Traditional Speech Enhancement
Introduction
Speech is one of the most natural forms of communication for human beings and poses an effective tool to exchange ideas or to express needs and emotions. Due to technical advances, speech communication is no longer restricted to face-to-face conversations but is also performed over long distances, e.g., in the form of telecommunications, or is even used as a natural way for human-machine interaction. As computationally powerful computer hardware has become available to many users, the number of speech processing devices such as smart phones, tablets and notebooks has increased. As a consequence, speech plays an important role in many applications, e.g., hands-free telephony, digital hearing aids, speech-based computer interfaces, or home entertainment systems.
With the increasing usage of mobile devices, also the demand for processing algorithms is constantly increasing. In many speech processing applications, one or more microphones are used to capture the voice of the targeted speaker. As the microphones are often placed at a considerable distance from the target speaker, e.g., in hearing aids or hands-free telephony, the received signal does not only contain the sound of the target speaker, but possibly also sounds of other speakers or background noises. Understanding speech becomes increasingly difficult, if additional sounds interfere with the desired speech sound, especially with increasing level of the interferers. Also moderate amounts of background noise that may not effect the intelligibility can reduce the perceived quality of speech.
To improve the quality and, if possible, also the intelligibility of a noisy speech signal, speech enhancement algorithms are employed. Speech enhancement can be separated in spatial filtering and spectral filtering. In spatial filtering, interfering sounds are reduced based on their spatial properties, while signals from a target direction are maintained. Spectral filtering algorithms, also known as single-channel speech enhancement, process noisy speech signals captured by a single microphone or the output of a beamformer or spatial filtering algorithm. Many approaches to enhance single-channel signals are based on the short-time Fourier transform (STFT). In the following sections, we give an overview over this approach and our contributions.
Speech Enhancement in the Fourier domain
In this section, a general STFT-based speech enhancement procedure is presented, which is shared among many single-channel enhancement algorithms. If speech is recorded in a noisy acoustic environment, e.g., as shown in Figure 1, the employed microphone does not only capture the clean speech time-domain signal \({{s}_{t}}\) but also the background noise signal \({{n}_{t}}\). Here, \({t}\) is the sample index. Under some mild constraints, the interaction of sound waves is physically well described by their superposition as shown in Figure 1.
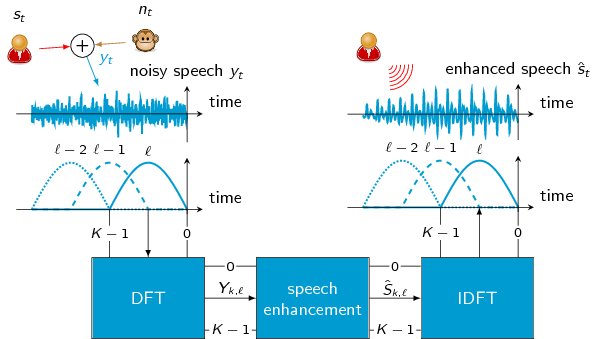
Figure 1: Block diagram of a speech enhancement algorithm operating in the STFT domain
As speech is known to be non-stationary, i.e., the speech sounds change considerably over time, the noisy input signal is split into short overlapping time segments. Each segment of the input signal is transformed to the frequency domain using the discrete Fourier transform (DFT) which results in the STFT. The aim of speech enhancement algorithms is to find an estimate of the clean speech coefficients \({\hat{{S}}_{{{k}, {\ell}}}}\) from the noisy observations \({{Y}_{{{k}, {\ell}}}}\) in the spectral domain. Here, \({k}\) is the frequency index and \({\ell}\) is the segment index. Most spectral clean speech estimators can be written in the form \[ {\hat{{S}}_{{{k}, {\ell}}}}= {{G}_{{{k}, {\ell}}}}{{Y}_{{{k}, {\ell}}}}, \] where \({{G}_{{{k}, {\ell}}}}\) is the so-called gain function. Often, the gain function is real-valued as many statistical models of the clean speech coefficients do not provide prior knowledge about the phase. Further, many algorithms estimate only the magnitude \({{A}_{{{k}, {\ell}}}}= |{{S}_{{{k}, {\ell}}}}|\) of the clean speech signal. In these cases, the enhanced speech magnitude \({\hat{{A}}_{{{k}, {\ell}}}}\) is often combined with the phase of the noisy observation \({{\Phi}^{y}_{{{k}, {\ell}}}}\) as \[ {\hat{{S}}_{{{k}, {\ell}}}}= {\hat{{A}}_{{{k}, {\ell}}}}\exp(j {{\Phi}^{y}_{{{k}, {\ell}}}}). \] We discuss approaches that exploit or modify the phase here. After estimating the clean speech spectrum \({\hat{{S}}_{{{k}, {\ell}}}}\), the time-domain signal is resynthesized using the inverse STFT. This step is also often referred to as overlap-add.
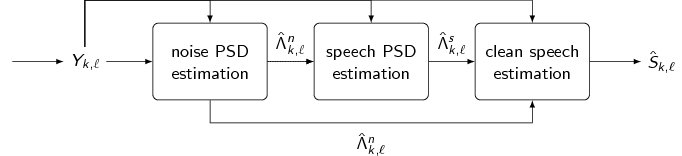
Figure 2: Block diagram of the spectral enhancement procedure
Figure 2 shows the general layout of the spectral speech enhancement step. Most clean speech estimators are derived in a statistical framework and require an estimate of the clean speech power spectral density (PSD) \({\hat{\Lambda}^{s}_{{{k}, {\ell}}}}\) and the noise PSD \({\hat{\Lambda}^{n}_{{{k}, {\ell}}}}\). Both quantities are commonly estimated blindly from the noisy observation \({{Y}_{{{k}, {\ell}}}}\). First, the noise PSD \({\hat{\Lambda}^{n}_{{{k}, {\ell}}}}\) is estimated which is used to estimate the speech PSD \({\hat{\Lambda}^{s}_{{{k}, {\ell}}}}\). Both PSD estimates are used to determine the gain function which is used to estimate the clean speech coefficients.
For the estimation of the speech and noise PSDs, non-machine-learning methods can be employed. Based on the assumption, that the background noise changes more slowly than speech, carefully designed algorithms have been proposed for this application. However, also machine-learning approaches can be used to obtain these quantities, where the properties of speech and noise are learned from representative data before the enhancement step.
Our research concerns all parts of the block diagram in Figure 2. Our solutions are based on statistical models and Bayesian theory or employ neural network based machine-learning methods.