base.camp
Department of Informaticsbase.camp
Photo: UHH/Denstorf
22 August 2025, by Omkar Kondhalkar
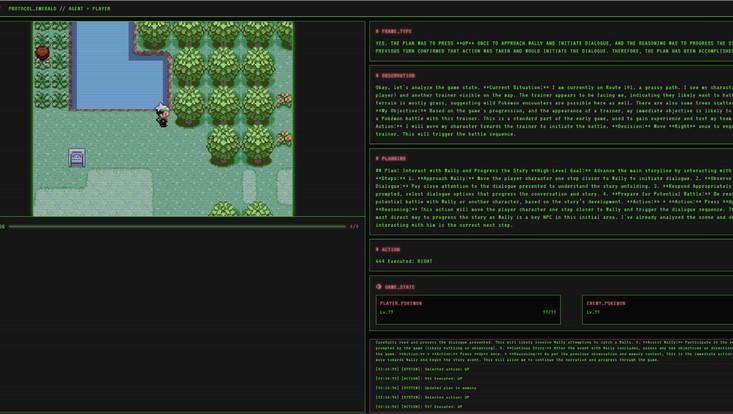
Photo: Arian Urdu
Addressing the NeurIPS 2025 PokéAgent Challenge (Track 2: Speedrunning Pokémon Emerald) by comparing Large Language Model agents (LLMs) and Deep Reinforcement Learning (RL). The core problem is automating the speedrun of the game without hard-coded solutions, a task demanding long-term planning and efficient exploration. The game is an ideal testbed for long time horizons and complex strategic resource planning, where immediate actions lack immediate rewards. The research will evaluate LLMs (local and API-based) alongside RL agents trained with methods like PPO (Proximal Policy Optimization). The goal is to analyze the respective strengths and limitations of LLM agents and RL in dynamic, goal-oriented environments. The turn-based nature of battles and lack of penalty for waiting in the game world is particularly suited to the current computational constraints of LLM agents.

