Independent Research Topics and Thesis Offers
Open Vocabulary Object Detection

Object detectors like Mask R-CNN and YOLO are very good at locating and classifying known objects within images. In order to be successful though, these detectors generally need to be explicitly trained on a fixed number of classes with many (tens of) thousands of input samples. While the detectors are easy to use and train, obtaining and/or curating the appropriate training dataset for a particular set of objects is generally prohibitive and time-consuming. Open vocabulary object detectors can overcome this need for specialised training datasets, by locating objects in the image and classifying them with the use of language models. This allows novel objects to be detected simply by specification of their class in the form of (possibly descriptive) text. This thesis topic aims to construct an open vocabulary object detector, possibly based on YOLOv8 [1] and CLIP [2], while trying to learn from design decisions made by ViLD [3], CORA [4], and POMP [5].
Useful skills:
- Expert Python 3 programming skills (including experience working on/with large open-source libraries)
- Extensive experience using PyTorch and related libraries
- Interest in self-driven/independent study where you can implement and academically publish your ideas
Reference:
[1] YOLOv8: https://github.com/ultralytics/ultralytics
[2] CLIP: https://github.com/openai/CLIP
[3] ViLD: https://github.com/tensorflow/tpu/tree/master/models/official/detection/projects/vild
[4] CORA: https://github.com/tgxs002/CORA
[5] POMP: https://github.com/amazon-science/prompt-pretraining
Contact:
Image-prompted Textured 3D Model Generation
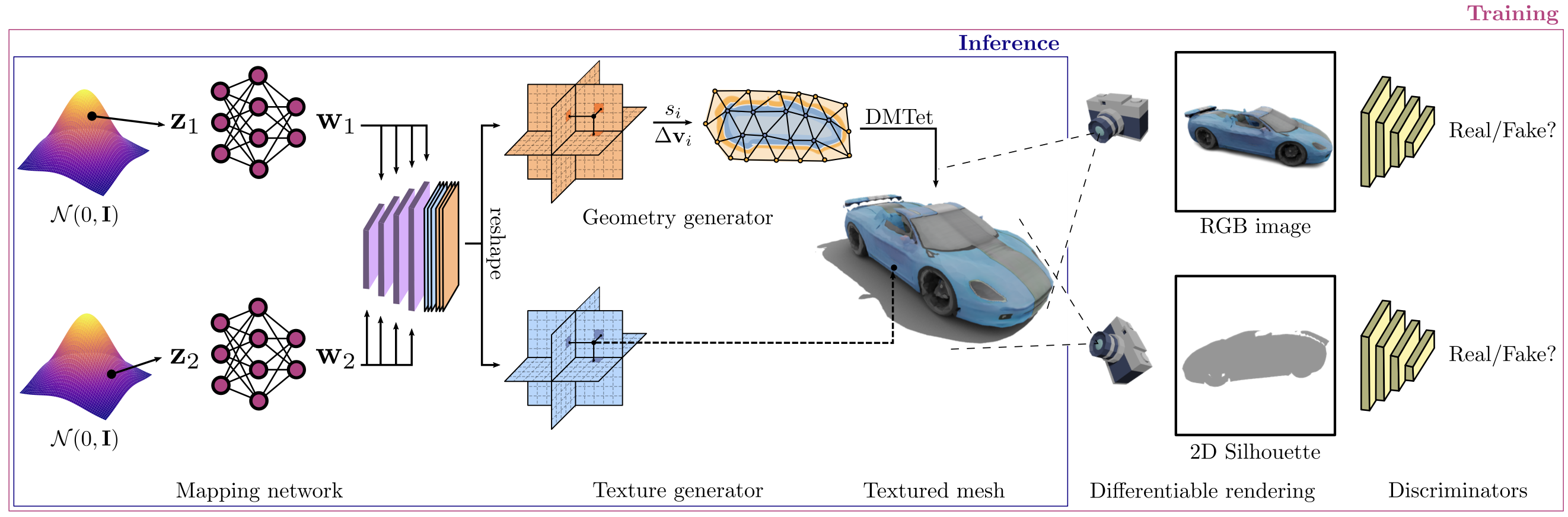
Recent works have made astounding progress toward generative models that can produce high quality 3D textured models. One example of such a model is Get3D [1], which is able to synthesise new models of a particular kind (whatever kind it was trained on, e.g. cars) based on a latent space input. Get3D was trained on subsets of the ShapeNet dataset [2], which provides many CAD models of different object classes. The task of this thesis is to extend the generative pipeline, ideally starting from the pretrained Get3D model, to allow image prompting, potentially first based on ShapeNet and then later based on images, e.g. from the ApolloCar3D dataset [3]. The aim is that a cropped and background-removed photo of a car can ultimately be used to generate a closely matching 3D textured car model, as well as estimate the orientation/viewpoint of the car in the photo.
Useful skills:
- Expert Python 3 programming skills (including experience working on/with large open-source libraries)
- Extensive experience using PyTorch and related libraries
- Interest in self-driven/independent study where you can implement and academically publish your ideas
Reference:
[1] Get3D / Image: https://github.com/nv-tlabs/GET3D
[2] ShapeNet: https://shapenet.org
[3] ApolloCar3D: https://apolloscape.auto/car_instance.html
Contact:
Gesture Recognition for Robot-Human Communication Using Transformers
![]()
![]()
Transformers are currently state-of-the-art models for natural language processing and they have started to make a good impression in the computer vision field as well [1]. This research project aims at designing a novel architecture for exploiting the capabilities of attention-based models such as transformer networks and provide a robust methodology for improving human-robot interaction through the recognition of gestures as a way of communication. Here at WTM we have developed Snapture [2], an architecture that enables learning static and dynamic gestures. This architecture is based on convolutional neural networks and LSTMs. Stepping on this research we want to move now towards exploring the potential of transformer architectures. One possible way to exploit a transformer architecture for gesture recognition is by pairing it with a strong feature extractor such as MediaPipe [3], a general purpose machine learning open source project developed by Google with robust pose estimation capabilities
Goals:
- Design a novel deep neural network architecture based on transformers for gesture recognition
- Implement, train and evaluate the new architecture using a standard benchmark for gesture recognition
- Possibly create and make publicly available a new dataset for gesture recognition in the context of human-robot communication
Useful skills:
- Proficiency in Python coding
- Interest in human-robot communication
- Experience programming and training deep neural networks
Reference:
[1] Z. Cao , Y. Li, B-S. Shin. "Content-Adaptive and Attention-Based Network for Hand Gesture Recognition" [PDF]
[2] H. Ali, D. Jirak, S. Wermter (2022) "Snapture - A Novel Neural Architecture for Combined Static and Dynamic Hand Gesture Recognition" [PDF]
[3] MediaPipe
Contact:
Localisation and Navigation of Humanoid Pepper Robot

The ability to navigate through a semi-dynamic environment is an important skill for a humanoid robot. This skill extends its range and field of applicability for human-robot interaction scenarios. In recent work, we have fitted a 2D lidar sensor [1] to one of our Pepper robots [2], and established localisation and navigation abilities within simple office scenarios. The assembled navigation stack uses Adaptive Monte Carlo Localisation (AMCL) for localisation [3], and a mix of global and local path planners for navigation. The use of a neural method for the purposes of navigation is to be investigated, possibly inspired for instance by Neural SLAM [4], or neural lidar odometry methods such as CAE-LO [5], PSF-LO [6], or the probabilistic trajectory estimator used in [7].
As a reference navigation approach, a new and more robust localisation and navigation stack should be developed, which applies a Simultaneous Localisation and Mapping (SLAM) method, and concurrently registers the output thereof against a known 2D reference map. The navigation strategy needs to allow path planning to targets that are outside the current SLAM map, but within the more comprehensive reference map. As an extension goal, any need for manual localisation initialisation should be alleviated using a global matching strategy between local laser scans and the reference map. The performance of the final navigation stack should be experimentally compared to the existing one.
Goals:
- Apply and tune a SLAM method for 2D robot localisation on the Pepper robot
- Implement a path planning/navigation strategy that efficiently utilises the omnidirectional capabilities of the Pepper robot in order to drive to a global pose goal while avoiding obstacles
- Possibly develop a robust global localisation initialisation strategy
Useful skills:
- High proficiency in object-oriented C++ and Python coding
- Prior experience with the Robot Operating System (ROS) middleware and PyTorch
- Interest in navigation and mapping using mobile robots
- Experience working with Raspberry Pi and/or robotic systems
Reference:
[1] YDLidar G2 Sensor Datasheet
[2] SoftBank Robotics Pepper robot
[3] D. Fox, W. Burgard, F. Dellaert, and S. Thrun (1999), “Monte carlo localization: Efficient position estimation for mobile robots” [PDF]
[4] J. Zhang, L. Tai, M. Liu, J. Boedecker, and W. Burgard (2020), "Neural SLAM: Learning to Explore with External Memory" [PDF]
[5] D. Yin, Q. Zhang, J. Liu, X. Liang, Y. Wang, J. Maanpää, H. Ma, J. Hyyppä, and R. Chen (2020), "CAE-LO: LiDAR Odometry Leveraging Fully Unsupervised Convolutional Auto-Encoder Based Interest Point Detection and Feature Description" [PDF]
[6] G. Chen, B. Wang, X. Wang, H. Deng, B. Wang, and S. Zhang (2021), "PSF-LO: Parameterized Semantic Features Based Lidar Odometry" [PDF]
[7] D. Yoon, H. Zhang, M. Gridseth, H. Thomas, T. Barfoot (2021), "Unsupervised Learning of Lidar Features for Use in a Probabilistic Trajectory Estimator" [PDF]
Contact:
Multi-agent Planning with Large Language Models
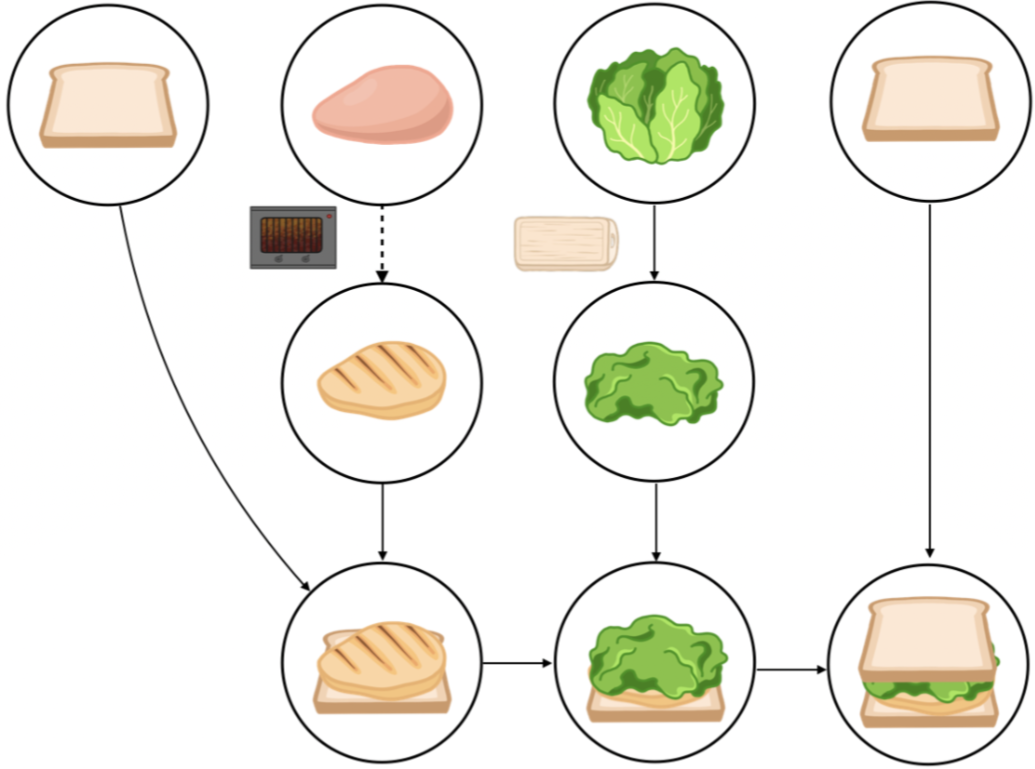 While large language models (LLMs) show promise in high-level task planning, most current methods lack asynchronous planning capabilities for multi-agents. In our recent paper [1], we propose LLM+MAP, a framework that utilizes Planning Domain Definition Language (PDDL) with LLM to let our NICOL humanoid robot perform long-horizon bimanual tasks. There is great potential to extend our framework to various planning domains. ROBOTOUILLE [2] is a benchmark to evaluate asynchronous planning through tasks that take time, like cooking meat for burgers or sandwiches or filling up a pot with water to cook soup. In this topic, we will explore to apply LLM+MAP on diverse tasks in this benchmark dataset. The work on this topic is supported by the OpenAI Researcher Access Program in 2025 via sufficient API tokens.
While large language models (LLMs) show promise in high-level task planning, most current methods lack asynchronous planning capabilities for multi-agents. In our recent paper [1], we propose LLM+MAP, a framework that utilizes Planning Domain Definition Language (PDDL) with LLM to let our NICOL humanoid robot perform long-horizon bimanual tasks. There is great potential to extend our framework to various planning domains. ROBOTOUILLE [2] is a benchmark to evaluate asynchronous planning through tasks that take time, like cooking meat for burgers or sandwiches or filling up a pot with water to cook soup. In this topic, we will explore to apply LLM+MAP on diverse tasks in this benchmark dataset. The work on this topic is supported by the OpenAI Researcher Access Program in 2025 via sufficient API tokens.
Useful skills:
- Python programming skills (including experience working on/with large language models)
- Interest in self-driven/independent study where you can implement and academically publish your ideas.
References:
[1] Chu, Kun, Xufeng Zhao, Cornelius Weber, and Stefan Wermter. "LLM+ MAP: Bimanual Robot Task Planning using Large Language Models and Planning Domain Definition Language." arXiv preprint arXiv:2503.17309 (2025)
[2] Gonzalez-Pumariega, Gonzalo, Leong Su Yean, Neha Sunkara, and Sanjiban Choudhury. "Robotouille: An Asynchronous Planning Benchmark for LLM Agents.”, ICLR 2025
Contact:
General Purpose Human Pose Estimation

Human pose estimation is a field that has seen many advances in the past years, and is important in human-robot interaction scenarios for a greater robot situational awareness. We wish to focus on the detection and wholistic understanding, from monocular images, of human body parts and keypoints in both 2D and 3D. This is a broad topic that offers a multitude of research directions for a prospective thesis, which in distant future work would seek to be united. The following individual possible goals are considered:
-
Can a feature backbone successfully be shared for human bounding box detection and 2D keypoint detection?
Bounding box detection and keypoint detection are both time intensive processes, and performing both concurrently in a single network offers computational savings, as well as the sharing of knowledge, i.e. the visual understanding of human body parts [1] [2] [3]. Refer to new research in this direction [9]. -
Can 3D keypoint detection performance be improved by including the backbone feature maps as further inputs?
3D keypoint estimators typically only receive 2D keypoint detection coordinates as input [4], thereby not allowing the network to learn from any visual context that can provide hints regarding limb depth and/or positional ambiguity. -
Can 2D keypoint detection performance in the wild be improved by training on multiple united datasets?
Single datasets can lack the complete diversity required to train networks that are also effective in the wild [5]. -
Can a more wholistic understanding of the appearance of the human body be learnt by concurrently training multiple related tasks?
Examples of candidate tasks in addition to 2D keypoint estimation include instance segmentation, body part segmentation [6], dense pose estimation [7], and more if considering 3D pose estimation [8]. Related idea [10]. -
Can temporal information be used to improve 2D keypoint detection robustness for video sequences?
It is common for 3D keypoint estimators to use sequences of multiple frames in order to improve their estimation quality in the face of ambiguities [4]. Can 2D keypoint detectors also benefit in order to help deal with body part occlusions?
Useful skills:
- Expert Python 3 programming skills (including experience working on/with large open-source libraries)
- Extensive experience using PyTorch and related libraries
- Interest in self-driven/independent study where you can implement and academically publish your ideas
Reference:
[1] Z. Ge, S. Liu, F. Wang, Z. Li, and J. Sun, "YOLOX: Exceeding YOLO Series in 2021", arXiv preprint arXiv:2107.08430, 2021. [PDF]
[2] D. Bolya, C. Zhou, F. Xiao, Y. Lee, "YOLACT++: Better Real-time Instance Segmentation", arXiv preprint arXiv:1912.06218, 2020. [PDF]
[3] Z. Huang, L. Huang, Y. Gong, C. Huang, X. Wang, "Mask Scoring R-CNN", arXiv preprint arXiv:1903.00241, 2019. [PDF]
[4] D. Pavllo, C. Feichtenhofer, D. Grangier, M. Auli, "3D human pose estimation in video with temporal convolutions and semi-supervised training", arXiv preprint arXiv:1811.11742, 2019. [PDF]
[5] J. Lambert, Z. Liu, O. Szener, J. Hays, V. Koltun, "MSeg: A Composite Dataset for Multi-domain Semantic Segmentation", arXiv preprint arXiv:2112.13762, 2021. [PDF]
[6] W. Wang, Z. Zhang, S. Qi, J. Shen, Y. Pang, L. Shao, "Learning Compositional Neural Information Fusion for Human Parsing", arXiv preprint arXiv:2001.06804, 2020. [PDF]
[7] R. Güler, N. Neverova, I. Kokkinos, "DensePose: Dense Human Pose Estimation In The Wild", arXiv preprint arXiv:1802.00434, 2018. [PDF]
[8] A. Mertan, D. Duff, G. Unal, "Single Image Depth Estimation: An Overview", arXiv preprint arXiv:2104.06456, 2021. [PDF]
[9] D. Maji, S. Nagori, M. Mathew, D. Poddar, "YOLO-Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss", arXiv preprint arXiv:2204.06806, 2022. [PDF]
[10] C. Wang, I. Yeh, H. Liao, "You Only Learn One Representation: Unified Network for Multiple Tasks", arXiv preprint arXiv:2105.04206, 2021. [PDF]
Contact:
Multi-modal Gesture Recognition
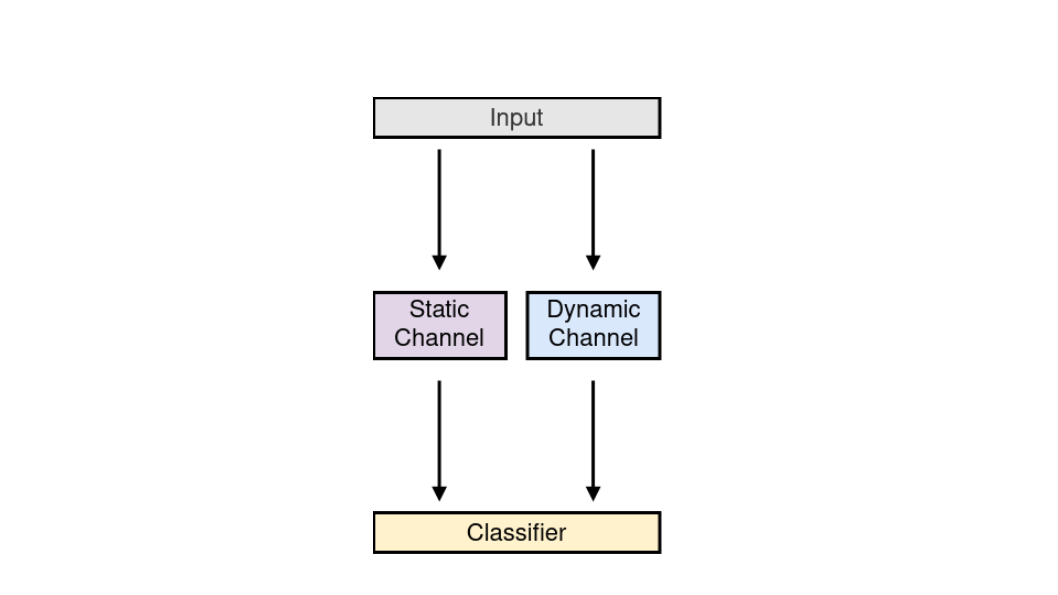

In human-human communication, gestures are essential components of non-verbal communication and have been identified as social cues in human-robot interaction (HRI). Co-speech gestures are delivered with speech and can enhance specific word meanings. The examples for co-speech gestures range from static poses like "OK" to dynamic hand movements while giving a public talk. While the recognition of those gesture forms is inevitably necessary to foster natural HRI scenarios, most research in gesture recognition has focused only on a separate aspect of gestures, either hand pose or dynamic gesture recognition. We recently tackled the integration of both modalities introducing a novel neural network architecture called "Snapture" [1]. Snapture is a modular framework that learns both a specific finger pose and the arm movements involved in the gesture expression. Snapture is based on convolutional neural networks (CNN), which learn hand poses and long short-term memory networks (LSTM) to model the temporal sequences. We showed the robustness of the architecture using the Montalbano co-speech benchmark dataset [2]. The Snapture framework offers a multitude of extensions for a prospective Master thesis:
-
Improvement of the threshold-based activation of the static hand recognition channel for the flexible detection of hand poses in a sequence.
-
Analysis of the neuronal network activations (e.g. grad-Cam or embeddings) and integration of attention mechanisms to understand the working principles of the Snapture architecture.
-
Integration of facial expressions in alignment with co-speech gestures to add an affective dimension to the gesture expression context.
-
Optional (depending on the Covid19 situation): Implementation of HRI co-speech scenarios with a humanoid robot.
The Snapture framework will be made available at the start of the Master thesis. We require a profound knowledge of artificial neural networks, their learning principles, and network performance evaluation. Programming experience in Python is mandatory. Experiences with gesture recognition both in human-human and human-robot interaction is a plus.
Useful skills:
-
Profound knowledge of artificial neural networks
-
Programming experience with Python
-
Interest in gesture recognition
Reference:
[1] Hassan Ali: Snapture-A Hybrid Hand Gesture Recognition System, 2021
[2] https://chalearnlap.cvc.uab.es/dataset/13/description/
Contact:
https://www.inf.uni-hamburg.de/en/inst/ab/wtm/people/ali.html
Hassan Ali, Dr. rer. nat. Doreen Jirak, Prof. Dr. Stefan Wermter
Compositional Object Representations in Multimodal Language Learning
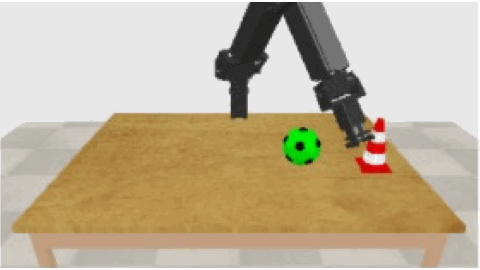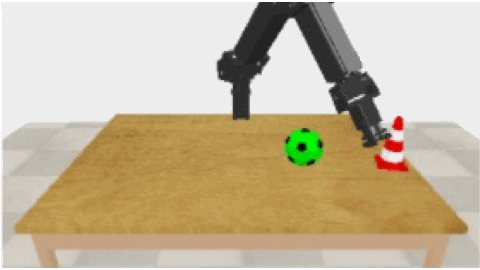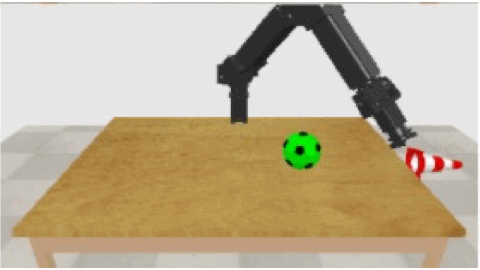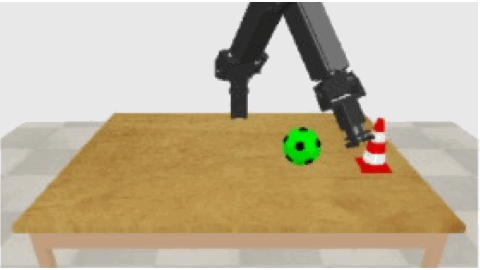
In recent work [1], we have tested the capability of a robot to tell about what it is doing. It learnt to produce phrases like "push red pylon", even if it has never before seen a red pylon, but only pylons of other colors and other red objects. Moreover, additional irrelevant object within the robot's field of view do not disturb much. However, the performance drops drastically, if there are not many color and object combinations in the dataset (while keeping the dataset of constant size). In this thesis, we want to tackle this difficult case for generalization. We will investigate whether unsupervised pretraining (either with a small number of color and object combinations, or with a larger number, but always without labels) would help. We plan also to consider importing models for preprocessing that are pretrained on large vision-language datasets, such as ViLBERT [2]. We will validate the success of the extended model on the difficult multi-object cases in our earlier experiments [1].
Goals:
- Develop a model which describes an action performed in a scene on one of several objects
Useful skills:
- Neural networks
- Interest in 3D robot simulator CoppeliaSim
References:
[1] Generalization in Multimodal Language Learning from Simulation
Aaron Eisermann, Jae Hee Lee, Cornelius Weber, Stefan Wermter, IJCNN 2021
[2] ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
Lu et al., NeurIPS 2019
Contact:
Human-robot dialog systems with deep reinforcement learning
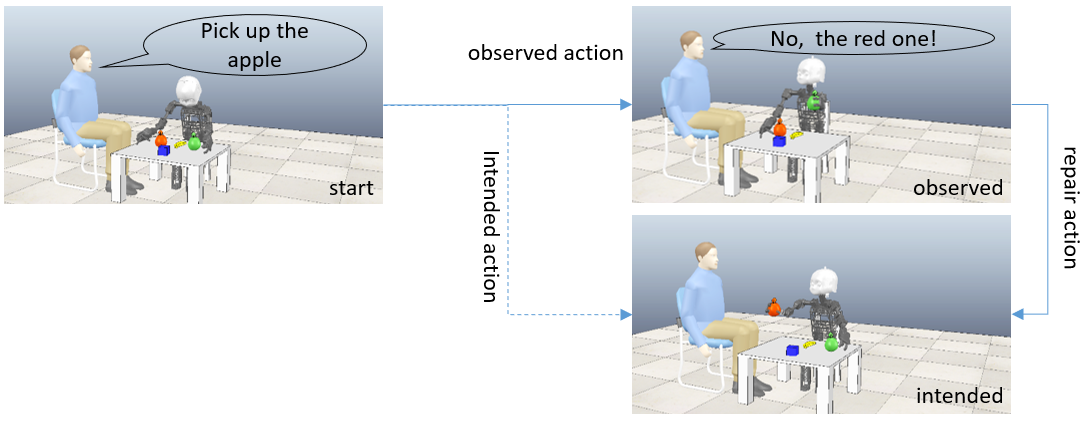
Robots should be able to understand human language [1]. Moreover, they should be able to perform a natural language dialog with humans. Dialogs are commonly modeled in a framework based on dialog states and dialog acts that is potentially compatible with recent advances in reinforcement learning, specifically with goal-conditioned reinforcement learning [2,3]. The task for this thesis work is to identify and to evaluate in how far dialog systems can be realized with different existing goal-conditioned reinforcement learning methods.
We will provide you with Python code, and, depending on your own preferences and previous experience, you will extend the code based on an initial virtual discussion and brainstorming session. The details are subject to negotiation during an initial meeting.
Goals:
- Enhance existing goal-conditioned reinforcement learning methods in order to use them for robotic dialog systems.
- Develop a method to represent dialog states and dialog acts appropriately
- Evaluate the performance of the methods using state-of-the-art benchmark datasets
- Possibly integrate the learning of human-robot dialog with action execution by the robot.
Literature:
[1] Zhao, R. (2020) Deep Reinforcement Learning in Robotics and Dialog Systems https://edoc.ub.uni-muenchen.de/26684/1/Zhao_Rui.pdf
[2] Röder*, F., Eppe*, M., Nguyen, P. D. H., & Wermter, S. (2020). Curious Hierarchical Actor-Critic Reinforcement Learning. International Conference on Artificial Neural Networks (ICANN). http://arxiv.org/abs/2005.03420
[3] Eppe (2019) From Semantics to Execution: Integrating Action Planning With Reinforcement Learning for Robotic Causal Problem-Solving (https://www.frontiersin.org/articles/10.3389/frobt.2019.00123/full)
Code and data:
- https://github.com/knowledgetechnologyuhh/goal_conditioned_RL_baselines
- https://www.repository.cam.ac.uk/handle/1810/294507
- https://research.fb.com/publications/learning-end-to-end-goal-oriented-dialog/
- https://github.com/Maluuba/frames
Contact:
Gaze Prediction for Robot Control

Attending to certain regions indicates an interest in acting towards them. This behavior is present in many animals that rely heavily on eyesight for survival. Among humans, gaze also shapes our linguistic and behavioral tendencies, necessitating its understanding for our social normality. Moreover, gaze serves a dual function in social scenarios: we perceive others' eye movements and signal our own intention through gaze [1]. Allowing robots to replicate human-like gaze patterns would potentially elevate their social acceptance and lead to a better understanding of attention and human eye movement.
To mimic the human gaze, we must distinguish between the gaze patterns of different individuals. Trajectory-based [2,3] and generative [4] approaches have tackled this issue by learning individual trajectories and generating future frames given single observers, respectively. However, such approaches disregard auditory stimuli, which has proven positively influential in saliency prediction models [5]. Lathuilière et al. [6] introduced an audiovisual reinforcement-learning-based gaze control model, conditioned on maximizing the number of speakers within the robot's view. Your goal is to extend a trajectory-based or generative approach by integrating auditory input into the purely visual-based approaches. Alternatively, you may instead resort to treating the problem as one of gaze control. This can be achieved by utilizing audiovisual reinforcement-learning approaches, with the task of mimicking human gaze patterns, using datasets providing the fixations of multiple observers while watching videos. Finally, you will embody your model in a robot, either in a simulated or physical environment (or both).
Goals:
- Develop or enhance a gaze prediction algorithm with multimodal input
- Conceptualize and develop a soft-realtime gaze control approach for smooth and realistic robotic actuation
- Evaluate the approach on a robot of your choice (e.g., iCub, Pepper, NICO)
Useful skills:
- A good background in neural networks
- Previous experience with Python and one or several deep learning frameworks (e.g., Keras and Tensorflow, PyTorch)
- Experience with middleware (e.g., YARP, ROS) is desirable
- Interest in motor control, human eye movement, and computer vision
References:
[1] Cañigueral, Roser, and Antonia F. de C. Hamilton. "The role of eye gaze during natural social interactions in typical and autistic people." Frontiers in Psychology 10 (2019): 560.
[2] Huang, Yifei, et al. "Predicting gaze in egocentric video by learning task-dependent attention transition." Proceedings of the European Conference on Computer Vision - ECCV. (2018): 754-769.
[3] Xu, Yanyu, et al. "Gaze prediction in dynamic 360 immersive videos." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition - CVPR. (2018): 5333-5342.
[4] Zhang, Mengmi, et al. "Deep future gaze: Gaze anticipation on egocentric videos using adversarial networks." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition - CVPR. (2017): 4372-4381.
[5] Tsiami, Antigoni, Petros Koutras, and Petros Maragos. "STAViS: Spatio-temporal audiovisual saliency network." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition - CVPR. (2020): 4766-4776.
[6] Lathuilière, Stéphane, et al. "Neural network based reinforcement learning for audio–visual gaze control in human–robot interaction." Pattern Recognition Letters 118 (2019): 61-71.
Contact:
Scene Dependent Speech Recognition

In the context of assistive robots, verbal user instructions to a robot often refer to objects that are visible in the immediate surround. Robot speech recognition could therefore benefit from visual context by biasing recognition towards words that denote seen objects. Task is to create such an audio-visual model and a methodology to train it.
Goals:
- Develop a novel speech recognition architecture with additional visual input
- Find a dataset and develop a training methodology
- Evaluate the trained model
Useful skills:
- Programming experience with Python
- Familiarity with deep learning
- Interest in speech recognition and vision processing
References:
[1] https://pjreddie.com/darknet/yolo/
[2] https://missinglink.ai/guides/tensorflow/tensorflow-speech-recognition-two-quick-tutorials/
Contact:
Cornelius Weber, Marie Sophie Bauer, Prof. Dr. Stefan Wermter
Lip Reading by Social Robots to Improve Speech Recognition in Noisy Environments

In social interactions, humans can easily focus their attention on a single conversation by filtering the noise coming from the background and other simultaneous talking, usually, by processing visual stimuli to aid the auditory stimuli corrupted by such noise sources (Czyzewski et al., 2017). This selective attention is called the "cocktail party effect", and it is a desirable attribute for social robots designed to guide people in museums and social events. In this thesis, the cocktail party problem will be addressed by incorporating lip movements as a complementary input to an automatic speech recognition (ASR) system in order to improve real-time speech recognition performance in noisy environments. Moreover, a selective attention mechanism using visual and auditory stimuli will be designed to keep the robot's attention towards a given person during human-robot interactions (HRIs). Different audio-visual datasets for speech recognition will be used such as GRID (Cooke et al., 2006) and MV-LRS (Chung et al., 2016) so as to assess the system in controlled and uncontrolled scenarios. The GRID dataset is composed of short commands (e.g. "put red at G9 now") recorded in a well controlled indoor scenario, whereas the MV-LRS dataset consists of long and unconstrained sequences of recordings in studios and outdoor interviews from BBC television.
Goals:
- Development of ASR system that uses visual and auditory inputs for real-time speech recognition in noisy environments
- Improving human-robot interaction quality regarding the cocktail party effect
- For a Master Thesis: Development of a selective attention mechanism to keep the robot's attention directed at a speaker
Useful skills:
- An interest in computer vision, linguistics, bio-inspired approaches and HRI
- Experience in deep learning and robotic experimentation
- Programming skills in Python and deep learning frameworks (e.g. Keras, TensorFlow, and PyTorch)
References:
Chung, J. S., Senior, A., Vinyals, O., & Zisserman, A. (2017). Lip Reading Sentences in the Wild. IEEE Conference on Computer Vision and Pattern Recognition. Cooke, M., Barker, J., Cunningham, S., & Shao, X. (2006). An audio-visual corpus for speech perception and automatic speech recognition. The Journal of the Acoustical Society of America, 120(5), 2421-2424. Czyzewski, A., Kostek, B., Bratoszewski, P., Kotus, J., & Szykulski, M. (2017). An audio-visual corpus for multimodal automatic speech recognition. Journal of Intelligent Information Systems, 49(2), 167-192.
Contact:
Henrique Siqueira, Leyuan Qu, Dr. Cornelius Weber, Prof. Dr. Stefan Wermter
Explainable Neural State Machine with Spatio-Temporal Relational Reasoning
“Explainable Agent” refers to autonomous agents that can explain their actions and the reasons leading to their decisions. This will incite their users to understand their capabilities and limits, thereby improving the levels of trust and safety, and avoiding failures. The Neural State Machine (NSM) is an explainable agent that bridges the gap between neural and symbolic AI by integrating their complementary strengths for the task of visual reasoning [1]. Given an image, the NSM first predicts a probabilistic semantic graph that represents the underlying semantics and serves as a structured world model. The structured world model is then used to perform sequential reasoning over the graph. The NSM provides spatial relational reasoning through a probabilistic scene graph. However, the Graph R-CNN used in the NSM is a black-box model. Therefore, the users may not be able to understand the reasons and causes for the NSM outputs. In addition, the NSM is not able to link meaningful transformations of objects or entities of the semantic graph over time. The objective of this project is, therefore, to develop an explainable NSM with Spatio-temporal reasoning.

spatial relational reasoning [1]
temporal relational reasoning (http://relation.csail.mit.edu/)
Goal
- To improve the effectiveness of explanations by improving model interpretability of the NSM [2].
- To enhance the NSM with Temporal Relational Reasoning capability.
Useful skills:
-
Programming experience, preferably Python and frameworks such as PyTorch, Tensorflow and Keras,
-
Knowledge in deep neural networks.
Reference
[1] Hudson, D. A. & Manning, C. D. (2019). Learning by Abstraction: The Neural State Machine. CoRR, abs/1907.03950.
[2] Stefan Wermter (2000). Knowledge Extraction from Transducer Neural Networks. Journal of Applied Intelligence, Vol. 12, pp. 27-42. https://www2.informatik.uni-hamburg.de/wtm/publications/2000/Wer00b/wermter.pdf
Contact:
Prof. Dr. Loo Chu Kiong, Dr. Cornelius Weber, Dr. Matthias Kerzel, Prof. Dr. Stefan Wermter
Realistic Turn-Taking in Virtual Multi-Agent Conversation
In humans and animals, responses to events in the environment depend critically on visual and auditory input integration. Our neuro-computational models of multimodal integration are embedded in robotic hardware and trained in controllable virtual reality robotic environments. The goal of this thesis is to develop a virtual environment that realizes a multi-agent conversation with realistic turn taking behaviour. The agents should be able to utilize both auditory cues (speaking up, interrupting each other) as well as visual cues (motion, gestures, head orientation) to signal turn taking. This task encompasses the design of individual virtual agents capable of expressing verbal and visual turn taking signals in the virtual robot experimentation platform V-REP and the development of a planning system that schedules turn taking for all agents to create a collaborative or conference like scenario. This thesis offer is part of the research project: “Vision- and action-embodied language learning”. 
Goals:
- Realization of a virtual reality multi-agent conversation scenario
- Development of a framework for realistic conversational turn taking behaviour of virtual agents using visual and auditory cues.
Useful skills:
- Interest in linguistics, especially with the topic of turn taking.
- Experience with the virtual robot experimentation platform V-REP.
- Good programming skills in Python.
Contact:
Exploring objects like a child with the NICO robot
Children learn to the know the environment but also to think in and express natural language by direct interaction with objects and other strange things in the environment. While doing this they make use of effective strategies from clumsily touching objects up to exploring it's affordances by manipulating it.
In this project we want to development these strategies for our NICO robot as a 3D-model in the virtual environment V-REP as well as our real robot in the lab. Furthermore we want to measure the perceived effect on the robot and on the objects and let the robot learn about object features over a longer time of interaction. As a long term goal we plan to employ the result of the project in our research on embodied language acquisition through automated linguistic instructions during robot object interaction. For this several students could collaborate e.g. working on visually tracking the manipulated objects and forming representations for perceived interactions in architectures in GWR and MTRNN architectures. 
Goals:
- Study into motor babling in infants and develop motion strategies for the NICO,
- Develop an interface for the motion characteristics,
- For a Master Thesis: Learn effective interaction with different objects in a neural architecture, e.g. recurrent and self-organising.
Useful skills:
- Interest in robotics, motion, haptics, and learning, Affinity for child development and cognitive psychology,
- Programming skills in Python,
- Experience in V-Rep or other simulators, and with the NICO robot.
Contact:
Dr. Matthias Kerzel, Dr. Cornelius Weber, Prof. Dr. Stefan Wermter
Neural Grasping NICO robot
To control the arm and position of the hand, a neural network controller has been successfully trained in simulation that can calculate the joint angles for a given set of coordinates and vice versa. The next steps would now be the extension of the neural model to include the rotation of the hand and to test the controller, which was trained in simulation, on the real robot.
Goals:
- Extend the neural controller to utilize all available joints of the arm, including rotation of the hand
- Successfully train the extended model in the simulator
- Test successfully trained neural networks on the real robot
- Analyse and evaluate controllers in terms of training performance and applicability
Useful skills:
- Interest in robots and neural networks.
- Programming experience, preferably Python or C++.
- Experience with 3D simulation environments and robots helpful but not necessary.
The topic is suitable to be a thesis at bachelor or master level.
Contact:
Indicative project topics in computing:
Creating a neuroscience-inspired learning interacting robot
 In this exciting project we look at neuroscience-inspired architectures for controlling the behavior of a robot. While traditional robots have often been preprogrammed, our new approach will focus on learning robots which will be based on some neuroscience evidence. These navigation and movement concepts are transferred and further developed on a Nao robot which has some speech and vision capabilities. The NeuroBot will learn to associate actions with words and pointing gestures. We want to restrict the fixed manual programming of the robot and emphasize the adaptive autonomous learning in neural networks in combination with restricted instructions via words and simple pointing. Some of the previous and current robot platforms available are shown at http://www2.informatik.uni-hamburg.de/wtm/neurobots. Students who participated in our project "Human Robot Interaction" can also suggest a further topic for their theses.
In this exciting project we look at neuroscience-inspired architectures for controlling the behavior of a robot. While traditional robots have often been preprogrammed, our new approach will focus on learning robots which will be based on some neuroscience evidence. These navigation and movement concepts are transferred and further developed on a Nao robot which has some speech and vision capabilities. The NeuroBot will learn to associate actions with words and pointing gestures. We want to restrict the fixed manual programming of the robot and emphasize the adaptive autonomous learning in neural networks in combination with restricted instructions via words and simple pointing. Some of the previous and current robot platforms available are shown at http://www2.informatik.uni-hamburg.de/wtm/neurobots. Students who participated in our project "Human Robot Interaction" can also suggest a further topic for their theses.
Goals:
- Learning navigation from simple multimodal input
- Robotic vision: Object recognition and object manipulation
- Implementation of neural network algorithms for speech and pointing instructions for NeuroBot
- At later stage: vision and speech capabilities for the NAO
Requirements:
- Programming skills: C/C++, Python
- At least basic knowledge in neural network algorithms and natural language processing
- Willingness to work in robotic environment
The thesis can be written either in German or English. All topics could be tailored to be at a bachelor, master level, or phd student level. If you are interested contact us for discussion:
Contact:
Additional project topics can be discussed in person!
Completed Theses
| Jul 2024 | Extending NICO’s Reach Through Torso Movement (MSc Thesis) |
Hendrik Evert Pfennig-Winkelsträter |
| Dec 2023 | Enabling Action Crossmodality for a Pretrained Large Language Model (BSc Thesis) |
Anton Caesar |
| Jul 2023 | Social Attention Prediction in a Free-Viewing Eye Tracking Task (MSc Thesis) |
Maximilian Keiff |
| Feb 2023 | Capturing Long-Term Dynamics During Salient Video Representation Learning (MSc Thesis) |
Theodor Wulff |
| Mar 2022 | Reinforcement Learning for Goal-Oriented Visual Dialogue (BSc Thesis) |
Yuliia Lysa |
| Apr 2021 | Target Speaker Text-to-Speech Synthesis from a Face Image Reference using Global Style Embeddings (BSc Thesis) |
Björn Plüster |
| Nov 2020 | Improving Model-Based Reinforcement Learning with Internal State Representations through Self-Supervision (BSc Thesis) |
Julien Scholz |
| Nov 2020 | Generalization in Multi-Modal Language Learning from Simulation (BSc Thesis) |
Aaron Eisermann |
| Oct 2020 | Towards Optimizing Dialogue Actions For Improved Sentiment Receival (BSc Thesis) |
Hendrik Pfennig |
| Sep 2020 | Improvement of the Inference Time of a German State-of-the-Art Automatic Speech Recognition System (Msc Thesis) |
Victoria Wagner |
| Apr 2020 | Variational Autoencoder with Global- and Medium Timescale Auxiliaries for Identity- and Emotion Recognition from Speech (Bsc Thesis) |
Hussam Almotlak |
| Jan 2020 | Ensemble-Based Multi-View Lipreading (MSc Thesis) |
Sönke Behrendt |
| Nov 2019 | Generation of Waveform Audio from Mel-spectrograms (BSc Thesis) |
Hauke Dau |
| Jul 2019 | Towards Personalized Reading Suggestions in a Newspaper App (BSc Thesis) |
Nina Arndt |
| Jun 2019 | Adaptive Goal-Directed Behavior using Planning with Reinforcement Rewards (BSc Thesis) |
Joshua Schimmelpfennig |
| May 2019 | Approximate Bayesian Inference in Recurrent Neural Networks (MSc Thesis) |
Robert Brown |
| Apr 2019 | Intermediate Representations in Deep Multimodal Neural Networks (MSc Thesis) |
Fares Abawi |
| Apr 2019 | Scale Estimation in Visual Object Tracking (BSc Thesis) |
Finn Rietz |
| Jan 2019 | A Deep Autoencoder for Unsupervised Learning of Place- and Head Direction Cells from Image Sequences (BSc Thesis) |
Oliver Heidmann |
| Dec 2018 | Attention-based Image Captioning with Recurrent Neural Networks (BSc Thesis) |
Lasse Westphal |
| Dec 2018 | Hierarchical Reinforcement Learning in Sparse Feedback Environments with the help of Intrinsic Motivation (BSc Thesis) |
Luc Baracat |
| Oct 2018 | Continuous Deep Reinforcement Learning with Normalized Advantage Functions for Robot Grasping (MSc Thesis) |
Joan Tomas Pape |
| Oct 2018 | Transfer Learning of Face Representations Using Semi-Supervised Strategies (MSc Thesis) |
Erik Fließwasser |
| Sep 2018 | Adapting to User Context in a Reinforcement Learning-based Dialogue System (MSc Thesis) |
Mehran Sheikholeslami |
| Sep 2018 | Multi-Attribute Face Generation Using Conditional BEGAN (MSc Thesis) |
Ahmed Elshinawi |
| Aug 2018 | Facial Expression Editing using a Conditional Adversarial Autoencoder (BSc Thesis) |
Alexandra Lindt |
| Aug 2018 | Implementation and Evaluation of a Deictic Gesture Interface with the NICO robot (BSc Thesis) |
David Biertimpel |
| Jun 2018 | Question Answering using Recurrent Neural Networks with Attention Mechanism (BSc Thesis) |
Michael Nelskamp |
| Jun 2018 | Feature Learning on EEG Recordings (BSc Thesis) |
Marian Wiskow |
| May 2018 | Visual Object Tracking for Robotic Applications (BSc Thesis) |
Tobias Knöppler |
| Apr 2018 | A Speech Enhancement Generative Adversarial Network for the WTM Robots (BSc Thesis) |
Patrick Eickhoff |
| Apr 2018 | Modelling Affective Cores for Behaviour Modulation in Social Robots (MSc Thesis) |
Nikhil Churamani |
| Jan 2018 | Bio-Inspired Auditory Signal Processing for Speech Recognition (BSc Thesis) |
Jose Alberto Rodriguez Parra Flores |
| Jan 2018 | Can Robot Nociception Increase the Human-likeness of Grasping Postures (BSc Thesis) |
Tim Reipschlaeger |
| Jan 2018 | Comparison of Design Methodologies of Echo State Networks (BSc Thesis) |
Yang Li |
| Jan 2018 | Hierarchical Control for Bipedal Locomotion using Central Pattern Generators and Neural Networks (MSc Thesis) |
Sayantan Auddy |
| Dec 2017 | Vector Representation of Chat Dialogs for Text Classification (BSc Thesis) |
Fabio Wendt |
| Dec 2017 | Neural Forecasting of the Sharpness of Images Taken by Walking Humanoid Robots (Diploma Thesis) |
Daniel Kreischer |
| Mar 2017 | Object Tracking with Convolutional Neural Networks (Diploma Thesis) |
Peer Springstübe |
| May 2017 | Comparison of behaviour-based architectures for human-robot collaboration in a package delivery task (MSc Thesis) |
Melanie Remmels |
| Mar 2017 | Detecting and Localizing Body Gestures in a Multi-Person Scenario Using a Deep Neural Network (MSc Thesis) |
Florian Letsch |
| Jan 2017 | P300 classification in EEG signals using Ladder Networks (BSc Thesis) |
Bastian Thiede |
| Dec 2016 | Brain-Inspired Visuo-Haptic Object Recognition (MSc Thesis) |
Sibel Toprak |
| Dec 2016 | Towards Understanding Auditory Representations in Emotional Expressions (MSc Thesis) |
Iris Wieser |
| Dec 2016 | Semi-Supervised Learning with Recurrent Ladder Networks (MSc Thesis) |
Marian Tietz |
| Nov 2016 | An Evolutionary Approach to Optimize the Hyperparameters of Convolutional Neural Networks (MSc Thesis) |
Tobias Hinz |
| Oct 2016 | A Compressing Auto-encoder as a Developmental Model of Grid Cells (MSc Thesis) |
Anthony L. Kiggundu |
| Oct 2016 | Word2Vec and Echo State Network For Thematic Role Assignment (MSc Thesis) |
Surender Kumar |
| Oct 2016 | Analysis of Spectral Data using Similarity Search (BSc Thesis) |
Thomas Klinger |
| Sep 2016 | Emotion Recognition from Body Expressions with a Recurrent Self-Organizing Neural Architecture (MSc Thesis) |
Nourhan Elfaramawy |
| Sep 2016 | Development of sampling method & Neural Network Classification of Materials Through Feedback from 3D Haptic Sensor (BSc Thesis) |
Moaaz Maamoon Mohammed Ali |
| Jul 2016 | Neural Network-Based Control of a Humanoid Robot for Grasping Tasks (MSc Thesis) |
Niklas Widulle |
| Jun 2016 | Ball tracking for RoboCup soccer using deep neural networks (BSc Thesis) |
Daniel Speck |
| May 2016 | Towards Effective Classification of Imbalanced Data with Convolutional Neural Networks (MSc Thesis) |
Vidwath Raj |
| May 2016 | Inertial Measurement Unit Based Multi User Gesture Recognition (BSc Thesis) |
Stephan Tietz |
| Apr 2016 | Player Modeling in Texas Hold'em Poker with Echo State Networks (BSc Thesis) |
Alexander Klassen |
| Apr 2016 | Improving the Post-Processing of Cloud-based Speech Recognition with Tri-Gram Language Models (BSc Thesis) |
Valentin Strauß |
| Mar 2016 | Self-Organization of Temporal Dynamics in Recurrent Neural Networks (MSc Thesis) |
Tayfun Alpay |
| Mar 2016 | Analysis of modulated spiking neural network (BSc Thesis) |
Marcus Soll |
| Jan 2016 | Crowdsourced Data Generation - How to Design a Website for Citizen Scientists? (BSc Thesis) |
Carina Garber |
| Jan 2016 | Optimal Stable Marriage Mapping with Particle Swarm Optimization (BSc Thesis) |
Tobias Tilly |
| Dec 2015 | Deep Neural Representation Analysis through Hierarchical Visualisation (MSc Thesis) |
Nima Mousavi |
| Dec 2015 | Hierarchical Reinforcement Learning using Neural Networks (MSc Thesis) |
Sohaib Younis |
| Nov 2015 | Gesture Recognition with a Convolutional Long Short Term Memory Recurrent Neural Network (MSc Thesis) |
Tsironi Eleni |
| Nov 2015 | Using online gesture learning with Echo State Networks to control an iCub robot head (BSc Thesis) |
Konstantin Kobs |
| Jul 2015 | Modeling Color Vision with Coding Strategies of Retinal Ganglion Cells (Diploma Thesis) |
Daniel von Poschinger-Camphausen |
| Jun 2015 | Prediction of Ship Fuel Consumption with Neural Networks (MSc Thesis) |
Ahmed Saleh |
| Apr 2015 | Recurrent Neural Network-based Probabilistic Language Model (MSc Thesis) |
Sathyanarayanan Kuppusami |
| Apr 2015 | Modulated Spiking-Neurons (BSc Thesis) |
Stefan Bruhns |
| Apr 2015 | Structural interference in approach and avoidance behaviors by a neurally controlled robot (BSc Thesis) |
Jonas Sperling |
| Mar 2015 | Entwicklung eines multimodalen Android Interface für ROS-basierte Roboter (BSc Thesis) |
Oliver Degener |
| Mar 2015 | Mechanical Design of the arms and Neural Arm control for the Humanoid Robot Platform Nimbro-OP (MSc Thesis) |
Atif Mahboob |
| Feb 2015 | Timescale independent pattern detection with Echo State Networks (BSc Thesis) |
Timur Olzhabaev |
| Jan 2015 | Determining Optimal Feature-Vector Length for Text Categorization Approaches (BSc Thesis) |
Marco Jendryczko |
| Jan 2015 | Intelligente Wegfindung humanoider Roboter am Beispiel des RoboCup (BSc Thesis) |
Martin Poppinga |
| Dec 2014 | Biologically Inspired Localization On Humanoid Soccer Playing Robots (BSc Thesis) |
Marc Bestmann |
| Oct 2014 | Learning to Reach with Interactive Reinforcement Learning (MSc Thesis) |
Chris Stahlhut |
| Aug 2014 | Learning of Human Motion Feedback by Neural Network Self-Organization (MSc Thesis) |
Florian von Stosch |
| Jun 2014 | Robotic Implementation and Evaluation of Multisensory Localisation with Reward Mediated Learning (BSc Thesis) |
Andreas Grenzing |
| May 2014 | Towards Bio-Inspired Robot Navigation – RatSLAM with the Humanoid Robot NAO (Dipl. Thesis) |
Stefan Müller |
| Mar 2014 | Development and Evaluation of Semantically Constrained Speech Recognition Architectures (MSc Thesis) |
Johannes Twiefel |
| Nov 2013 | Roboternavigation mit Hilfe einer Kognitiven Karte in Webots (BSc Thesis) |
Swantje Thüring |
| Sep 2013 | Neural Network Ensembles Using Haar-like Features for Face Detection (BSc Thesis) |
Tayfun Alpay |
| May 2013 | Improved Full-DOF Hand Pose Estimation Using Depth Images (MSc Thesis) |
Dennis Hamester |
| Mar 2013 | Application and Analysis of Classification in Textcategorization: A Comparative Study (BSc Thesis) |
Stefan Thomas |
| Mar 2013 | Evolving Locomotion for a Humanoid Robot (BSc Thesis) |
Heye Vöcking |
| Oct 2012 | Reccurent Neural Networks for Speech Recognition on Humanoid Robots (BSc Thesis) |
Sebastian Tschörner |
| Feb 2012 | Grounding of Language in Sensorimotor World Interaction of a Humanoid Robot, using Neural Networks (BSc Thesis) |
Thomas Christian Blank |
| Jan 2012 | Evolving Neural Networks for Bipedal Walking of a NAO Robot (BSc Thesis) |
Patrick Schmolke |
| Nov 2011 | Geräuschquellenlokalisation mit einem humanoiden Roboter (BSc Thesis) |
Robert Keßler |