Phase-Aware Signal Processing
Single channel speech enhancement algorithms typically rely on the spectro-temporal properties of speech and interferences. To analyze these properties, typically a complex-valued representation, such as the short time discrete Fourier transform (STFT), is employed. The complex-valued STFT coefficients can be represented by their absolute value (referred to in the literature both as STFT magnitude and STFT amplitude) and their phase.
Until recently, in STFT-based speech enhancement, the focus was on modifying only the magnitude of the STFT components, because it was generally considered that most of the insights about the structure of the signal could be obtained from the magnitude, while little information could be obtained from the phase component.
However, with the recent combination of increased expectation towards speech enhancement algorithms and increased computational power of assisted listening and speech communication devices, all options for improvements are back on the table. Therefore, researchers started re-investigating the role of the STFT phase for speech enhancement.
Here we present a growing number of algorithms which either enhance the spectral phase and/or employ phase information for an improved signal processing performance.
After an initial problem statement was published 2012 in [GKR12], an overview paper on our contributions appeared in the IEEE Signal Processing Magazine in 2015 [GKR15].
[GKR15] Timo Gerkmann, Martin Krawczyk-Becker, Jonathan Le Roux, "Phase Processing for Single Channel Speech Enhancement: History and Recent Advances", IEEE Signal Processing Magazine,Vol. 32, No. 2, pp. 55-66, Mar. 2015. [doi]
To summarize, we first proposed an estimator of the clean speech STFT phase in [KG12, KG14]. Note that this phase estimator is not meant to be used directly to exchange the noisy STFT phase. Instead, we first proposed to use the phase as an additional source of information which helps to distinguish noise outliers from speech in MMSE-based clean speech spectral magnitude estimation in [GK13]. Then we proposed to treat the initial phase estimate obtained from [KG14] as uncertain prior information when estimating complex spectral coefficients [G14a, G14b] or amplitudes [KG16c]. For this we proposed to model this uncertainty using a von Mises distribution. For those interested in Bayesian estimation and probabilistic modeling, [G14a] also provides for general models of phase-related priors, likelihoods, and posteriors along with different estimators, including maximum likelihood (ML) and maximum a posteriori (MAP) phase estimators.
Using listening experiments, in [KG16b] we show that our proposed phase-aware speech enhancement may significantly improve the perceived sound quality using listening experiments. In [KG18] we systematically explore in which situations additional information about the clean speech phase is most valuable.
References- [KG18] Martin Krawczyk-Becker, Timo Gerkmann, "A Study on the Benefits of Phase-Aware Speech Enhancement in Challenging Noise Scenarios", Int. Conf. Latent Variable Analysis and Signal Separation (LVA ICA), Guildford, UK, Jul. 2018.
- [KG16c] Martin Krawczyk-Becker, Timo Gerkmann, "On MMSE-Based Estimation of Amplitude and Complex Speech Spectral Coefficients Under Phase-Uncertainty", IEEE/ACM Trans. Audio, Speech, Language Proc., Vol. 24, No. 12, pp. 2251-2262, Dec. 2016. [doi]
- [KG16b] Martin Krawczyk-Becker, Timo Gerkmann, "An evaluation of the perceptual quality of phase-aware single-channel speech enhancement", Journal of the Acoustical Society of America, 140, EL364-EL369, Oct. 2016. [doi]
- [GKR15] Timo Gerkmann, Martin Krawczyk-Becker, Jonathan Le Roux, "Phase Processing for Single Channel Speech Enhancement: History and Recent Advances", IEEE Signal Processing Magazine, Vol. 32, No. 2, pp. 55-66, Mar. 2015. [doi]
- [KG14] Martin Krawczyk, Timo Gerkmann, "STFT Phase Reconstruction in Voiced Speech for an Improved Single-Channel Speech Enhancement", IEEE/ACM Trans. Audio, Speech, Language Proc., Vol. 22, No. 12, pp. 1931-1940, Dec. 2014. [doi]
- [G14a] Timo Gerkmann, "Bayesian estimation of clean speech spectral coefficients given a priori knowledge of the phase", IEEE Trans. Signal Processing, Vol. 62, No. 16, pp. 4199-4208, 15 Aug. 2014. [doi]
- [GK13] Timo Gerkmann, Martin Krawczyk, "MMSE-Optimal Spectral Amplitude Estimation Given the STFT-Phase", IEEE Signal Processing Letters, Vol. 20, No. 2, pp. 129-132, Feb. 2013. [doi]
- [GKR12] Timo Gerkmann, Martin Krawczyk, Robert Rehr, "Phase estimation in speech enhancement - unimportant, important, or impossible?", IEEE Convention of Electrical and Electronics Engineers in Israel, Eilat, Israel, Nov. 2012. [doi]
- [KG12] Martin Krawczyk, Timo Gerkmann, "STFT Phase Improvement for Single Channel Speech Enhancement", Int. Workshop Acoust. Signal Enhancement (IWAENC), Aachen, Germany, Sep. 2012.
Perceptual Evaluation
A pairwise comparison test with 20 participants was conducted using 3 different noise types at 2 SNRs to evaluate speech qualtiy (SQ), noise reduction (NR), and overall preference (OP).
Below, we present the preference score, which is the percentage of pairwise comparisons the respective algorthim won (100% meaning that it was preferred in every comparison it was involved in).Please see the following paper for details:
[KG16b] Martin Krawczyk-Becker, Timo Gerkmann, "An evaluation of the perceptual quality of phase-aware single-channel speech enhancement", Journal of the Acoustical Society of America, 140, EL364-EL369, Oct. 2016. [audio]
Summarized Results:
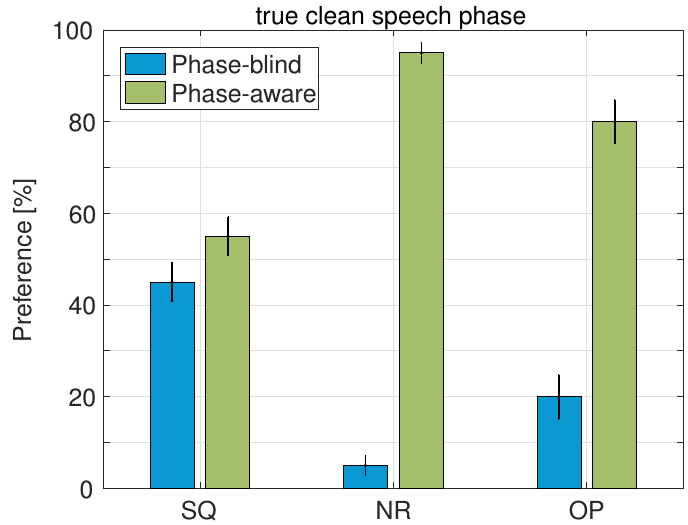
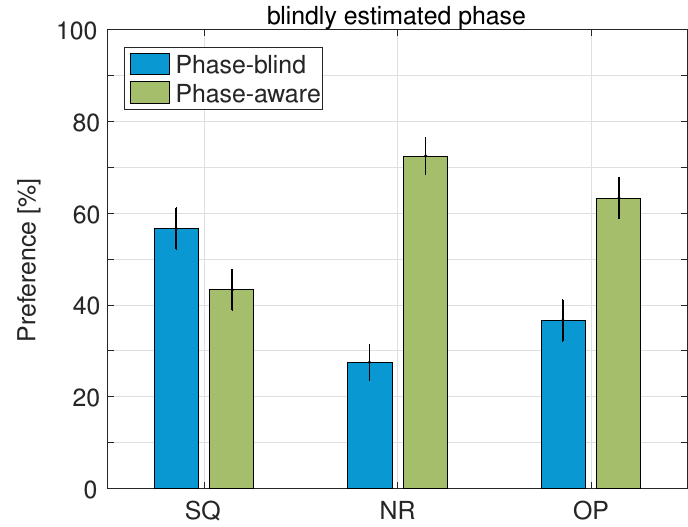
The phase-aware amplitude estimator PAA [GK13] achieved a higher noise reduction and was preferred by the majority of listeners over its conventional phase-blind counterpart STSA, even when the clean speech phase was blindly estimated. The improvements in noise reduction and overall preference are statistically significant and achieved without a significant impact on speech quality.
Phase-aware speech enhancement: audio examples
Here are some audio examples illustrating the power of phase-aware speech enhancement.
For the following audio examples the spectral phase of voiced speechfle sounds is estimated from the noise corrupted recoding using [KG14]. This phase estimate is then used for the phase-aware clean speech amplitude estimator [GK13] up to 4 kHz. At higher frequencies and in unvoiced speech the clean amplitude is estimated using [BKM08], which is the phase-blind counterpart to [GK13]. Furthermore, the estimated amplitude is combined with the estimated phase for signal reconstruction up to 1.5 kHz. As a reference, we also provide the result of a traditional, phase-blind amplitude enhancement scheme [BKM08].
References
[KG14] Martin Krawczyk, Timo Gerkmann, "STFT Phase Reconstruction in Voiced Speech for an Improved Single-Channel Speech Enhancement", IEEE/ACM Trans. Audio, Speech, Language Proc., 2014, Vol. 22, No. 12, pp. 1931-1940, Dec. 2014.
[GK13] Timo Gerkmann, Martin Krawczyk, "MMSE-Optimal Spectral Amplitude Estimation Given the STFT-Phase", IEEE Signal Processing Letters, Vol. 20, No. 2, pp. 129-132, Feb. 2013.
[BKM08] Colin Breithaupt, Martin Krawczyk, Rainer Martin, "Parameterized MMSE spectral magnitude estimation for the enhancement of noisy speech", IEEE Int. Conf. Acoustics, Speech, Signal Processing, Las Vegas, NV, USA, Apr. 2008.
Clean Speech 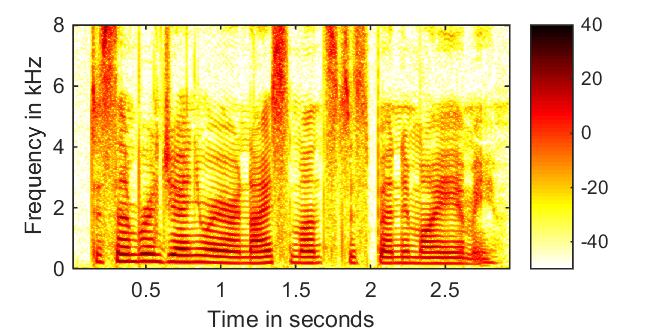 |
Noisy Speech 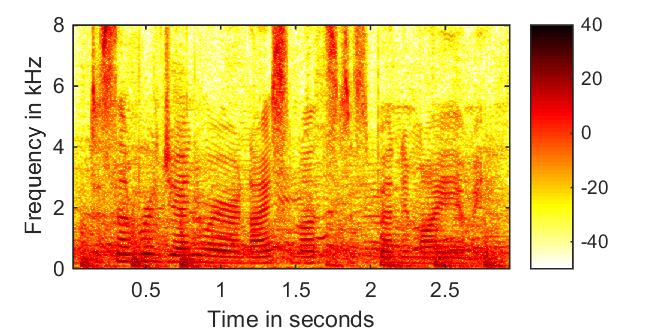 |
phase-aware amplitude + reconstr. phase 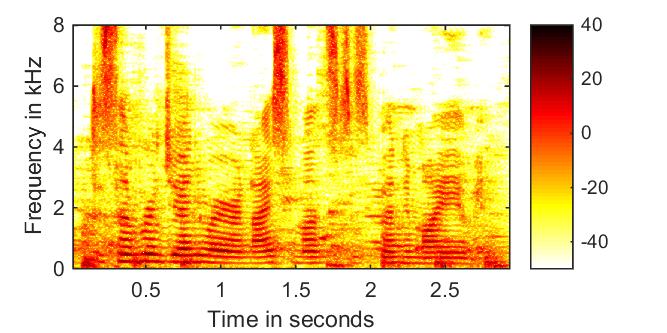 |
phase-aware amplitude + noisy phase 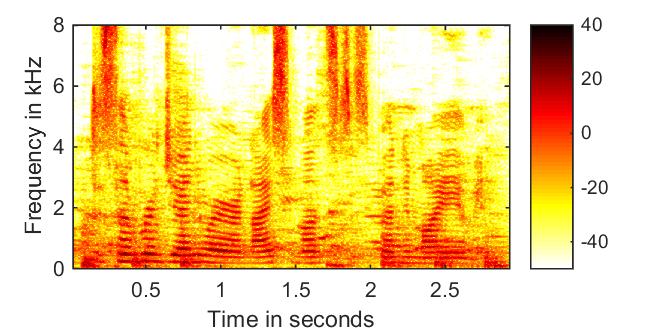 |
phase-blind amplitude + noisy phase 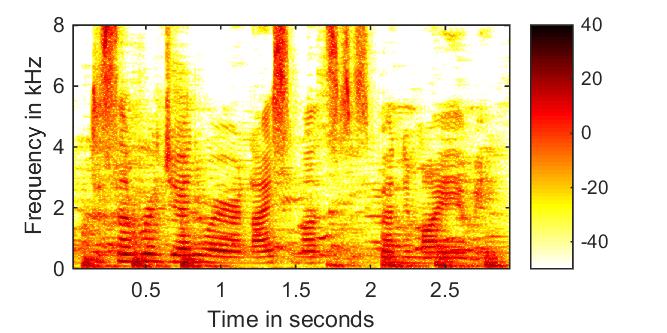 |
Example that illustrates the relevance of the spectral phase
As an illustration emphasizing the power of phase, it is interesting to remark that, from a particular magnitude spectrogram, it is possible to reconstruct virtually any time domain signal with a carefully crafted phase. For instance, one can derive a magnitude spectrogram from that of a speech signal such that it yields either a speech signal similar to the original or a piece of rock music, depending on the choice of the phase. The point here is to exploit the inconsistency between magnitude and phase to make contributions of neighboring frames cancel each other just enough to reconstruct the energy profile of the target sound.
More details and audio examples can be found here.
Reference
[LR11] J. Le Roux, “Phase-controlled sound transfer based on maximally-inconsistent spectrograms,” in Acoustical Society of Japan Spring Meeting, no. 1-Q-51, Mar. 2011.
Phase-Aware Estimation of Complex Spectral Coefficients
A way to jointly estimate magnitudes and phases is to derive a joint MMSE estimator of magnitudes and phases directly in the STFT domain when an uncertain initial phase estimate is available. This phase-aware complex estimator is referred to as the Complex estimator with Uncertain Phase (CUP) [G14a,G14b]. The initial phase estimate can be obtained by an estimator based on signal characteristics, such as the sinusoidal model based approach [KG14]. The resulting magnitude estimate is a non-linear trade-off between a phase-blind and a phase-sensitive magnitude estimator, while the resulting phase is a trade-off between the noisy phase and the initial phase estimate. These trade-offs are controlled by the uncertainty of the initial phase estimate, avoid processing artifacts and lead to an improvement in predicted speech quality [G14a].
Audio examples can be found here.
Reference
[G14a] Timo Gerkmann, "Bayesian estimation of clean speech spectral coefficients given a priori knowledge of the phase", IEEE Trans. Signal Processing, Vol. 62, No. 16, pp. 4199-4208, Aug. 2014.
[G14b] Timo Gerkmann, “MMSE-optimal enhancement of complex speech coefficients with uncertain prior knowledge of the clean speech phase,” in IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), Florence, Italy, May 2014.
Phase-Aware Spectral Amplitude Estimation
An estimate of the speech phase, e.g. obtained using a harmonic-model [KG14], can also be employed as additional information in speech amplitude estimation. For this, we derive an optimal Bayesian estimator of the clean speech spectral amplitudes when the clean speech phase is given. We show that the additional information of the phase provides new means to distinguish between noise outliers and speech.
More details and audio examples can be found here.
A unified view on phase-aware and phase-blind estimators of complex and amplitude speech coefficients is given in [KG16c].
Reference
[GK13] Timo Gerkmann, Martin Krawczyk, "MMSE-Optimal Spectral Amplitude Estimation Given the STFT-Phase", IEEE Signal Processing Letters, Vol. 20, No. 2, pp. 129-132, Feb. 2013.
[KG16c] Martin Krawczyk-Becker, Timo Gerkmann, "On MMSE-Based Estimation of Amplitude and Complex Speech Spectral Coefficients Under Phase-Uncertainty", IEEE/ACM Trans. Audio, Speech, Language Proc., Vol. 24, No. 12, pp. 2251-2262, Dec. 2016.
Extended Evaluation of Phase-Aware Enhancement in Challenging Noise Scenarios
To assess the potential benefit of phase-aware speech enhancement in more detail, in [KG18] we systematically explore in which situations additional information about the clean speech phase is most valuable. For this, we compare the performance of phase-aware and phase-blind clean speech estimators in different noise scenarios, i.e. at different signal to noise ratios (SNRs) and for noise sources with different degrees of stationarity. Interestingly, the results indicate that the greatest benefits can be achieved in situations where conventional magnitude-only speech enhancement is most challenging, namely in highly non-stationary noises at low SNRs.
[KG18] Martin Krawczyk-Becker, Timo Gerkmann, "A Study on the Benefits of Phase-Aware Speech Enhancement in Challenging Noise Scenarios", Int. Conf. Latent Variable Analysis and Signal Separation (LVA ICA), Guildford, UK, Jul. 2018. [doi]
Harmonic Model Based Phase Estimation
With the help of a harmonic model, the STFT phase of clean voiced speech sounds is estimated based only on a noisy observation and an estimate of the fundamental frequency. These phase estimates are for example employed for phase-aware spectral amplitude estimation and the estimation of the complex clean speech spectral coefficients.
Code and audio examples can be found here.
Reference
[KG14] Martin Krawczyk, Timo Gerkmann, "STFT Phase Reconstruction in Voiced Speech for an Improved Single-Channel Speech Enhancement", IEEE/ACM Trans. Audio, Speech, Language Proc., 2014, Vol. 22, No. 12, pp. 1931-1940, Dec. 2014
[KG12] Martin Krawczyk, Timo Gerkmann, "STFT Phase Improvement for Single Channel Speech Enhancement", Int. Workshop Acoust. Signal Enhancement (IWAENC), Aachen, Germany, Sep. 2012.
Consistent Wiener Filtering
While a classical Wiener filter changes only the magnitudes in the STFT domain, separately for each time-frequency point, the consistent Wiener filter takes the relationship between STFT coefficients across time and frequency into account, which modifies both the magnitude and the phase of the noisy observation to obtain the separated speech. Optimization is performed directly on the signal in the time domain or jointly on phase and magnitude in the complex time-frequency domain, through a conjugate gradient method with a well-chosen preconditioner. Thanks to this joint optimization, the consistent Wiener filter can lead to significantly better separation performance compared to the classical Wiener filter and other methods that rely on variance estimates to reconstruct speech.
More details and code can be found here.
Some audio examples can be found here.
Reference
[LRV13] J. Le Roux and E. Vincent, “Consistent Wiener filtering for audio source separation,” IEEE Signal Processing Letters, vol. 20, no. 3, pp. 217–220, Mar. 2013.