Score-based Generative Models (Diffusion Models) for Speech Enhancement and Dereverberation
This website contains supplementary material to the papers:
- Simon Welker, Julius Richter, Timo Gerkmann, Speech Enhancement with Score-Based Generative Models in the Complex STFT Domain, ISCA Interspeech, Incheon, Korea, Sep. 2022. [1]
- Julius Richter, Simon Welker, Jean-Marie Lemercier, Bunlong Lay, Timo Gerkmann, Speech Enhancement and Dereverberation with Diffusion-Based Generative Models, IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2351 - 2364, 2023. [2]
Code
The code is availabe at https://github.com/sp-uhh/sgmse
Denoising examples
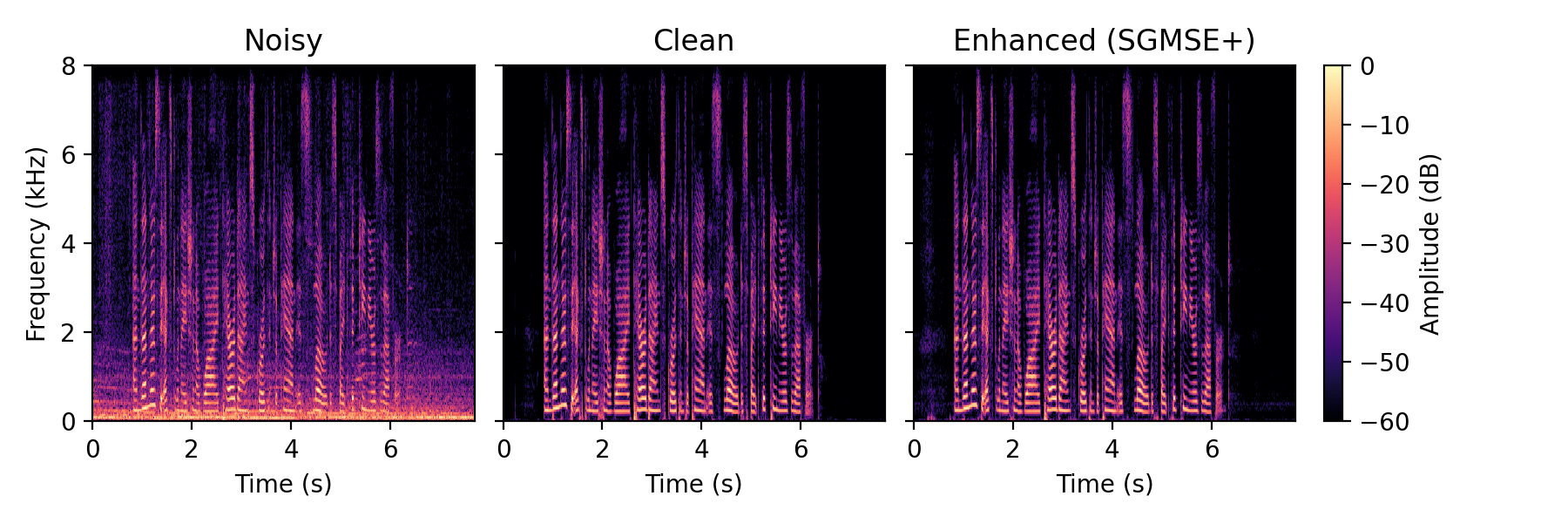
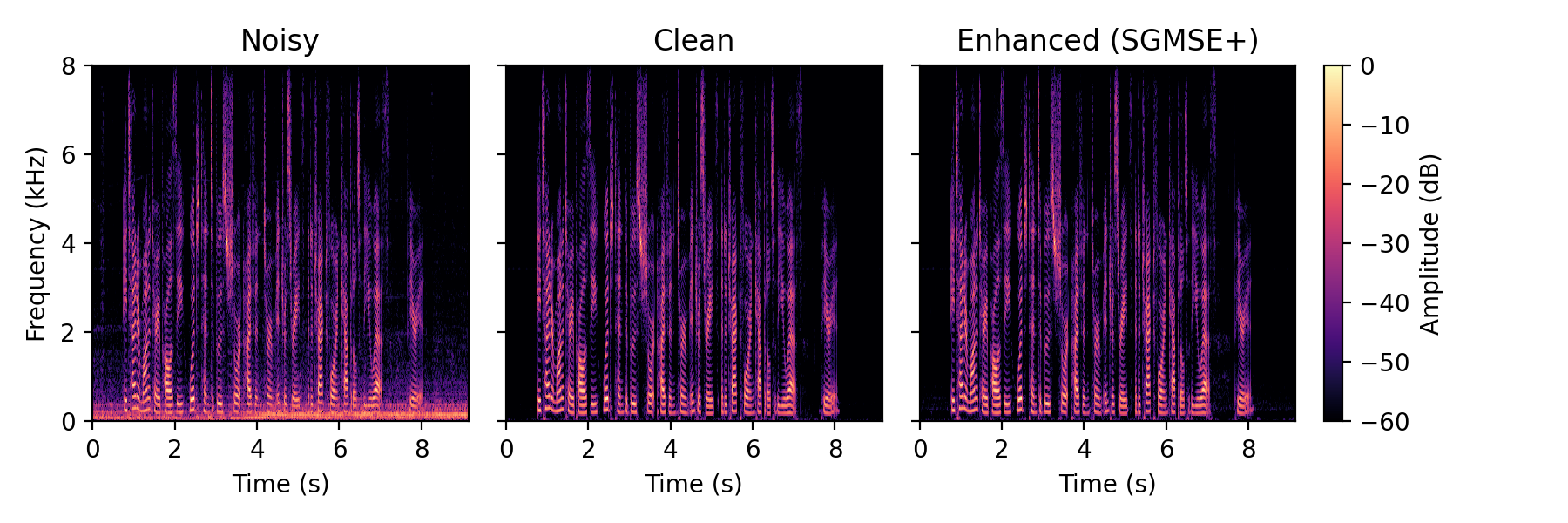
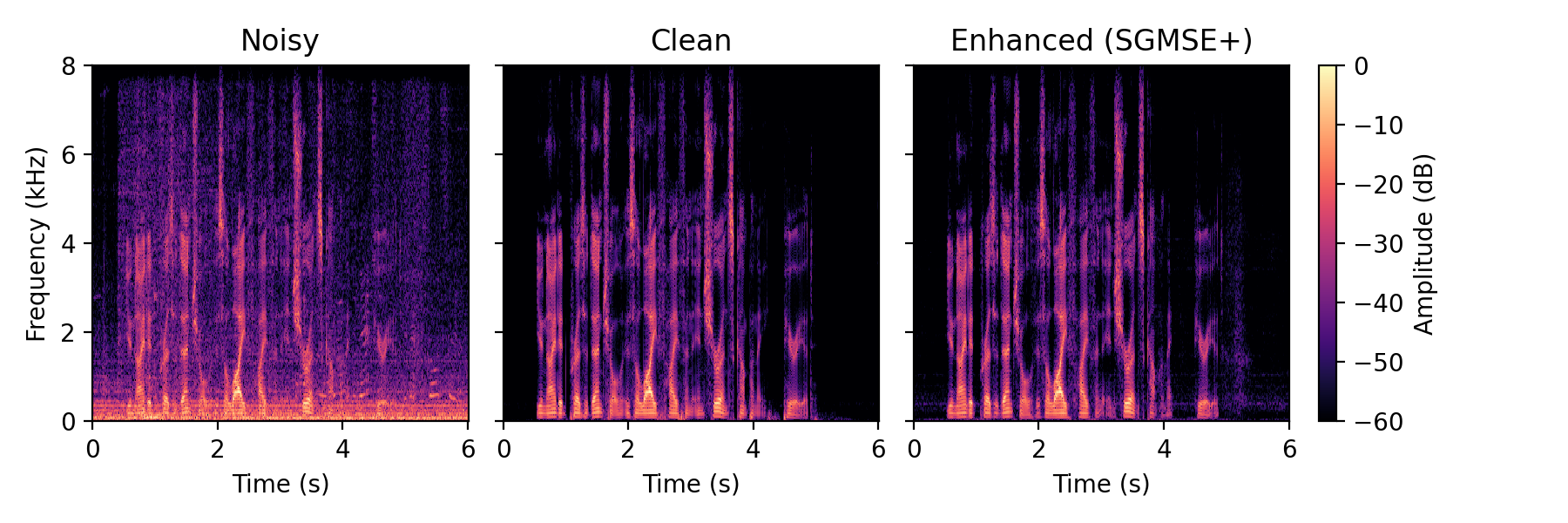
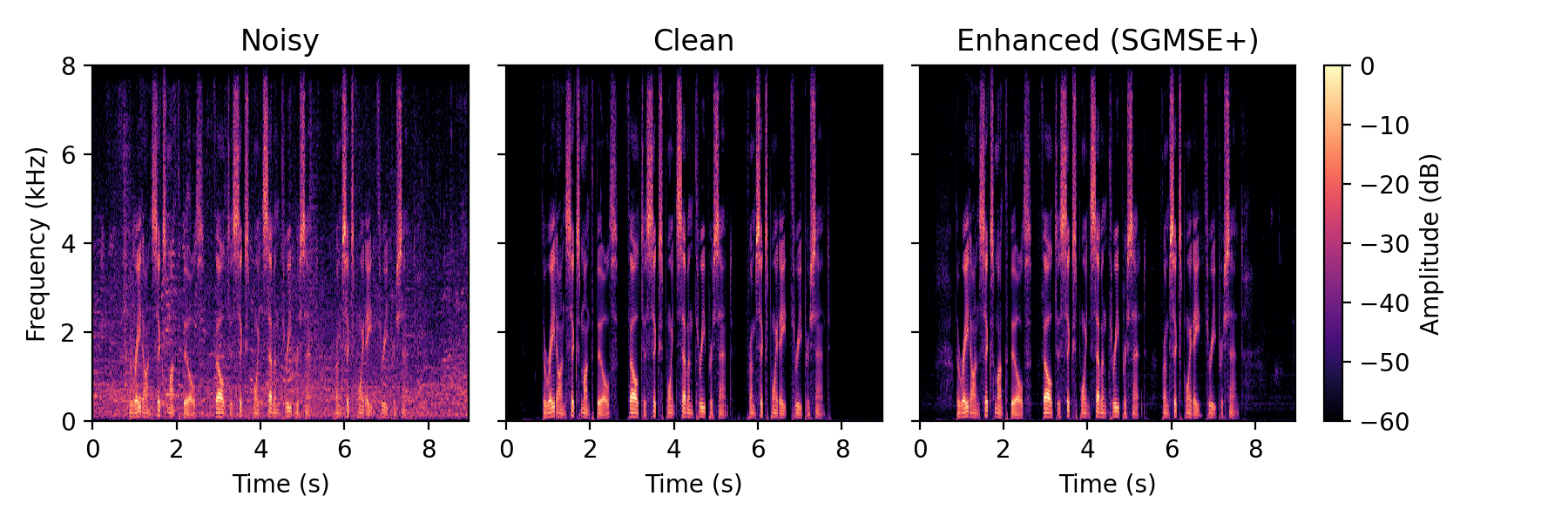
Full method comparison
The methods written in black represent the matched condition, i.e., trained and tested on WSJ0-CHiME3. The grayed out methods represent the mismatched condition, i.e., the model was trained on VoiceBank-DEMAND and tested on WSJ0-CHiME3.
Female speakers:
| Matched? | 441c0204.wav | 445o030y.wav | 444o030c.wav | 445o0308.wav | |
|---|---|---|---|---|---|
| Input SNR | 0.41 dB | 2.56 dB | 4.46 dB | 9.97 dB | |
| Clean | |||||
| Noisy | |||||
| SGMSE+ [2] | ✓ | ||||
| SGMSE+ [2] | ✗ | ||||
| Conv-TasNet [3] | ✓ | ||||
| Conv-TasNet [3] | ✗ | ||||
| MetricGAN+ [4] | ✓ | ||||
| MetricGAN+ [4] | ✗ | ||||
| SGMSE [1] | ✓ | ||||
| SGMSE [1] | ✗ | ||||
| CDiffuSE [5] | ✓ | ||||
| CDiffuSE [5] | ✗ | ||||
| STCN [6] | ✓ | ||||
| STCN [6] | ✗ | ||||
| RVAE [7] | ✓ | ||||
| RVAE [7] | ✗ |
Male speakers:
| Matched? | 440o0304.wav | 447c0201.wav | 447o030t.wav | 440c020v.wav | |
|---|---|---|---|---|---|
| Input SNR | 0.28 dB | 2.54 dB | 4.27 dB | 6.68 dB | |
| Clean | |||||
| Noisy | |||||
| SGMSE+ [2] | ✓ | ||||
| SGMSE+ [2] | ✗ | ||||
| Conv-TasNet [3] | ✓ | ||||
| Conv-TasNet [3] | ✗ | ||||
| MetricGAN+ [4] | ✓ | ||||
| MetricGAN+ [4] | ✗ | ||||
| SGMSE [1] | ✓ | ||||
| SGMSE [1] | ✗ | ||||
| CDiffuSE [5] | ✓ | ||||
| CDiffuSE [5] | ✗ | ||||
| STCN [6] | ✓ | ||||
| STCN [6] | ✗ | ||||
| RVAE [7] | ✓ | ||||
| RVAE [7] | ✗ |
Dereverberation examples
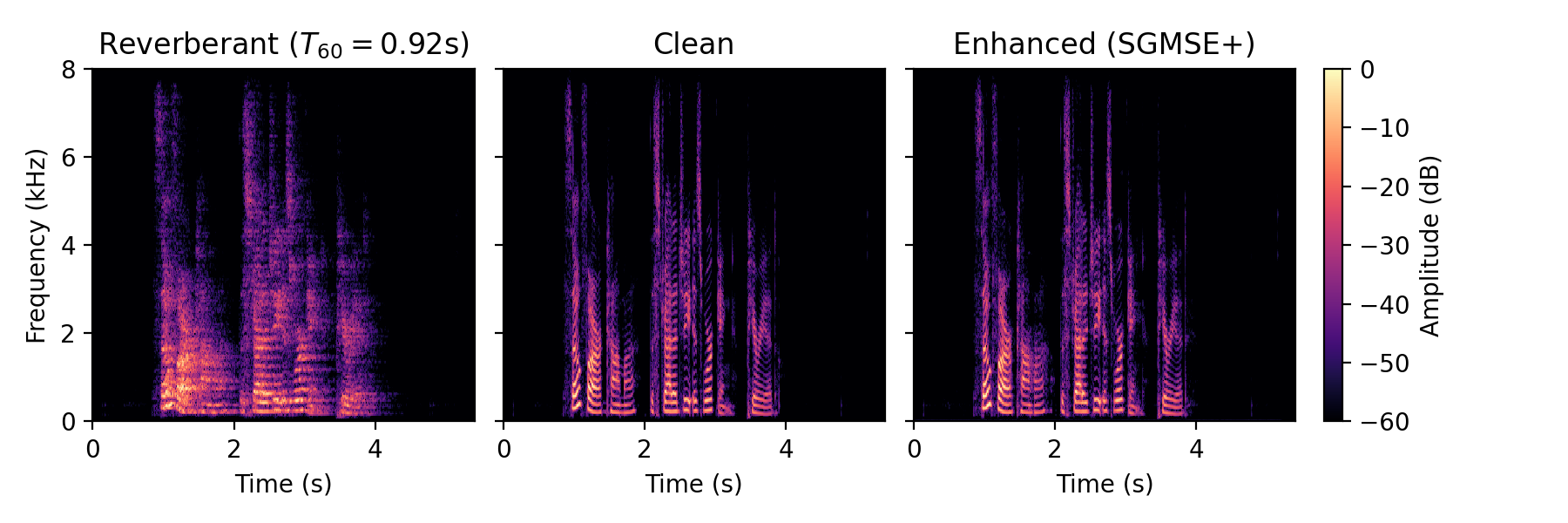
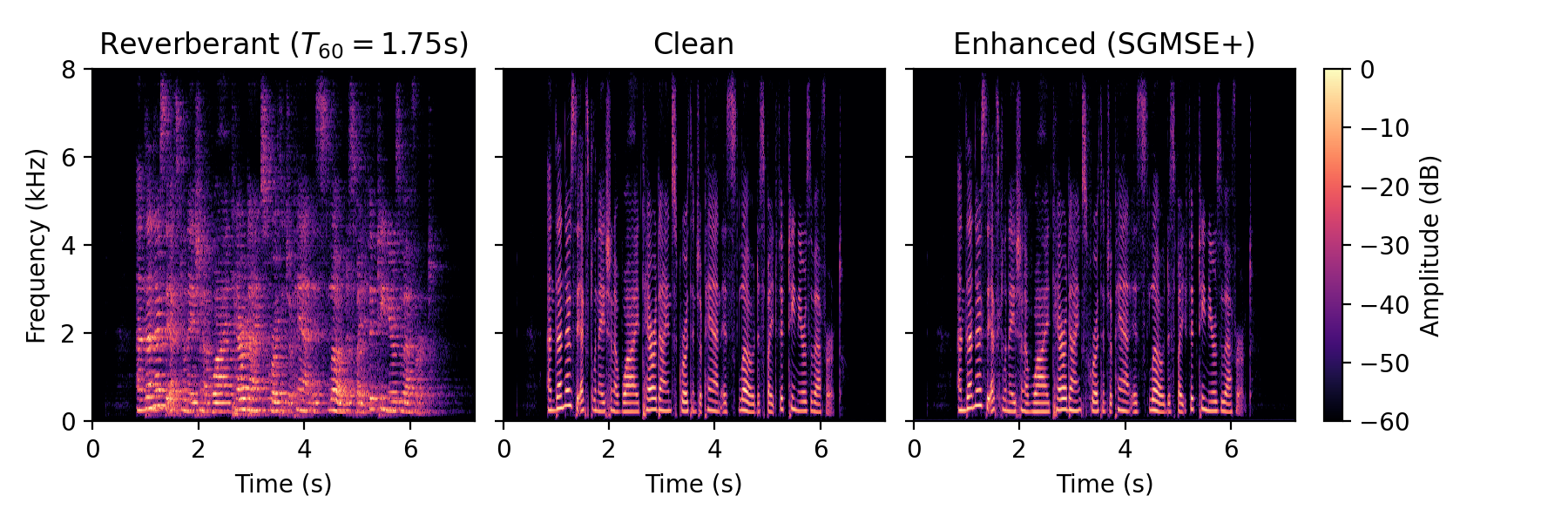
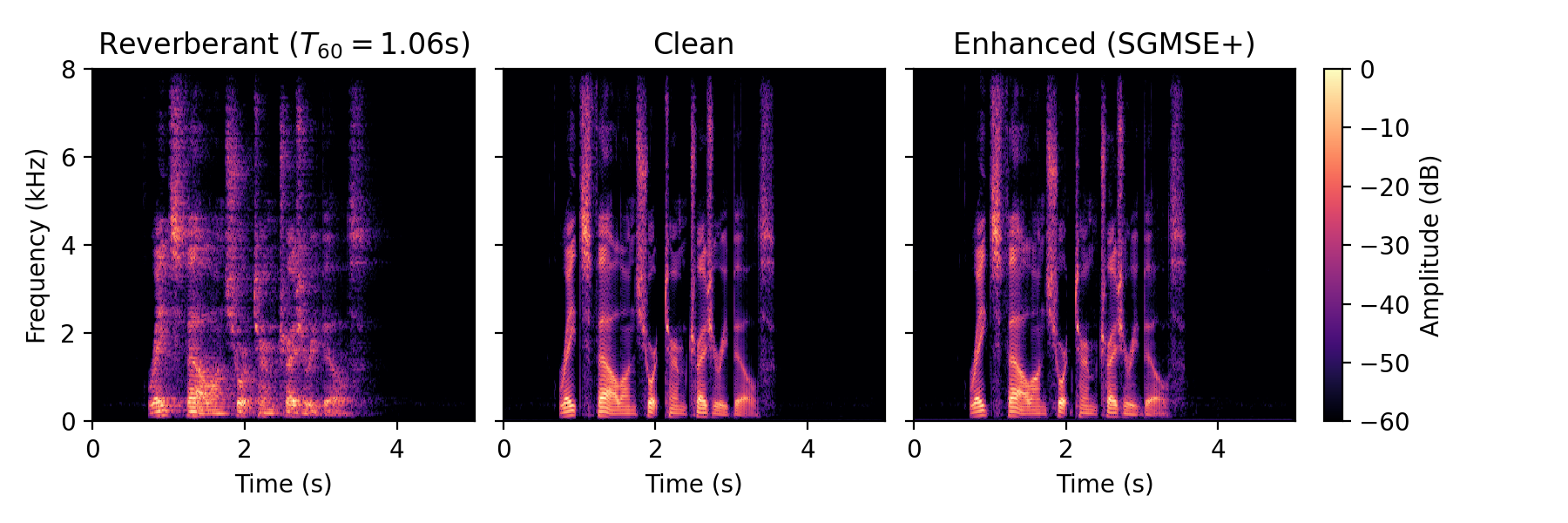
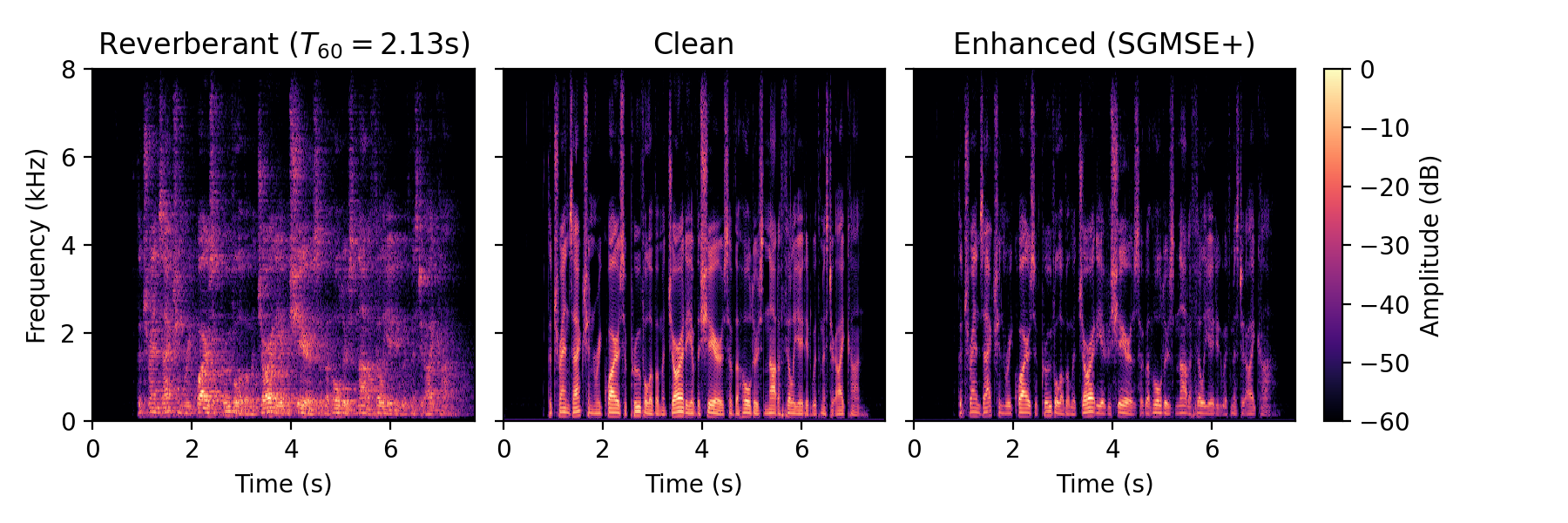
Real data
Speech Enhancement
Examples are taken from the DNS challenge 2020 testset [8].| File name | Noisy | SGMSE+ (WSJ0+CHiME3) | SGMSE+ (VB-DMD) |
|---|---|---|---|
| audioset_realrec_airconditioner_9akKYWm_f9E.wav | |||
| audioset_realrec_airconditioner_DMZAnHsY8e8.wav | |||
| audioset_realrec_babycry_3oS1DK_35z4.wav | |||
| audioset_realrec_barking_Cp9Vfz2viUw.wav | |||
| audioset_realrec_car_00fs8Gpipss.wav | |||
| audioset_realrec_car_1B0WiVPQ7ro.wav | |||
| audioset_realrec_clatter_7KUIyRIW4gM.wav | |||
| audioset_realrec_printer_1wh_xYxrwg8.wav | |||
| audioset_realrec_printer_2BIihAdg5TQ.wav | |||
| ms_realrec_headset_cafe_spk1_3.wav | |||
| ms_realrec_headset_Headphone-cafeteria-spk3-1.wav | |||
| ms_realrec_headset_roger_cafeteria_1.wav | |||
| ms_realrec_speakerphone_Ebrahim_B31Kitchen_S11_SurfaceBook.wav | |||
Dereverberation
Examples are taken from the MC-WSJ-AV testset [9].| File name | Reverberant | SGMSE+ |
|---|---|---|
| AMI_WSJ22-Array1-1_T22c0302.wav | ||
| AMI_WSJ22-Array1-1_T22c0308.wav | ||
| AMI_WSJ23-Array1-1_T23c0309.wav | ||
| AMI_WSJ23-Array1-1_T23c0314.wav | ||
| AMI_WSJ27-Array1-1_T37c030w.wav | ||
| AMI_WSJ28-Array1-1_T38c030v.wav | ||
| AMI_WSJ28-Array1-1_T38c0301.wav | ||
| AMI_WSJ29-Array1-1_T39c030t.wav | ||
| AMI_WSJ29-Array1-1_T39c030w.wav | ||
| AMI_WSJ29-Array1-1_T39c030x.wav | ||
| AMI_WSJ30-Array1-1_T40c0309.wav |
References
[1] Simon Welker, Julius Richter, and Timo Gerkmann. Speech Enhancement with Score-Based Generative Models in the Complex STFT Domain, ISCA Interspeech, Incheon, Korea, Sep. 2022.
[2] Julius Richter, Simon Welker, Jean-Marie Lemercier, Bunlong Lay, and Timo Gerkmann. Speech Enhancement and Dereverberation with Diffusion-Based Generative Models, IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2351 - 2364, 2023.
[3] Yi Luo, and Nima Mesgarani. Conv-TasNet: Surpassing ideal time–frequency magnitude masking for speech separation, IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019.
[4] Szu-Wei Fu, Cheng Yu, Tsun-An Hsieh, Peter Plantinga, Mirco Ravanelli, Xugang Lu, and Yu Tsao. MetricGAN+: An improved version of MetricGAN for speech enhancement, arXiv preprint arXiv:2104.03538, 2021.
[5] Yen-Ju Lu, Zhong-Qiu Wang, Shinji Watanabe, Alexander Richard, Cheng Yu, and Yu Tsao. Conditional diffusion probabilistic model for speech enhancement, IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022.
[6] Julius Richter, Guillaume Carbajal, and Timo Gerkmann. Speech Enhancement with Stochastic Temporal Convolutional Networks, ISCA Interspeech, 2020.
[7] Xiaoyu Bie, Simon Leglaive, Xavier Alameda-Pineda, and Laurent Girin. Unsupervised speech enhancement using dynamical variational auto-encoders, IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 2993 - 3007, 2022.
[8] Chandan Reddy et al. The Interspeech 2020 Deep Noise Suppression Challenge: Datasets, Subjective Testing Framework, and Challenge Results. ISCA Interspeech, 2020.
[9] Mike Lincoln et al. The multi-channel Wall Street Journal audio visual corpus (MC-WSJ-AV): Specification and initial experiments. IEEE Workshop on Automatic Speech Recognition and Understanding, 2005.