Variational Autoencoders for Speech Enhancement
The variational autoencoder (VAE) is a powerful deep generative model that is currently extensively used to represent high-dimensional complex data via a low-dimensional latent space learned in an unsupervised manner. Recently, the standard VAE has been successfully used to learn a probabilistic prior over speech signals, which is then used to perform speech enhancement [1-2].
Our research aims at improving robust unsupervised speech enhancement algorithms based on the VAE. This can be obtained by:
- conditioning the VAE on a label describing a speech attribute (e.g. speech activity) [8-9]
- noise-aware training [10]
- incorporating temporal dependencies [11]
- incorporating information from other modalities, such as vision [9]
Introduction
The task of single-channel speech enhancement consists in recovering a speech signal from a mixture signal captured with one microphone in a noisy environment. Common speech enhancement approaches estimate the speech signal using a filter in the time-frequency domain to reduce the noise signal while avoiding speech artifacts. Under the Gaussian assumption, the optimal filter in the minimum mean square error sense requires estimating the signal variances.
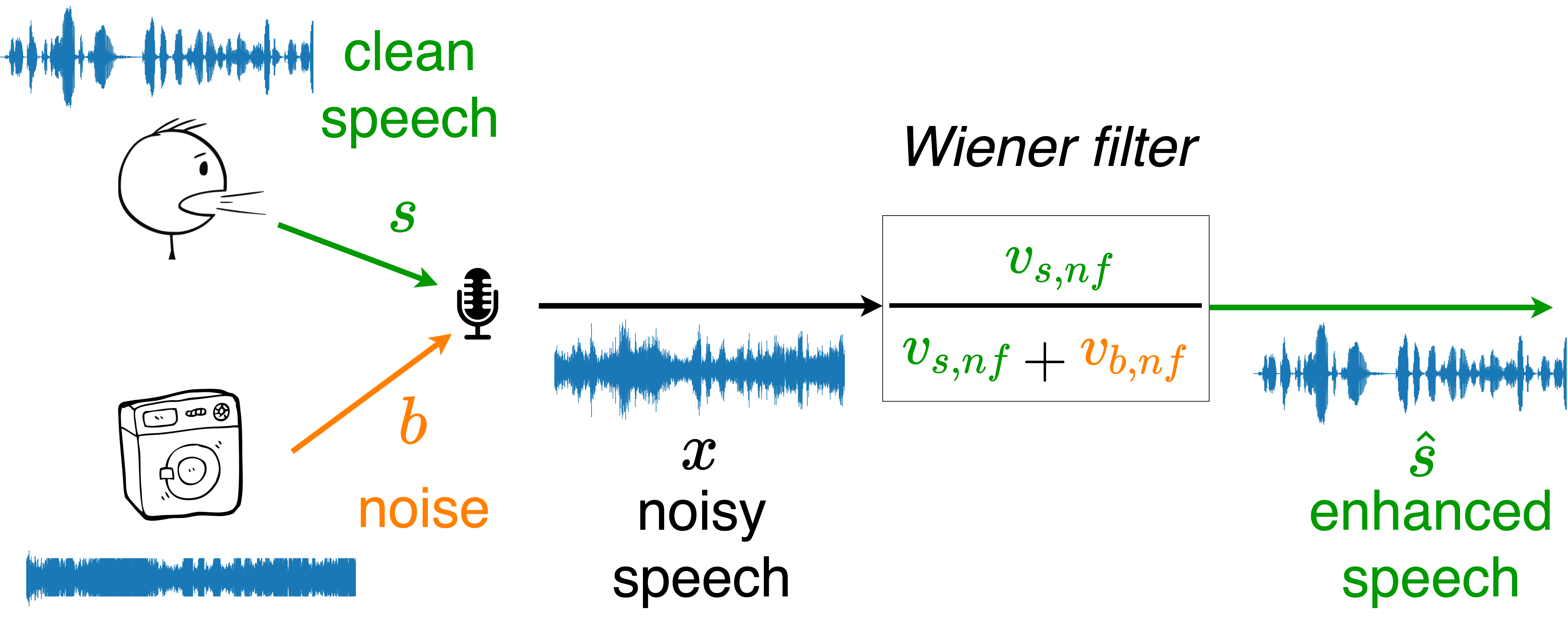
Supervised deep neural networks (DNNs) have demonstrated excellent performance in estimating the speech signal. Supervised approaches require labelled data which originates from pairs of noisy and clean speech. These pairs can be created synthetically. However, since supervised approaches may not generalize well to unseen situations, a large number of pairs is needed to cover various acoustic conditions, e.g. different noise types, reverberation and different signal-to-noise ratios (SNRs).

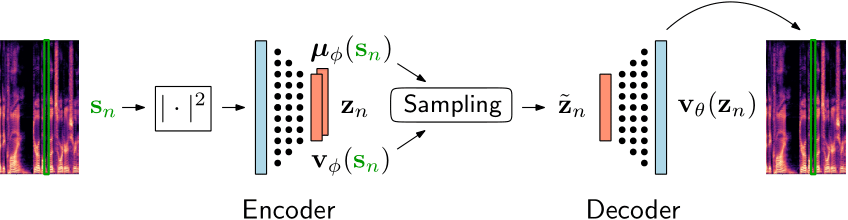
Recently, deep generative models based on the VAE have gained attention for learning the probability distribution of complex data. VAEs have been used to learn a prior distribution of clean speech, and have been combined with an untrained non-negative matrix factorization (NMF) noise model to estimate the signal variances using a Monte Carlo expectation maximization (MCEM) algorithm [1-2]. However, since the VAE speech model is trained in an unsupervised manner on clean speech only, its ability of extracting speech characteristics from noisy speech is limited in low SNRs. This results in limited speech enhancement performance compared to supervised approaches in already-seen noisy environments [1].
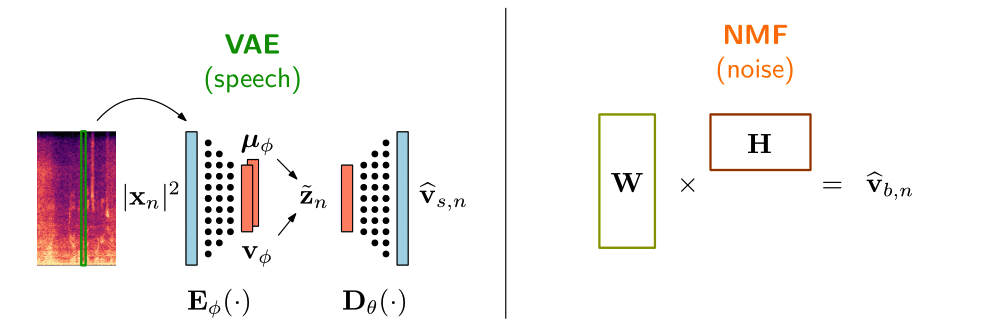
Conditional VAE
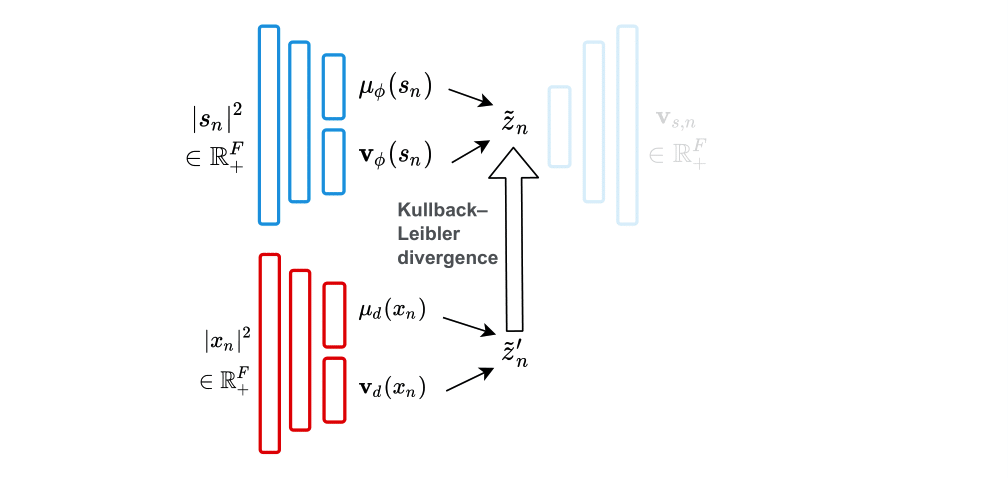
An increased robustness of the VAE can be obtained by conditioning the VAE on a label describing an attribute of the data that allows for a more explicit control of data generation [3]. For various speech-related tasks, VAEs have been conditioned on a label describing a speech attribute, such as speaker identity [4-5] or phonemes [5].
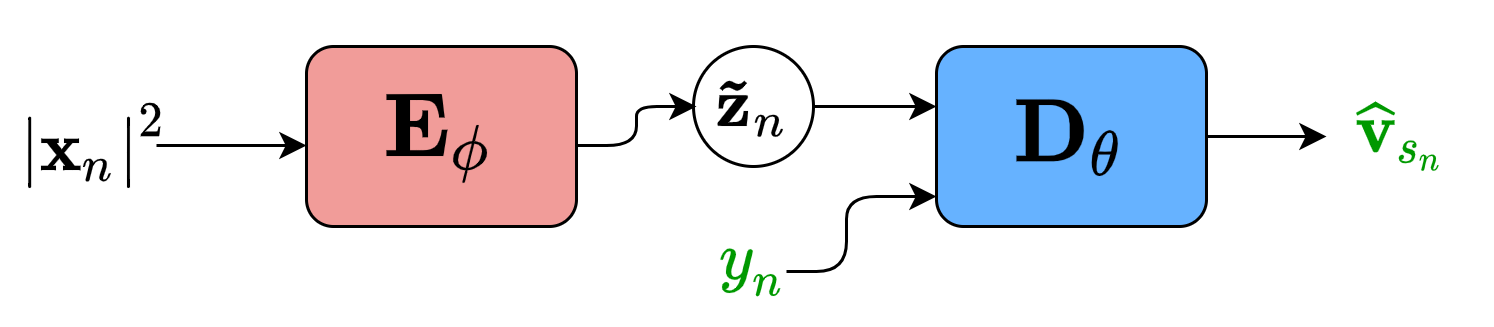
For speaker-independent speech enhancement, we proposed to condition the VAE on a label y describing speech activity [8]. The label y describes either voice activity detection or the ideal binary mask (i.e. voice activity detection per frequency bin) We estimated the label y with a classifier fully decoupled from the VAE. The classifier is trained separately in a supervised manner with pairs of noisy and clean speech.

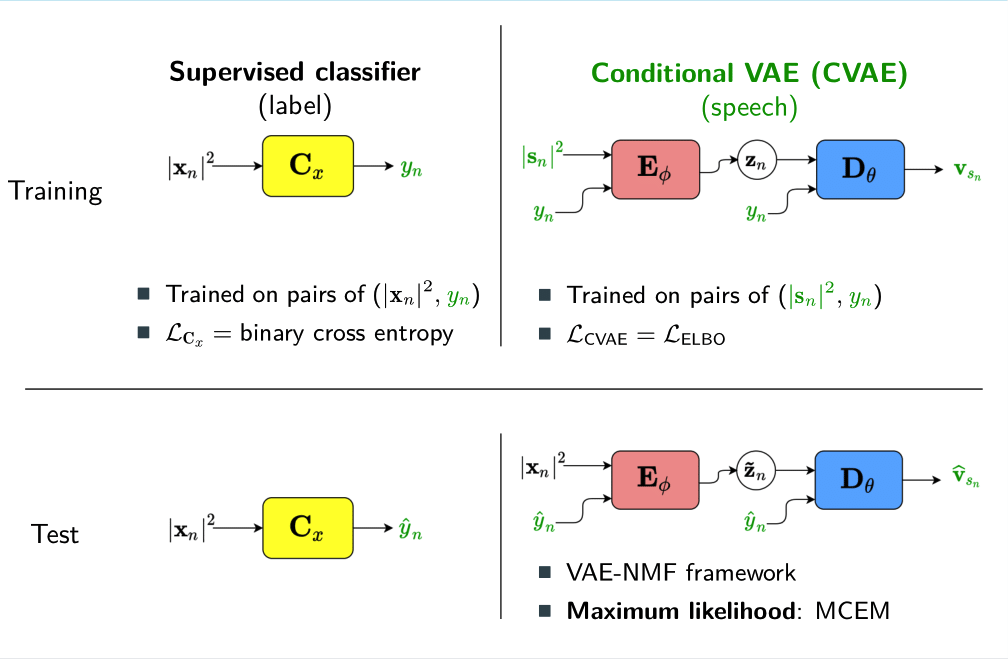
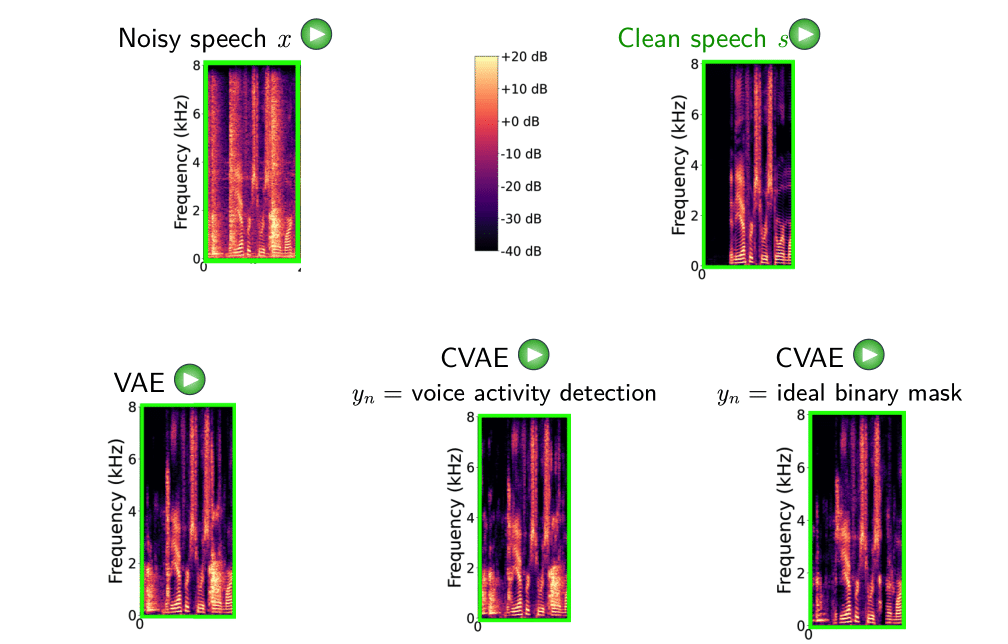
We evaluated our method with labels corresponding to voice activity detection and ideal binary mask on real recordings of different noisy environments. Using the ideal binary mask as label and a feedforward DNN classifier, the conditional VAE outperforms the standard VAE particularly in low SNRs [8].
Ideally, the label should be independent from the other latent dimensions to obtain an explicit control of speech generation. However, the semi-supervised learning of conditional VAEs does not guarantee that it will promote independence between the label and the other latent dimensions. As a result, speech generation can only partially be controlled by the label.

Disentanglement learning aims at making all the dimensions of the latent distribution independent from each other, e.g. by holding different axes of variation fixed during training. Semi-supervised disentanglement approaches, on the other hand, tackle the problem of making only some observed (often interpretable) variations in the data independent from the other latent dimensions which themselves remain entangled [3].
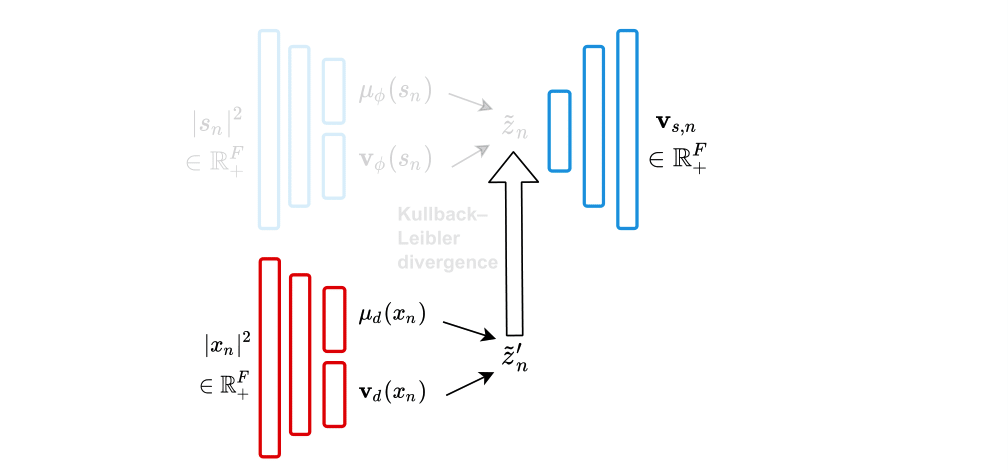
Inspired by recent work on semi-supervised disentanglement learning [6-7], we proposed to use an adversarial training scheme on the latent space to disentangle the label y from the latent variable z [9]. At training, we use a discriminator that competes with the encoder of the VAE. The discriminator aims at identifying the label from the other latent dimensions, whereas the encoder aims at making it unable to estimate the label. Simultaneously, we also use an additional encoder that estimates the label for the decoder of the VAE, which proves to be crucial to learn disentanglement during training.
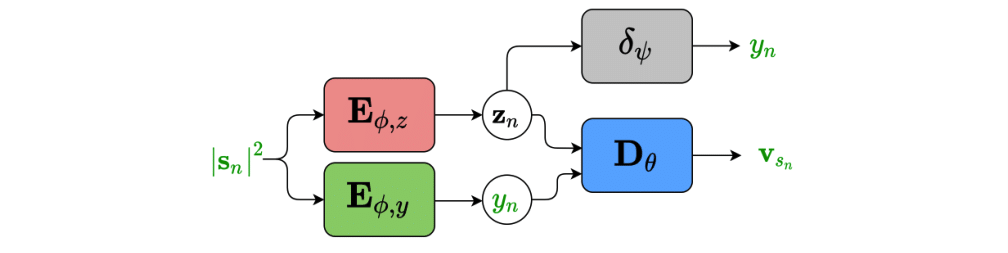



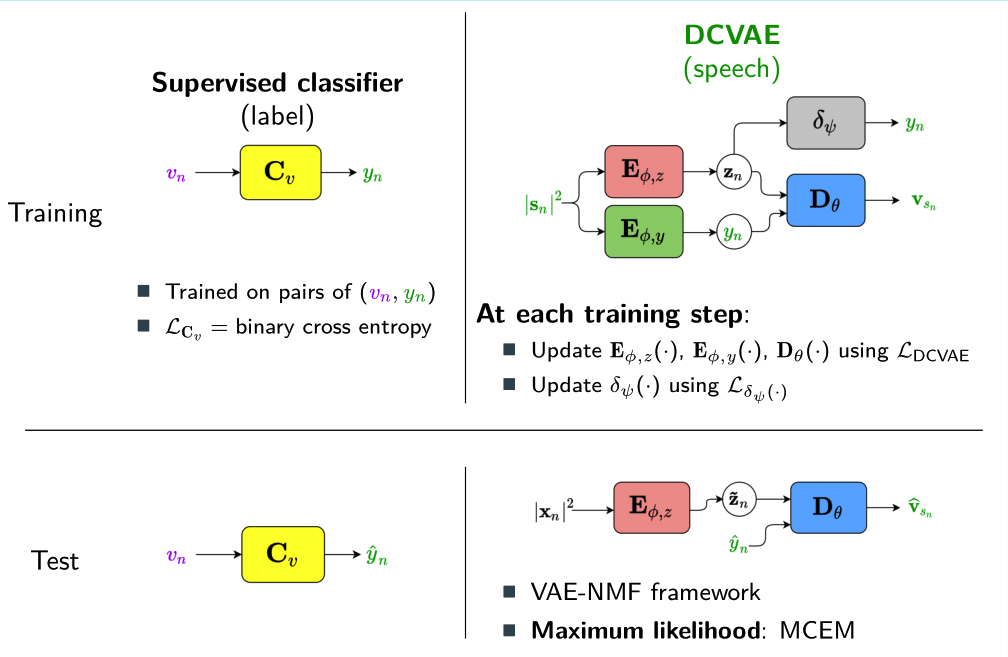
We showed the beneficial effect of learning disentanglement when reconstructing clean speech from noisy speech. In the presence of nonstationary noise, the proposed approach outperforms the standard and conditional VAEs, both trained using the ELBO as loss function, in terms of SI-SDR. Our proposed approach is particularly interesting for audio-visual speech enhancement, where speech activity can be estimated from visual information, which is not affected by the noisy environment.
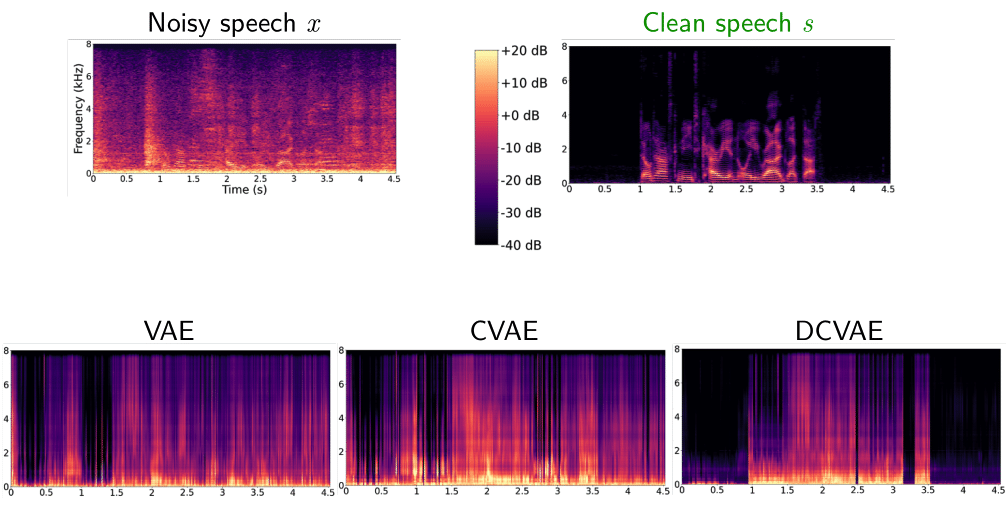
Noise-aware training
An increased robustness of the VAE can be obtained by replacing the encoder of the VAE by a noise-aware encoder [10]. To learn this encoder, the VAE is first trained on clean speech spectra only.
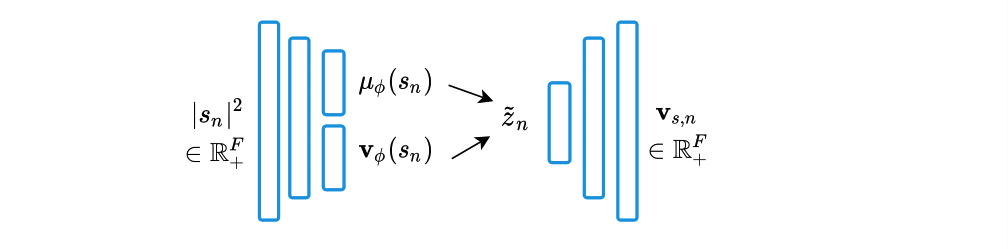
Then, given pairs of clean and noisy speech, the proposed noise-aware encoder is trained in a supervised fashion to make its latent space as close as possible to that of the first speech-only trained encoder.