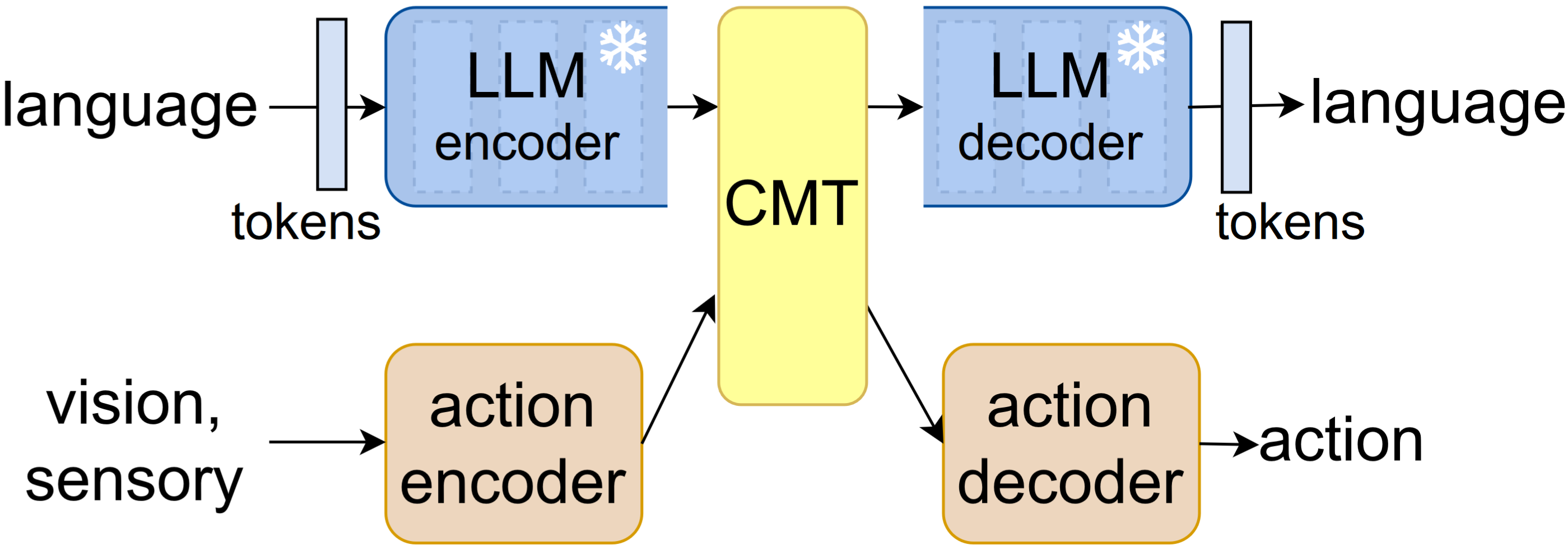
This is the source code (Python/PyTorch) for the paper "Enabling action crossmodality for a pretrained large language model". The CrossT5 model is distinct in that it splits up a pretrained T5 language model between its encoder and decoder parts, to enable efficient crossmodal integration allowing a lean implementation of the vision-action loop. The github also describes the use of the involved CLANT dataset.
Source Code:
https://github.com/samsoneko/CrossT5
Contact:
Ozan Özdemir, Cornelius Weber, Stefan Wermter
Reference:
Anton Caesar, Ozan Özdemir, Cornelius Weber, Stefan Wermter (2024) Enabling action crossmodality for a pretrained large language model. Natural Language Processing Journal, Volume 7, pages 100072. http://dx.doi.org/10.1016/j.nlp.2024.100072
Wrapyfi: A Python Wrapper for Integrating Robots, Sensors, and Applications across Multiple Middleware
Message oriented and robotics middleware play an important role in facilitating robot control, abstracting complex functionality, and unifying communication patterns between sensors and devices. However, using multiple middleware frameworks presents a challenge in integrating different robots within a single system. To address this challenge, we present Wrapyfi, a Python wrapper supporting multiple message oriented and robotics middleware, including ZeroMQ, YARP, ROS, and ROS 2. Wrapyfi also provides plugins for exchanging deep learning framework data, without additional encoding or preprocessing steps. Using Wrapyfi eases the development of scripts that run on multiple machines, thereby enabling cross-platform communication and workload distribution. We finally present the three communication schemes that form the cornerstone of Wrapyfi's communication model, along with examples that demonstrate their applicability.
Cite our paper if you find our code useful to your research (Reference below)
Source Code:
https://github.com/fabawi/wrapyfi
Documentation:
https://wrapyfi.readthedocs.io
[Tutorials] [Examples] [Communication Schemes]
Contact:
Reference:
Abawi, F., Allgeuer, P., Fu, D., & Wermter, S. (2024). Wrapyfi: A Python Wrapper for Integrating Robots, Sensors, and Applications across Multiple Middleware. In Proceedings of the 2024 ACM/IEEE International Conference on Human-Robot Interaction (HRI '24).
![]()
![]()
Internally Rewarded Reinforcement Learning
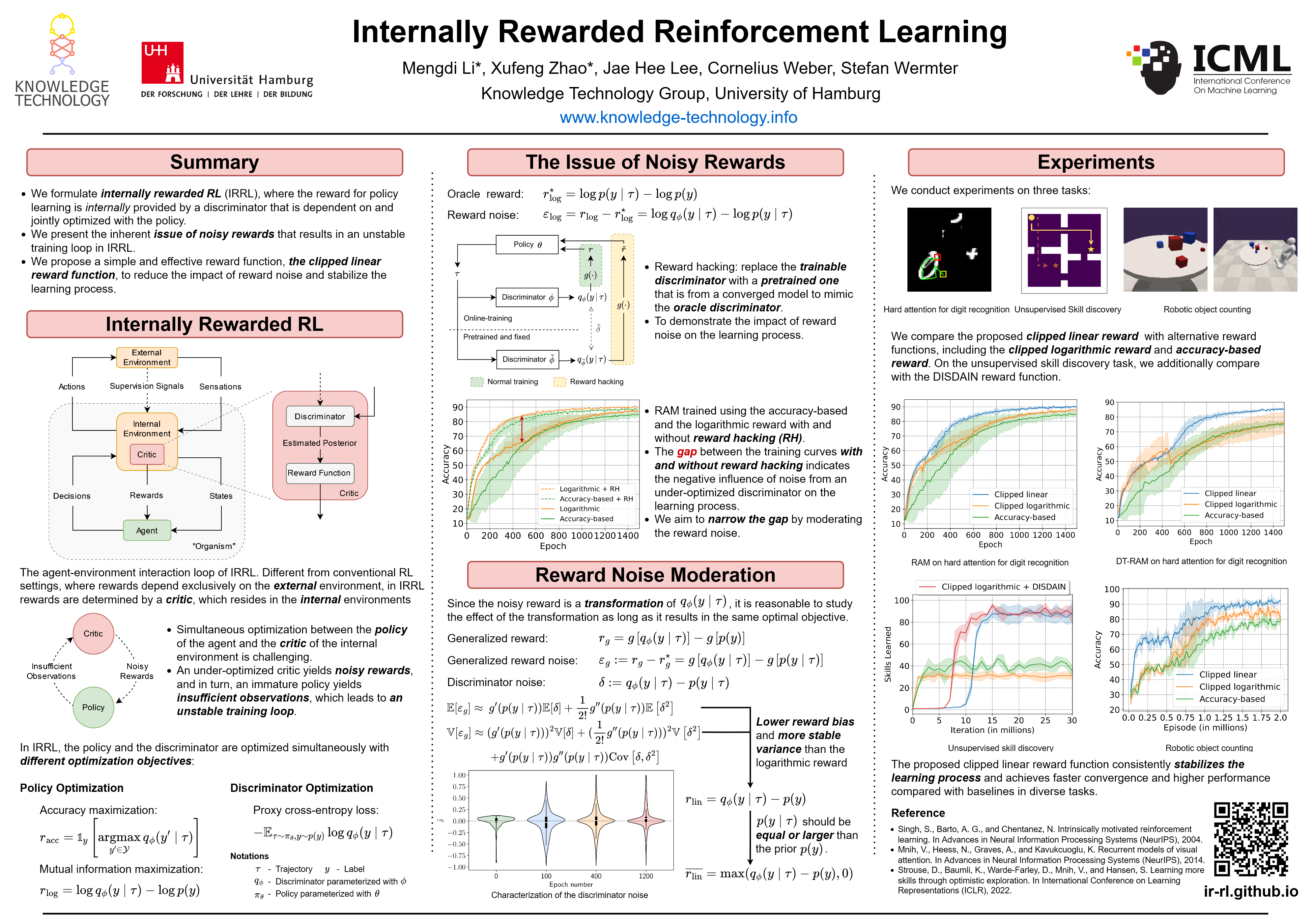
We study a class of reinforcement learning problems where the reward signals for policy learning are generated by a discriminator that is dependent on and jointly optimized with the policy. This interdependence between the policy and the discriminator leads to an unstable learning process because reward signals from an immature discriminator are noisy and impede policy learning, and conversely, an untrained policy impedes discriminator learning. We call this learning setting Internally Rewarded Reinforcement Learning (IRRL) as the reward is not provided directly by the environment but internally by the discriminator. In this paper, we formally formulate IRRL and present a class of problems that belong to IRRL. We theoretically derive and empirically analyze the effect of the reward function in IRRL and based on these analyses propose the clipped linear reward function. Experimental results show that the proposed reward function can consistently stabilize the training process by reducing the impact of reward noise, which leads to faster convergence and higher performance compared with baselines in diverse tasks.
Our GitHub project page contains Code and ICML 2023 paper "Internally Rewarded Reinforcement Learning"
Project Page:
Contact:
Mengdi Li, Xufeng Zhao, Jae Hee Lee, Cornelius Weber, Stefan Wermter
Reference:
Li, M., Zhao, X., Lee, J. H., Weber, C., & Wermter, S. (2023). Internally Rewarded Reinforcement Learning. arXiv preprint, arXiv:2302.00270. ![]()
ICML 2023 poster ![]()
Behavior Self-Organization Supports Task Inference for Continual Robot Learning
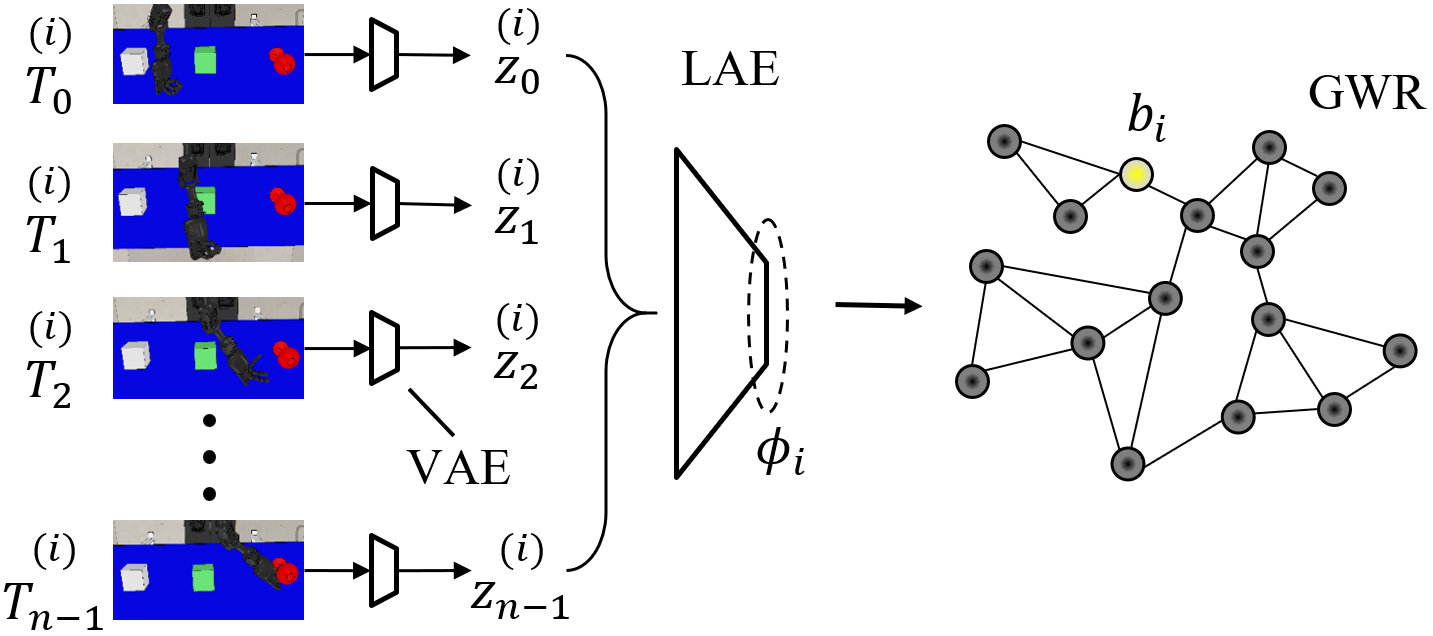
Recent advances in robot learning have enabled robots to become increasingly better at mastering a predefined set of tasks. On the other hand, as humans, we have the ability to learn a growing set of tasks over our lifetime. Continual robot learning is an emerging research direction with the goal of endowing robots with this ability. In order to learn new tasks over time, the robot first needs to infer the task at hand. Task inference, however, has received little attention in the multi-task learning literature. In this paper, we propose a novel approach to continual learning of robotic control tasks. Our approach performs unsupervised learning of behavior embeddings by incrementally self-organizing demonstrated behaviors. Task inference is made by finding the nearest behavior embedding to a demonstrated behavior, which is used together with the environment state as input to a multi-task policy trained with reinforcement learning to optimize performance over tasks. Unlike previous approaches, our approach makes no assumptions about task distribution and requires no task exploration to infer tasks. We evaluate our approach in experiments with concurrently and sequentially presented tasks and show that it outperforms other multi-task learning approaches in terms of generalization performance and convergence speed, particularly in the continual learning setting.
The repository below contains Python implementation for the Behavior-Guided Policy Optimization (BGPO) algorithm proposed in [Hafez and Wermter, 2021].
Source Code:
https://github.com/knowledgetechnologyuhh/Imagination-Arbitration
Contact:
References
Hafez, M. B. & Wermter, S. (2021). Behavior Self-Organization Supports Task Inference for Continual Robot Learning. Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), (to appear) 
Efficient Facial Feature Learning with Wide Ensemble-Based Convolutional Neural Networks
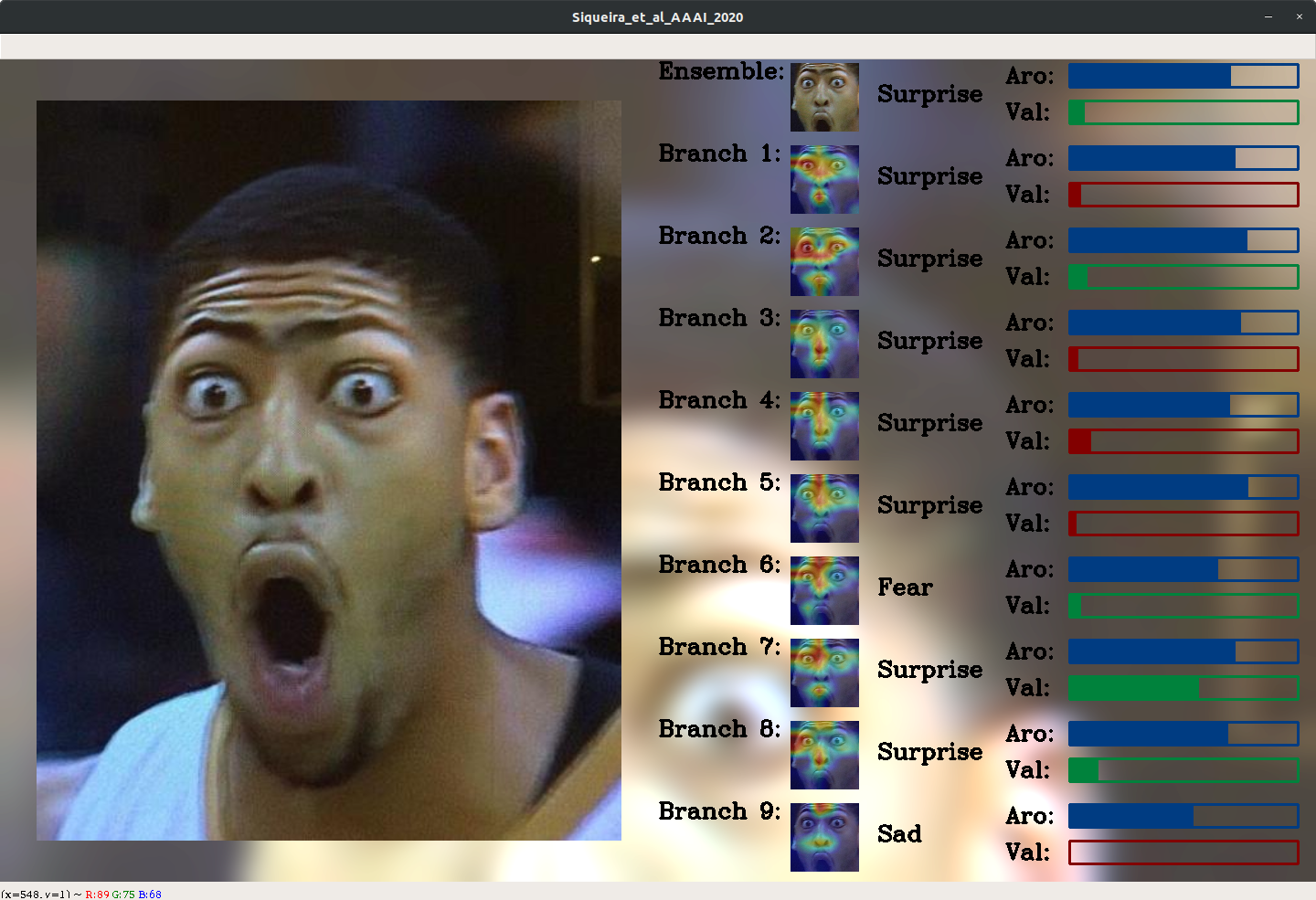
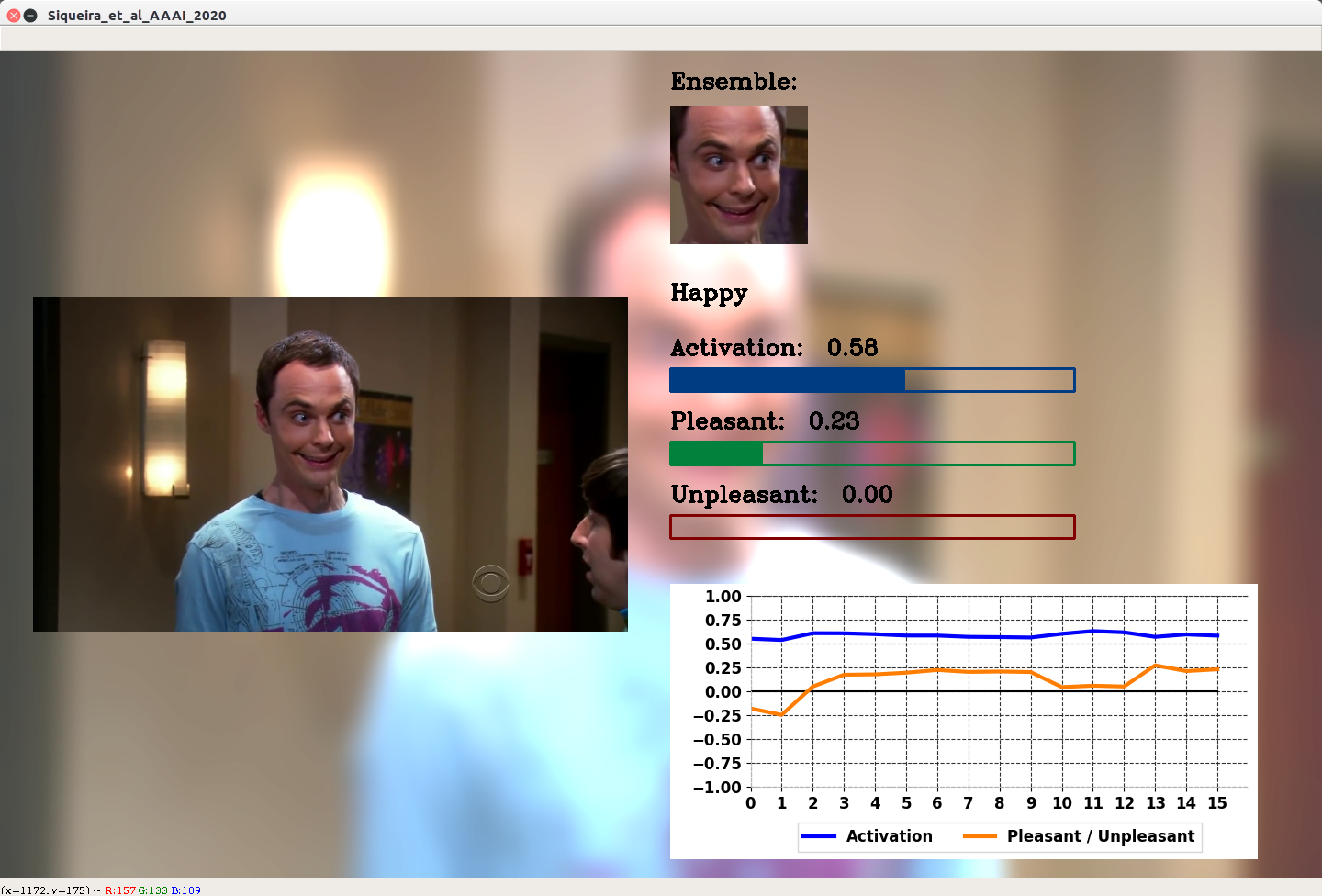
“We get resourcefulness from having many resources; not from having one very smart one” (Minsky 2014).
Ensemble methods, traditionally built with independently trained de-correlated models, have proven to be efficient methods for reducing the remaining residual generalization error, which results in robust and accurate methods for real-world applications. In the context of deep learning, however, training an ensemble of deep networks is costly and generates high redundancy which is inefficient.
In this paper, we present experiments on Ensembles with Shared Representations (ESRs) based on convolutional networks to demonstrate, quantitatively and qualitatively, their data processing efficiency and scalability to large-scale datasets of facial expressions. We show that redundancy and computational load can be dramatically reduced by varying the branching level of the ESR without loss of diversity and generalization power, which are both important for ensemble performance. Experiments on large-scale datasets suggest that ESRs reduce the remaining residual generalization error on the AffectNet and FER+ datasets, reach human-level performance, and outperform state-of-the-art methods on facial expression recognition in the wild using emotion and affect concepts.
Our GitHub repository contains:
- Facial expression recognition framework.
- Introduction to Ensembles with Shared Representations.
- Implementation of an Ensemble with Shared Representations in PyTorch.
- Scripts of experiments conducted for the AAAI-2020 conference.
- Our AAAI-2020 paper.
- Our AAAI-2020 poster.
Source Code:
Contact:
Henrique Da Costa Siqueira, Stefan Wermter
Reference:
Siqueira, H., Magg, S. & Wermter, S. (2020). Efficient Facial Feature Learning with Wide Ensemble-Based Convolutional Neural Networks. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI-20). ![]()
AAAI-2020 poster. ![]()
Robotic Occlusion Reasoning for Efficient Object Existence Prediction
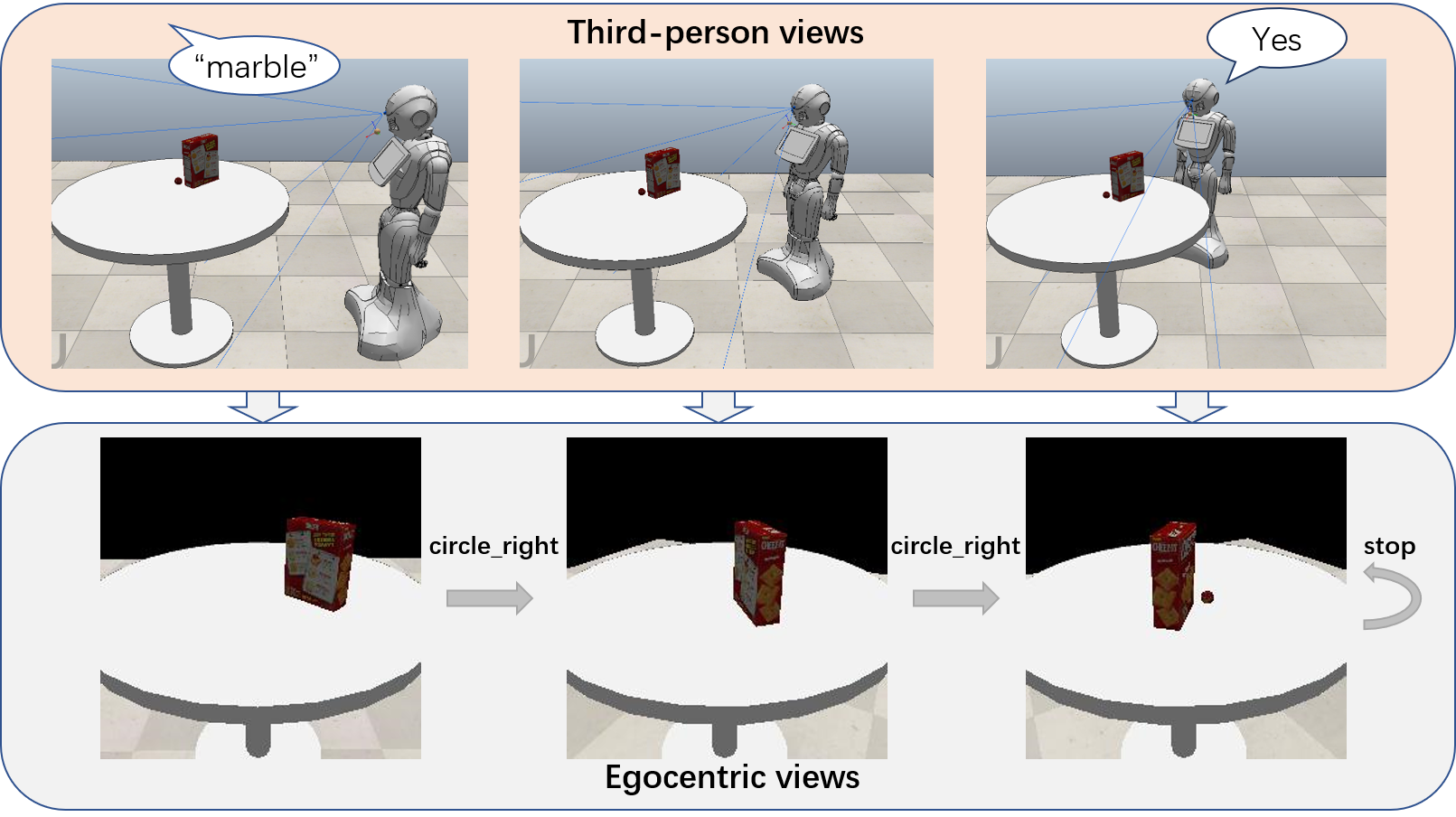
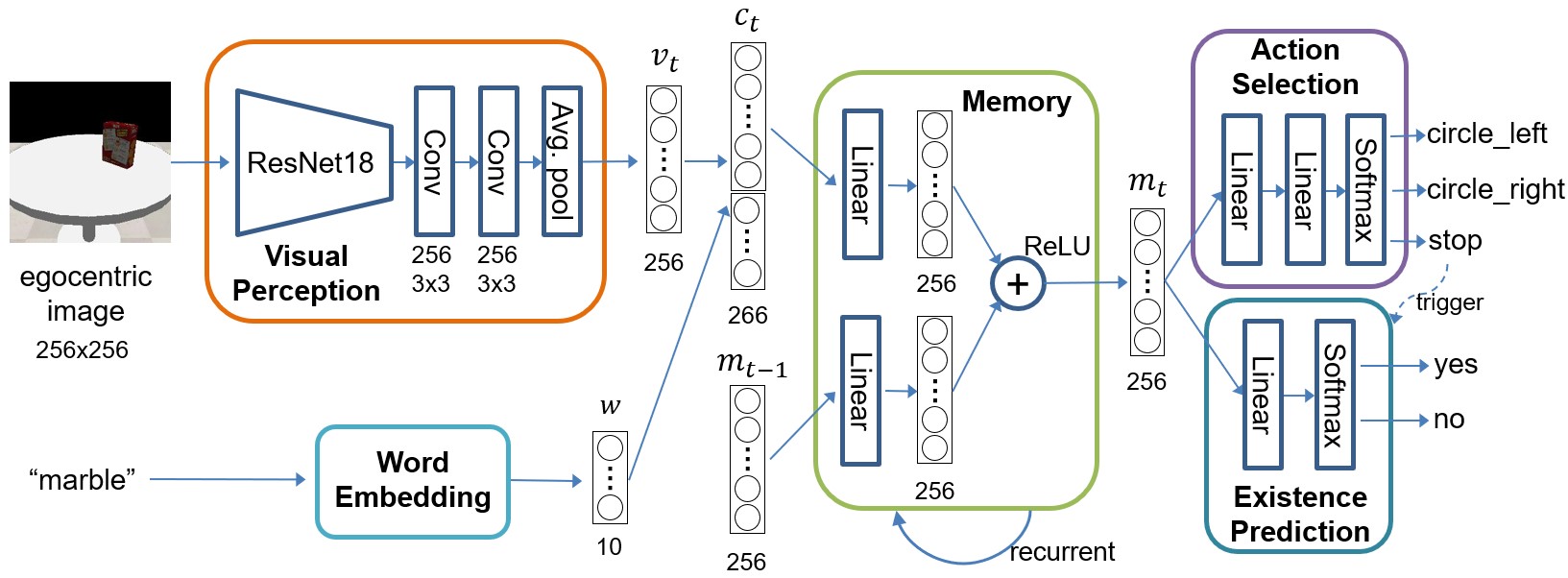
Pytorch implementation for reproducing the results from the paper "Robotic Occlusion Reasoning for Efficient Object Existence Prediction" by Mengdi Li, Cornelius Weber, Matthias Kerzel, Jae Hee Lee, Zheni Zeng, Zhiyuan Liu, Stefan Wermter.
Source Code:
https://github.com/mengdi-li/robotic-occlusion-reasoning
Contact:
Reference:
Li, M., Weber, C., Kerzel, M., Lee, J. H., Zeng, Z., Liu, Z., & Wermter, S. (2021). Robotic Occlusion Reasoning for Efficient Object Existence Prediction. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). ![]()
GASP: Gated Attention for Saliency Prediction
Saliency prediction refers to the computational task of modeling overt attention. Social cues greatly influence our attention, consequently altering our eye movements and behavior.
To emphasize the efficacy of such features, we present a neural model for integrating social cues and weighting their influences. Our model consists of two stages. During the first stage, we detect two social cues by following gaze, estimating gaze direction, and recognizing affect. These features are then transformed into spatiotemporal maps through image processing operations. The transformed representations are propagated to the second stage (GASP) where we explore various techniques of late fusion for integrating social cues and introduce two sub-networks for directing attention to relevant stimuli. Our experiments indicate that fusion approaches achieve better results for static integration methods, whereas non-fusion approaches for which the influence of each modality is unknown, result in better outcomes when coupled with recurrent models for dynamic saliency prediction. We show that gaze direction and affective representations contribute a prediction to ground-truth correspondence improvement of at least 5% compared to dynamic saliency models without social cues. Furthermore, affective representations improve GASP, supporting the necessity of considering affect-biased attention in predicting saliency.
Cite our paper if you find our models or code useful to your research (Reference below)
The repository below provides a Pytorch implementation of our GASP model
Source Code:
https://github.com/knowledgetechnologyuhh/gasp
Contact:
Fares Abawi, Tom Weber, Stefan Wermter
Reference:
Abawi, F., Weber, T., & Wermter, S. (2021). GASP: Gated Attention for Saliency Prediction. In Proceedings of the Thirtieth International Joint Conferences on Artificial Intelligence (IJCAI-21), pp. 584-591.
![]()
![]()
Lifelong Learning from Event-based Data

Lifelong learning is a long-standing aim for artificial agents that act in dynamic environments, in which an agent needs to accumulate knowledge incrementally without forgetting previously learned representations. We investigate methods for learning from data produced by event cameras and compare techniques to mitigate forgetting while learning incrementally. We propose a model that is composed of both, feature extraction and continuous learning. Furthermore, we introduce a habituation-based method to mitigate forgetting. Our experimental results show that the combination of different techniques can help to avoid catastrophic forgetting while learning incrementally from the features provided by the extraction module.
Source Code:
https://github.com/VadymV/events_lifelong_learning
Contact:
Vadym Gryshchuk(vadym.gryshchuk"AT"protonmail.com), Cornelius Weber Chu Kiong Loo Stefan Wermter
Reference:
Gryshchuk, V., Weber, C., Loo, C.K., & Wermter, S. (2021). Lifelong Learning from Event-based Data. In the 29th European Symposium on Artificial Neural Networks (accepted).
WoZ4U: An Open Source Wizard-of-Oz Interface for the Pepper robot
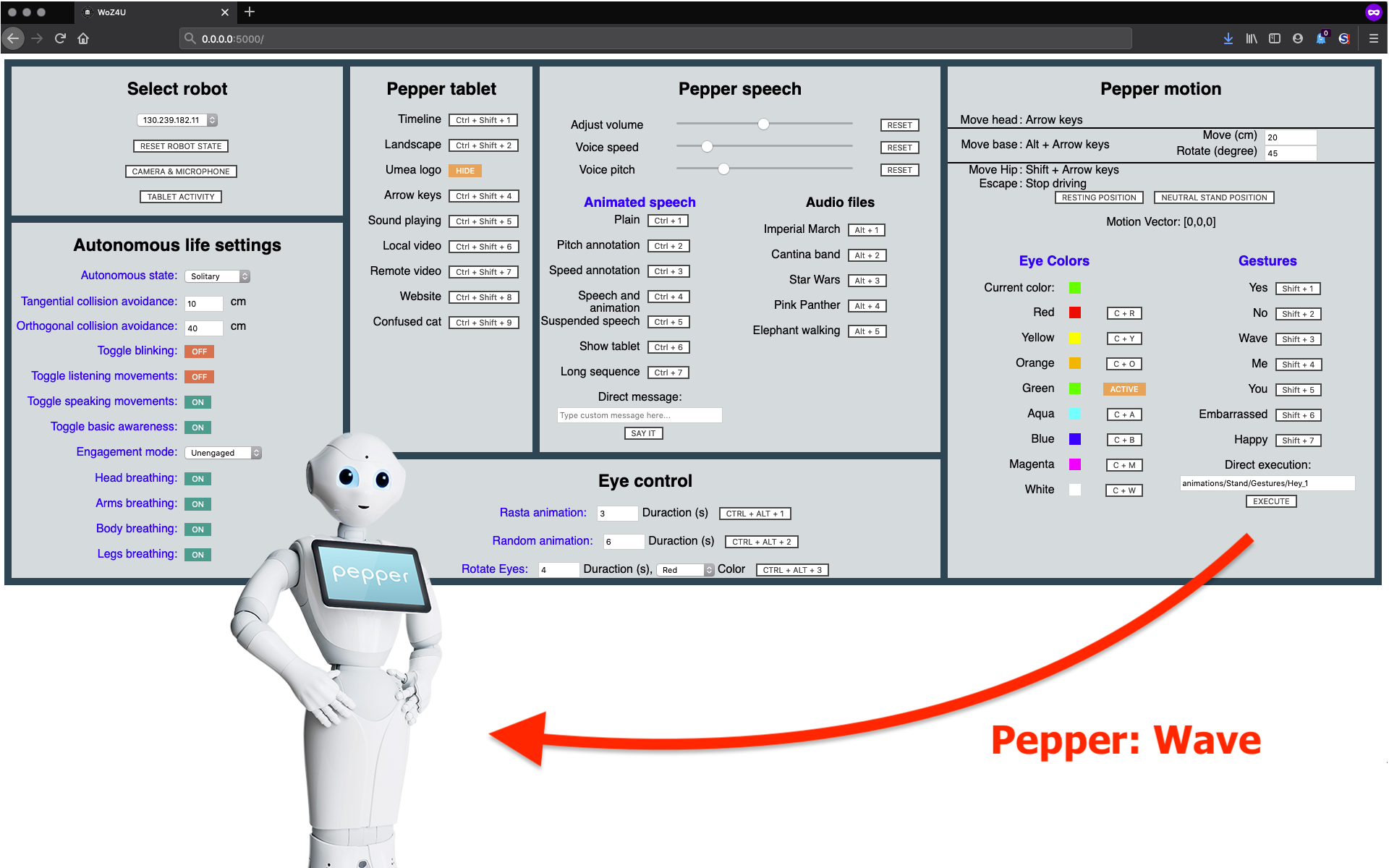
We present WoZ4U, a fully configurable interface for Wizard-of-Oz experiments with Pepper robots. WoZ4U offers control over a large part of the Pepper's functionality, with a special focus on functionality crucial for Human-Robot Interaction experiments. The main supported features are: full control over Pepper's autonomy settings, gesture control, animated text to speech, monitoring and control over Pepper's tablet, real-time monitoring and recording of Pepper's cameras and microphones, a simple navigation controller, and LED control.
All context or experiment specific elements, e.g. which spoken messages, gestures, or tablet items are accessible via the interface and which keyboard shortcuts are assigned, are configurable via a text (YAML) file, thereby reducing the work for setting up an experiment, from programming a dedicated control system for Pepper, to editing items in a configuration file.
The server-based software architecture is robot independent and can be adapted for other robotic platforms.
Source Code:
https://github.com/frietz58/WoZ4U
Contact:
Finn Rietz(finn.rietz"AT"uni-hamburg.de), Stefan Wermter
Citation:
@article{rietz20woz4u,
author = {Finn Rietz, Alexander Sutherland, Suna Bensch, Stefan Wermter, and Thomas Hellström},
title = {WoZ4U: An Open-Source Wizard-of-Oz Interface for Easy, Efficient and Robust HRI Experiments} ,
journal = {Frontiers in Robotics and AI},
year = {2021},
volume = {8},
pages = {213},
url = {https://www.frontiersin.org/article/10.3389/frobt.2021.668057},
doi = {10.3389/frobt.2021.668057}
}
Genetic Algorithm Inverse Kinmatics Solver (gaikpy)
gaikpy
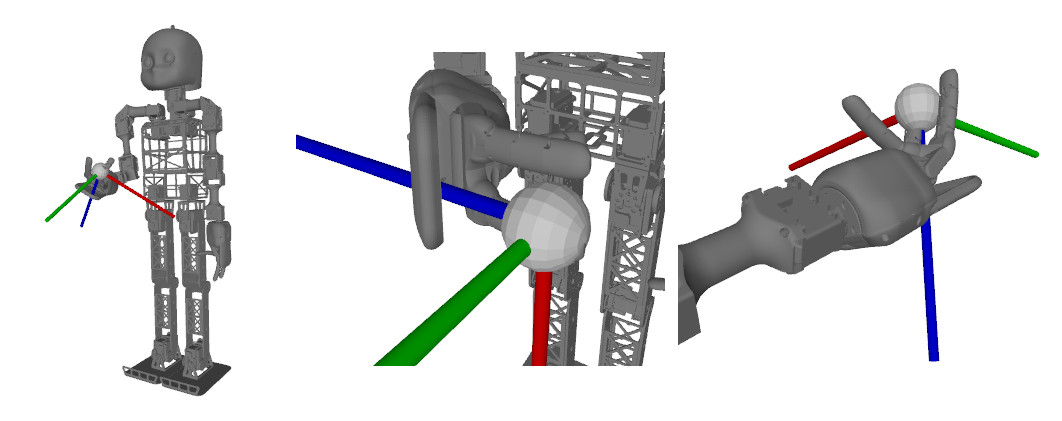
gaikpy is a pure python approach to solve the inverse kinematics for every URDF modelled robot.
gaikpy solves the inverse kinematics for every URDF based robot model using a genetic algorithm approach. No pretraining is needed. gaikpy is completely realised in python. gaikpy has already integrated the NICO robot, but can easily be adapted to other robot using a URDF model.
Source Code:
https://github.com/knowledgetechnologyuhh/gaikpy
Contact:
References:
Neuro-Genetic Visuomotor Architecture for Robotic Grasping
Matthias Kerzel, Josua Spisak, Erik Strahl, Stefan Wermter Artificial Neural Networks and Machine Learning – ICANN 2020, pages 533-545 - 2020.
Improving Robot Dual-System Motor Learning with Intrinsically Motivated Meta-Control and Latent-Space Experience Imagination (2020)
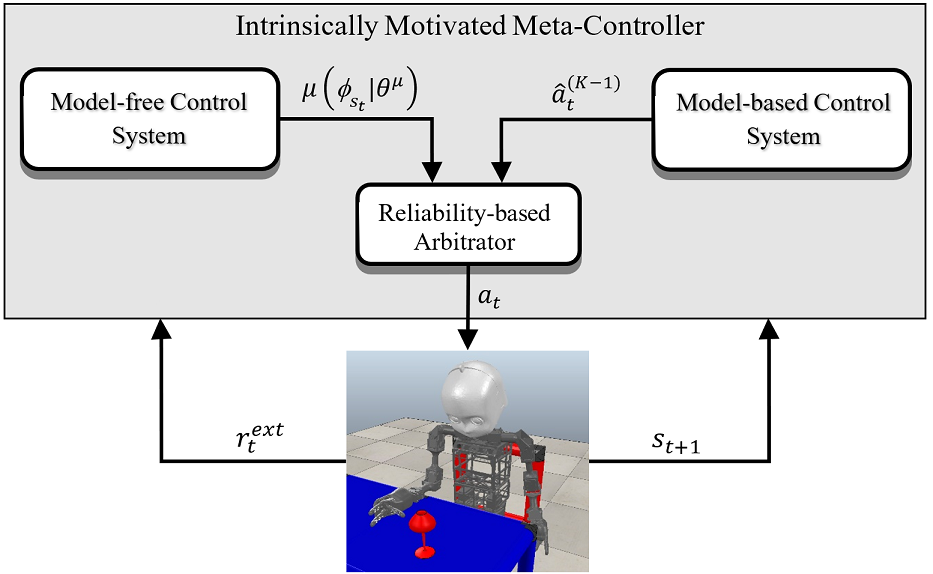
Combining model-based and model-free learning systems has been shown to improve the sample efficiency of learning to perform complex robotic tasks. However, dual-system approaches fail to consider the reliability of the learned model when it is applied to make multiple-step predictions, resulting in a compounding of prediction errors and performance degradation. In this paper, we present a novel dual-system motor learning approach where a meta-controller arbitrates online between model-based and model-free decisions based on an estimate of the local reliability of the learned model. The reliability estimate is used in computing an intrinsic feedback signal, encouraging actions that lead to data that improves the model. Our approach also integrates arbitration with imagination where a learned latent-space model generates imagined experiences, based on its local reliability, to be used as additional training data. We evaluate our approach against baseline and state-of-the-art methods on learning vision-based robotic grasping in simulation and real world. The results show that our approach outperforms the compared methods and learns near-optimal grasping policies in dense-and sparse-reward environments.
The repository below contains Python implementation for the Intrinsically Motivated Meta-Controller (IM2C) algorithm and Integrated Imagination-Arbitration (I2A) learning framework proposed in [Hafez et al., 2020].
Source Code:
https://github.com/knowledgetechnologyuhh/Imagination-Arbitration
Contact:
References
M. B. Hafez, C. Weber, M. Kerzel, and S. Wermter. Improving Robot Dual-System Motor Learning with Intrinsically Motivated Meta-Control and Latent-Space Experience Imagination. Robotics and Autonomous Systems, 133 (2020): 103630.
Enhancing a Neurocognitive Shared Visuomotor Model for Object Identification, Localization, and Grasping With Learning From Auxiliary Tasks
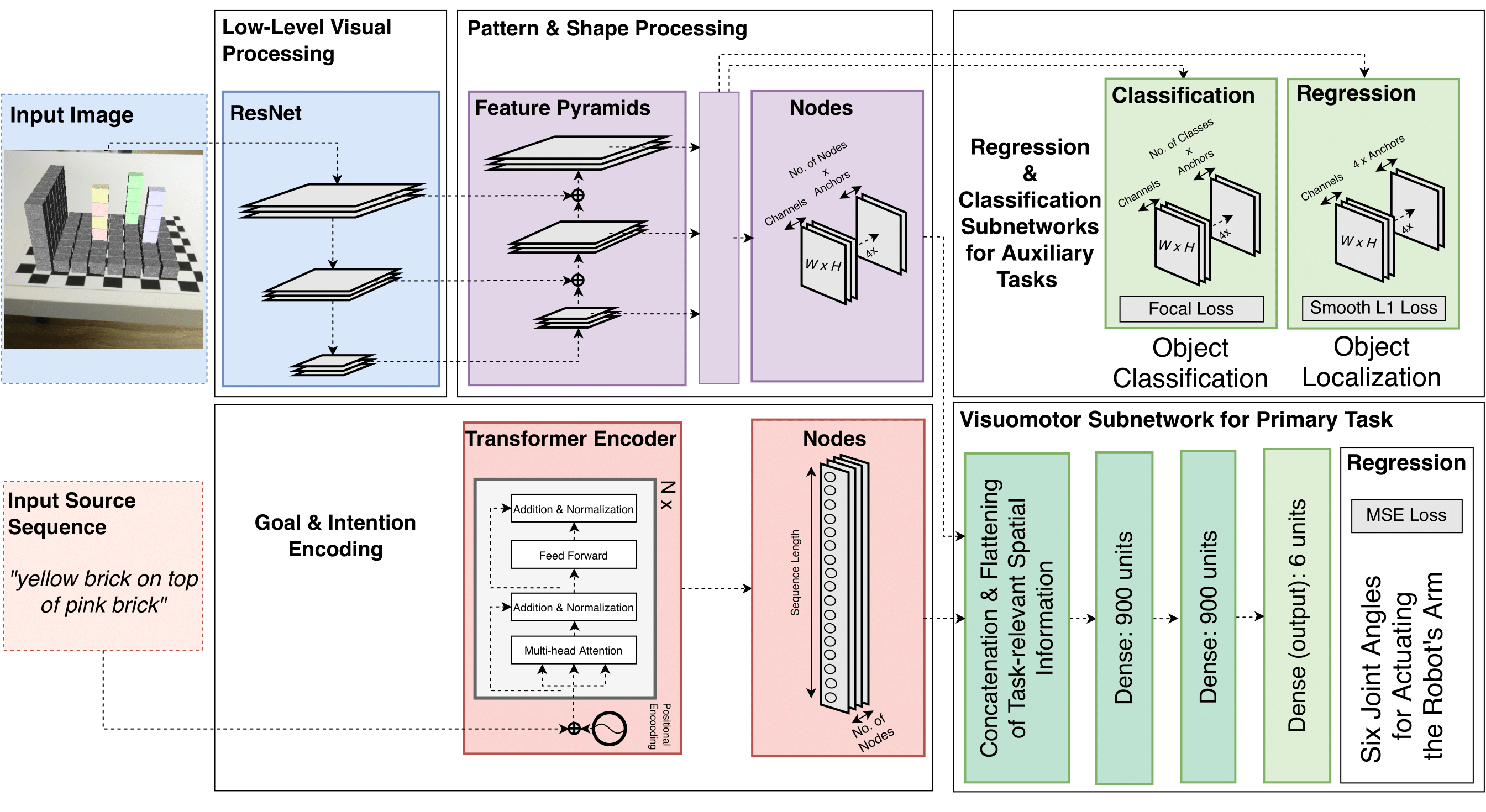
We present a biologically inspired neural model for the robotic tasks of object identification, localization, and motor action regression. The model is designed for: 1) Enabling a robot to reach objects in a three-dimensional space as this is a required ability for many real-world robotic applications; 2) Addressing the influence of imbalances in the training data on possible biases in the model’s behavior; 3) Evaluating the model’s performance on the auxiliary tasks of object localization and identification. We examine the effect of training these auxiliary tasks, along with the main task of reaching for an object, to gain a better understanding of the model’s performance and observe possible synergetic effects of learning the three tasks simultaneously.
Cite our paper if you find our models or code useful to your research (Reference below)
The repository below provides a Keras implementation of our multitask-learning model
Source Code:
https://github.com/knowledgetechnologyuhh/augmented_grasping_3d
Dataset:
https://www.inf.uni-hamburg.de/en/inst/ab/wtm/research/corpora.html#augmented_extended_train_robots
Contact:
Reference:
Kerzel, M., Abawi, F., Eppe, M., & Wermter, S. (2020). Enhancing a Neurocognitive Shared Visuomotor Model for Object Identification, Localization, and Grasping With Learning From Auxiliary Tasks. In IEEE Transactions on Cognitive and Developmental Systems (TCDS).
![]()
Goal-conditioned deep Reinforcement Learning baselines

Pytorch and tensorflow implementations for reproducing the results from the papers
- Röder*, F., Eppe*, M., Nguyen, P. D. H., & Wermter, S. (* equal contribution) Curious Hierarchical Actor-Critic Reinforcement Learning. International Conference on Artificial Neural Networks (ICANN - in Review). http://arxiv.org/abs/2005.03420
- Eppe, M., Nguyen, P. D. H., & Wermter, S. (2019). From Semantics to Execution: Integrating Action Planning with Reinforcement Learning for Robotic Causal Problem-solving. Frontiers in Robotics and AI, 6, online. https://doi.org/10.3389/frobt.2019.00123
- Eppe, M., Magg, S., & Wermter, S. (2019). Curriculum Goal Masking for Continuous Deep Reinforcement Learning. International Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob), 183–188.
Software
https://github.com/knowledgetechnologyuhh/goal_conditioned_RL_baselines
Acknowledgement
Code for is adapted from OpenAI baselines and OpenAI gym
Generating Multiple Objects at Spatially Distinct Locations
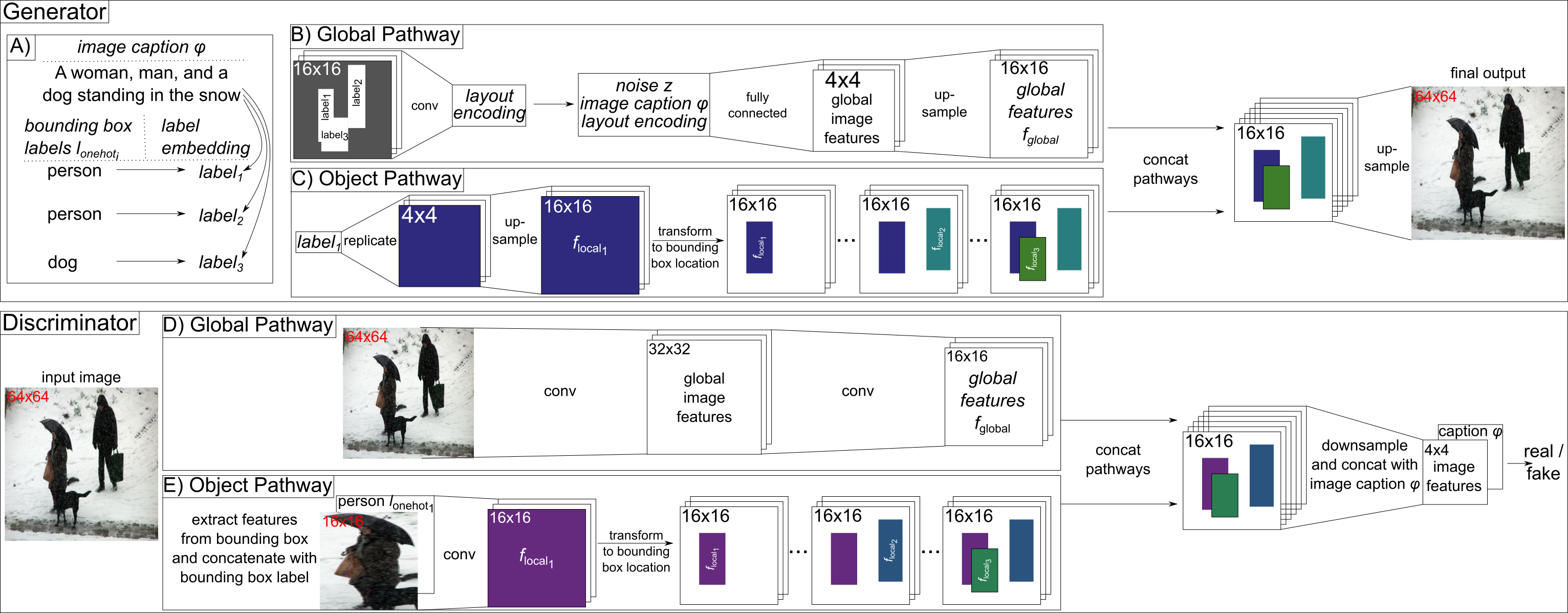
Pytorch implementation for reproducing the results from the paper Generating Multiple Objects at Spatially Distinct Locations by Tobias Hinz, Stefan Heinrich, and Stefan Wermter accepted for publication at the International Conference on Learning Representations 2019.
Software
https://github.com/tohinz/multiple-objects-gan
Data
- Multi-MNIST:
- contains the three data sets used in the paper: normal (three digits per image), split_digits (0-4 in top half of image, 5-9 in bottom half), and bottom_half_empty (no digits in bottom half of the image)
- download our data, save it to data/ and extract
- CLEVR:
- MS-COCO:
- download our preprocessed data (bounding boxes and bounding box labels) and save them in data/coco/train/ and data/coco/test/
- obtain the train and validation images from the 2014 split here, extract and save them in data/MS-COCO/train/ and data/MS-COCO/test/
- for the StackGAN architecture: obtain the preprocessed char-CNN-RNN text embeddings from here and put the files in data/MS-COCO/train/ and data/MS-COCO/test/
- for the AttnGAN architecture: obtain the preprocessed metadata and the pre-trained DAMSM model from here
- extract the preprocessed metadata, then add the files downloaded in the first step (bounding boxes and bounding box labels) to the data/coco/coco/train/ and data/coco/coco/test/ folder
- put the downloaded DAMSM model into code/coco/attngan/DAMSMencoders/ and extract
Pretrained Models
- pretrained model for Multi-MNIST: download, save to models and extract
- pretrained model for CLEVR: download, save to models and extract
- pretrained model for MS-COCO:
Acknowledgement
Code for the experiments on Multi-MNIST and CLEVR data sets is adapted from StackGAN-Pytorch.
Code for the experiments on MS-COCO with the StackGAN architecture is adapted from StackGAN-Pytorch, while the code with the AttnGAN architecture is adapted from AttnGAN.
Citing
If you find our model useful in your research please consider citing:
@inproceedings{Hinz19generating,
Author = {Tobias Hinz, Stefan Heinrich, Stefan Wermter},
Title = {Generating Multiple Objects at Spatially Distinct Locations},
Year = {2019},
booktitle = {{ICLR}}
}
Localizing salient body motion in multi-person scenes using convolutional neural networks

Python implementation for the paper Localizing salient body motion in multi-person scenes using convolutional neural networks by Florian Letsch, Doreen Jirak and Stefan Wermter. The publication is available here.
Understanding complex scenes with multiple people still poses problems to current computer vision approaches. Experiments with application-specific motion, such as gesture recognition scenarios, are often constrained to single person scenes in the literature. Therefore, we conducted a study to address the challenging task of detecting salient body motion in scenes with more than one person. Our architecture consists of a 3D Convolutional Neural Network that receives a frame sequence as its input and localizes active gesture movement. The model can be trained end-to-end, thereby avoiding hand-crafted features and the strong reliance on pre-processing as it is prevalent in similar studies.
Code
Find the repository on Github:
https://github.com/florianletsch/publication-salient-body-motion
Data
In addition to the implementation of the neural network, we provide the corresponding dataset, consisting of single-person and multi-person Kinect frames.
The corpus is available at the WTM corpora listing.
Reference
Florian Letsch, Doreen Jirak and Stefan Wermter (2019). Localizing salient body motion in multi-person scenes using convolutional neural networks, Neurocomputing, Volume 330, Pages 449-464. 
Contact
Florian Letsch, Doreen Jirak, Stefan Wermter
Affective Memory Framework
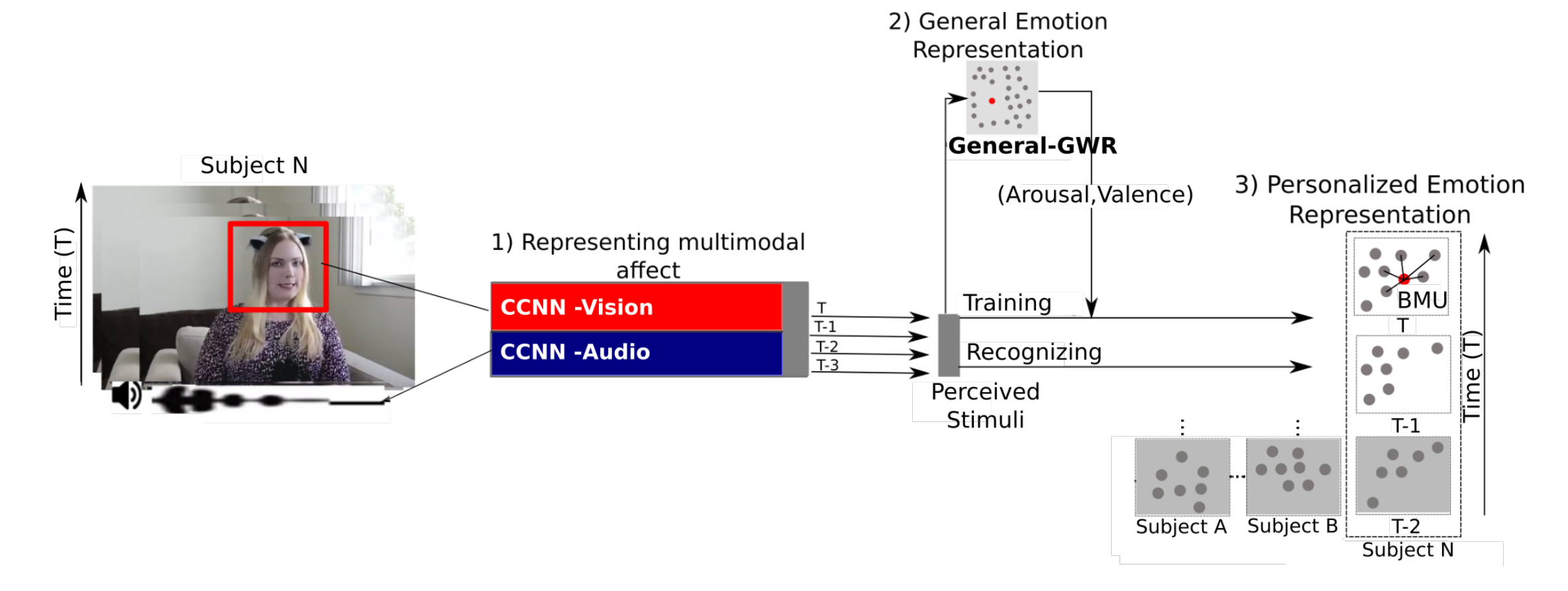
Recent emotion recognition models are rather successful in recognizing instantaneous emotional expressions. However, when applied to continuous interactions, they show a weaker adaptation to a person-specific and long-term emotion appraisal. In this paper, we present an unsupervised neural framework that improves emotion recognition by learning how to describe the continuous affective behavior of individual persons. Our framework is composed of three self-organizing mechanisms: (1) a recurrent growing layer to cluster general emotion expressions, (2) a set of associative layers, acting as affective memories to model specific emotional behavior of individuals, (3) and an online learning layer which provides contextual modeling of continuous expressions. We propose different learning strategies to integrate all three mechanisms and to improve the performance of arousal and valence recognition of the OMG-Emotion dataset. We evaluate our model with a series of experiments ranging from ablation studies assessing the different contributions of each neural component to an objective comparison with state-of-the-art solutions. The results from the evaluations show a good performance on emotion recognition of continuous emotions on monologue videos. Furthermore, we discuss how the model self-regulates the interplay between generalized and personalized emotion perception and how this influences the model's reliability when recognizing unseen emotion expressions.
Source Code:
https://github.com/pablovin/AffectiveMemoryFramework
Contact:
Reference
|
P. Barros, E. Barakova and S. Wermter, "Adapting the Interplay between Personalized and Generalized Affect Recognition based on an Unsupervised Neural Framework," in IEEE Transactions on Affective Computing, doi: 10.1109/TAFFC.2020.3002657. |
A Neurorobotic Experiment for Crossmodal Conflict Resolution in Complex Environments
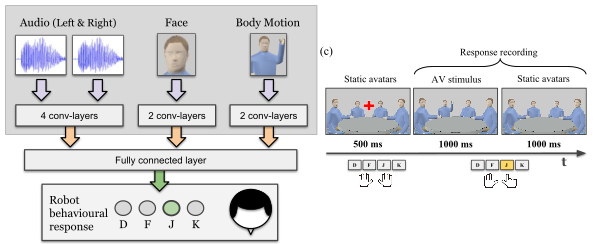
Crossmodal conflict resolution is a crucial component of robot sensorimotor coupling through interaction with the environment for swift and robust behavior also in noisy conditions. In this paper, we propose a neurorobotic experiment in which an iCub robot exhibits human-like responses in a complex crossmodal environment. To better understand how humans deal with multisensory conflicts, we conducted a behavioral study exposing 33 subjects to congruent and incongruent dynamic audio-visual cues. In contrast to previous studies using simplified stimuli, we designed a scenario with four animated avatars and observed that the magnitude and extension of the visual bias are related to the semantics embedded in the scene, i.e., visual cues that are congruent with environmental statistics (moving lips and vocalization) induce a stronger bias. We propose a deep learning model that processes stereophonic sound, facial features, and body motion to trigger a discrete response resembling the collected behavioral data. After training, we exposed the iCub to the same experimental conditions as the human subjects, showing that the robot can replicate similar responses in real time. Our interdisciplinary work provides important insights into how crossmodal conflict resolution can be modeled in robots and introduces future research directions for the efficient combination of the sensory drive with internally generated knowledge and expectations.
Source Code:
https://github.com/knowledgetechnologyuhh/CML_A5_Neurorobotic_IROS2018
License and more information:
https://www.inf.uni-hamburg.de/en/inst/ab/wtm/research/cml.html
Contact:
Pablo Barros, German I. Parisi, Stefan Wermter
Reference:
Parisi, G. I., Barros, P., Fu, D., Magg, S., Wu, H., Liu, X., Wermter, S. A Neurorobotic Experiment for Crossmodal Conflict Resolution in Complex Environments. Submitted to: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2018.
Discourse-Wizard: Dialogue Act Recognition Live Web-Demo
This is the Dialogue Act Recognition Live Web-Demo for dialogue act recognition where you can analyze the contextual information of utterances within the dialogue.
Demonstration uses recurrent neural network models in two setups at utterance-level: a non-context and a context-based model. The non-context model classifies dialogue acts at an utterance-level whereas the context-based model takes some preceding utterances into account. The live demo provides an easy to use interface for conversational analysis and for discovering deep discourse structures in a conversation. The details on concept and implementation are given in the paper (Bothe et al., 2018a). The further conversational analysis research work can be followed in (Bothe et al., 2018b; Bothe et al., 2018c).
You may also visit full website (https://crbothe.github.io/discourse-wizard) of the demonstration project for quick details.
References:
[Bothe et al., 2018a] Bothe, C., Magg, S., Weber, C., and Wermter, S. (2018) Discourse-Wizard: Discovering Deep Discourse Structure in your Conversation with RNNs. arXiv:1806.11420 [cs.CL] PDF
[Bothe et al., 2018b] Bothe, C., Magg, S., Weber, C., and Wermter, S. (2018) Conversational Analysis using Utterance-level Attention-based Bidirectional Recurrent Neural Networks. Proceedings of INTERSPEECH 2018. PDF
[Bothe et al., 2018c] Bothe, C., Weber, C., Magg, S., and Wermter, S. (2018) A Context-based Approach for Dialogue Act Recognition using Simple Recurrent Neural Networks. Proceedings of the Language Resources and Evaluation Conference (LREC 2018). Abstract PDF
Contact:
Grow-When-Required Networks
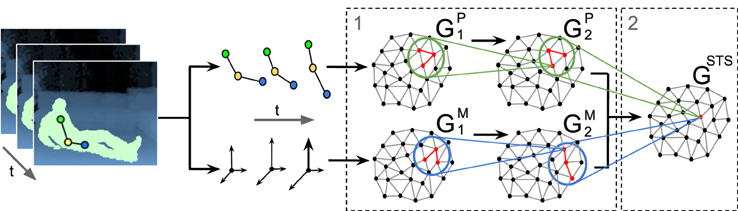
This repository contains 3 types of extensions of the Grow-When-Required (GWR) self-organizing neural network by Marsland et al. (2002):
https://github.com/knowledgetechnologyuhh/gwr_parisi
Use demo files for off-the-shelf functionalities such as: create, train, test, save, import, and plot networks.
- Associative GWR (AGWR; Parisi et al., 2015) - Standard GWR extended with associative labelling for learning label histograms for each neuron.
- GammaGWR (Parisi et al., 2017) - GWR neurons are equipped with a number of context descriptors for temporal processing.
- GammaGWR+ (Parisi et al., 2018) - GammaGWR for incremental learning with temporal synapses and an additional option for regularized neurogenesis. GammaGWR+ implements intrinsic memory replay via recurrent neural activity trajectories (check incremental_demo.py).
References:
[Marsland et al., 2002] Marsland, S., Shapiro, J., and Nehmzow, U. (2002). A self-organising network that grows when required. Neural Networks, 15(8-9):1041-1058.
[Parisi et al., 2015] Parisi, G.I., Weber, C., Wermter, S. (2015) Self-Organizing Neural Integration of Pose-Motion Features for Human Action Recognition. Frontiers in Neurorobotics, 9(3).
[Parisi et al., 2017] Parisi, G.I., Tani, J., Weber, C., Wermter, S. (2017) Lifelong Learning of Human Actions with Deep Neural Network Self-Organization. Neural Networks, 96:137-149.
[Parisi et al., 2018] Parisi, G.I., Tani, J., Weber, C., Wermter, S. (2018) Lifelong Learning of Spatiotemporal Representations with Dual-Memory Recurrent Self-Organization. arXiv:1805.10966.
Contact:
Emotion Appraisal and Empathy Models
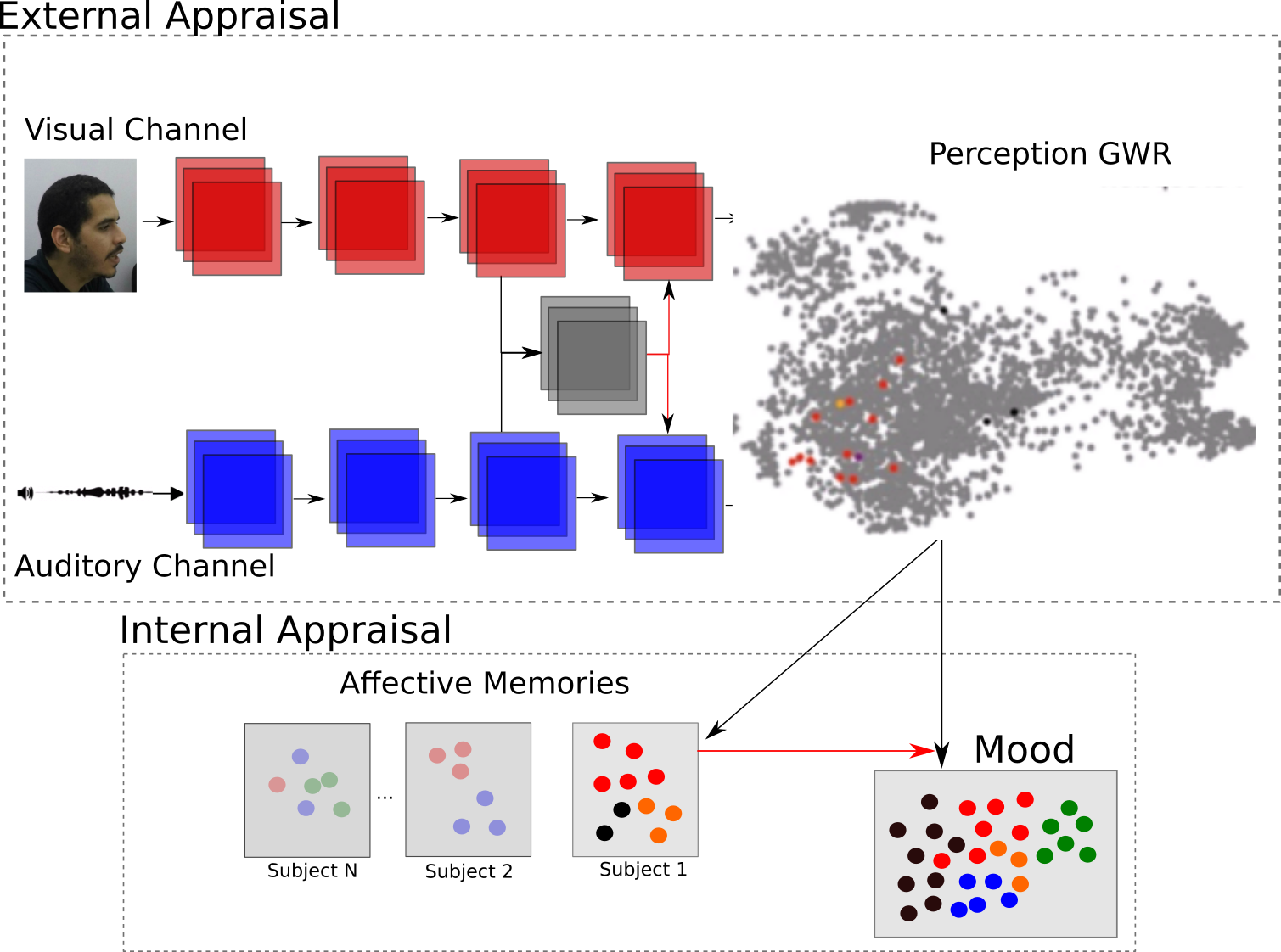
Emotions are related to many different parts of our lives: from the perception of the environment around us to different learning processes and natural communication. They have an important role when we talk to someone when we learn how to speak, when we meet a person for the first time, or to create memories
The research field of affective computing introduces the use of different emotional concepts in computational systems. Imagine a robot which can recognize spontaneous expressions and learn with it how to behave in a certain situation, or yet it uses emotional information to learn how to perceive the world around it. This is among the hardest challenges in affective computing: how to integrate emotion concepts in artificial systems to improve the way they perform a task, like communication or learning. One of the most important aspects of affective computing is how to make computational systems recognize and learn emotion concepts from different experiences, for example in human communication. Although several types of research were done in this area in the past two decades, we are still far away from having a system which can perceive, recognize and learn emotion concepts in a satisfactory way.
This repository contains different solutions for emotion appraisal and artificial empathy. The models available in this repository use different computational concepts to solve each of these problems and implement solutions which proved to enhance the performance and generalization when recognizing emotion expressions.
Source Code:
https://github.com/knowledgetechnologyuhh/EmotionRecognitionBarros
Contact:
References
Alves de Barros, P. V. (2017). Modeling Affection Mechanisms using Deep and Self-Organizing Neural Networks.
Barros, P., & Wermter, S. (2016). Developing crossmodal expression recognition based on a deep neural model. Adaptive behavior, 24(5), 373-396.
Barros, P., & Wermter, S. (2017, May). A self-organizing model for
Source code of Ball Localization CNN - Paper (RoboCup, 2016)
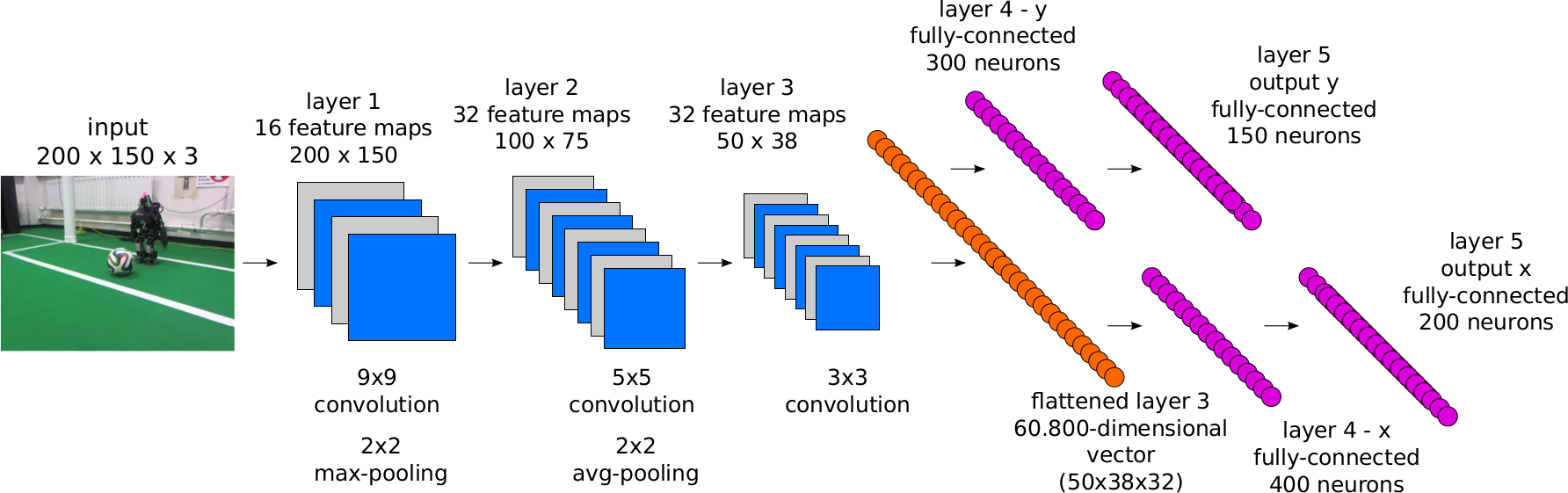
This is the source code (Python) for the paper "Ball Localization for Robocup Soccer using Convolutional Neural Networks", which proposes a new approach for localizing the ball in RoboCup humanoid soccer. A deep neural architecture is used without any preprocessing at all. The localization part gets solved by a convolutional neural network that is trained with probability distributions on full images. No sliding-window approach is used. The paper was written in the context of the Bachelor Thesis of Daniel Speck. The paper won the Best Paper Award for Engineering Contribution at the 20th Annual RoboCup International Symposium 2016 in Leipzig, Germany.
Source Code:
https://github.com/Daniel451/BachelorThesis
Contact:
Pablo Barros, Cornelius Weber, Stefan Wermter
Reference:
|
D. Speck, P. Barros, C. Weber, S. Wermter (2016) Ball Localization for Robocup Soccer using Convolutional Neural Networks. RoboCup 2016: Robot World Cup XX. |
Domain- and Cloud-based Knowledge for Speech Recognition - DOCKS
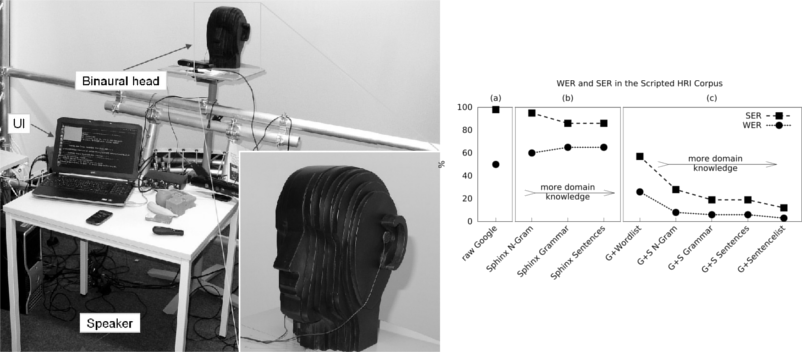
Google, Apple, Bing, and similar services offer very good and easily retrievable cloud-based automated speech recognition (ASR) for many languages and are taking advantage of constant improvements on the server side. However, these ASR systems cannot be adapted with domain knowledge (e.g. by restricting the recognizer to a fixed vocabulary, grammar, or statistical language model) which may result in poor application performance.
To address this gap, the Knowledge Technology group developed DOCKS (Domain- and Cloud-based Knowledge for Speech recognition), which combines the well trained acoustic models of the cloud services with domain-specific knowledge. It has been shown that DOCKS can improve the results of a cloud-based system like Google speech significantly if the domain can be restricted.
Source Code:
https://github.com/knowledgetechnologyuhh/docks
Contact:
Johannes Twiefel, MSc, Dr. Stefan Heinrich,
Professor Dr. Stefan Wermter, Dr. Timo Baumann, Dipl.-Ing. Erik Strahl
Reference:
|
Twiefel, J., Baumann, T., Heinrich, S., Wermter, S. Improving Domain-independent Cloud-based Speech Recognition with Domain-dependent Phonetic Post-processing. In Brodley C.E. et al., editors, Proceedings of the 28th AAAI Conference on Artificial Intelligence (AAAI-14), pp. 1529-1535, AAAI Press. Québec, CA, 2014. |
Source code of Syntactic Reservoir Model (PLoS ONE, 2013)
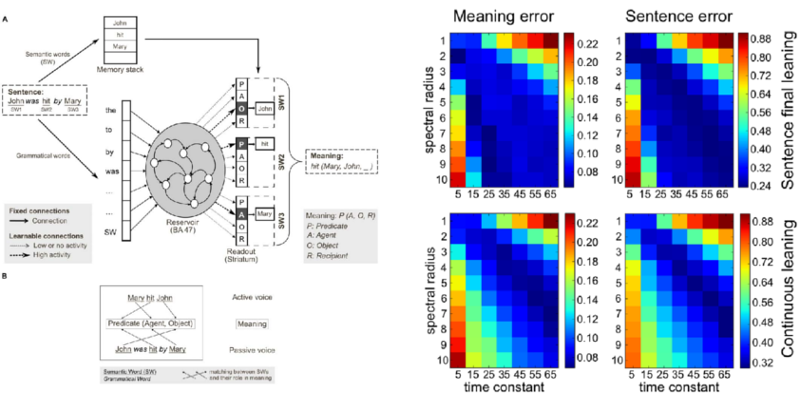
This is the source code (Python) given in supplementary material of our PLoS ONE paper of 2013. It enables to reproduce experiments of the paper and gives a full access to the model: you will be able to modify all the parameters and change the model. It uses Python libraries like Numpy, and also uses the Oger toolbox developed within the EU FP7 Organic (2009-2013) project.
Source Code:
https://sites.google.com/site/xavierhinaut/downloads
Contact:
Reference:
|
X. Hinaut, P.F. Dominey (2013) Real-Time Parallel Processing of Grammatical Structure in the Fronto-Striatal System: A Recurrent Network Simulation Study Using Reservoir Computing. PloS ONE 8(2): e52946. |
A biologically inspired spiking neural network model of the auditory midbrain for sound source localisation
Jindong Liu, David Perez-Gonzalez, Adrian Rees, Harry Erwin, Stefan Wermter
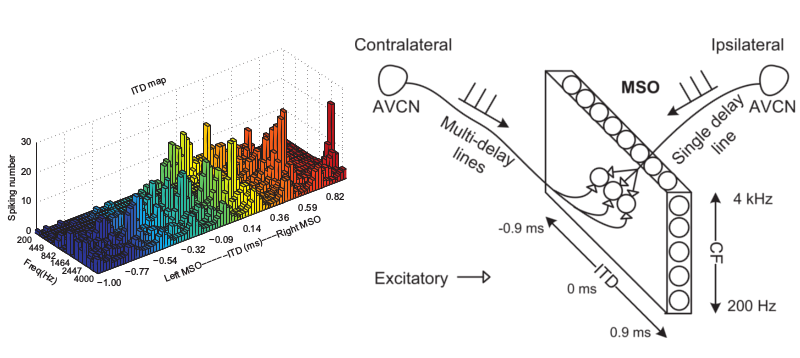
This work proposes a spiking neural network (SNN) of the mammalian subcortical auditory pathway to achieve binaural sound source localisation. The network is inspired by neurophysiological studies on the organisation of binaural processing in the medial superior olive (MSO), lateral superior olive (LSO) and the inferior colliculus (IC) to achieve a sharp azimuthal localisation of a sound source over a wide frequency range. Three groups of artificial neurons are constructed to represent the neurons in the MSO, LSO and IC that are sensitive to interaural time difference (ITD), interaural level difference (ILD) and azimuth angle, respectively. The neurons in each group are tonotopically arranged to take into account the frequency organisation of the auditory pathway. To reflect the biological organisation, only ITD information extracted by the MSO is used for localisation of low frequency (< 1 kHz) sounds; for sound frequencies between 1 and 4 kHz the model also uses ILD information extracted by the LSO.
The experimental results show that the addition of ILD information significantly increases sound localisation performance at frequencies above 1 kHz. Our model can be used to test different paradigms for sound localisation in the mammalian brain, and demonstrates a potential application of sound localisation for robots.
Source Code:
Contact:
Jindong Liu(jindong.liu"AT"gmail.com), David Perez-Gonzalez(davidpg"AT"usal.es), Adrian Rees(adrian.rees"AT"ncl.ac.uk), Stefan Wermter
References
| Liu, J., Perez-Gonzales, D., Rees, A., Wermter, S. (2010). A biologically inspired spiking neural network model of the auditory midbrain for sound source localisation. | |