On the Importance of Super-Gaussian Speech Priors for Machine-Learning Based Speech Enhancement
The sound examples on this page demonstrate the effectiveness of super-Gaussian estimators for machine-learning spectral envelope based speech enhancement schemes.
Here, the pre-trained speech model represents only the spectral envelope envelope of speech but not its fine structure, e.g., the fundamental frequency and its harmonics.
Super-Gaussian estimators exhibit the capability to reduce the background noise even if the speech power spectral density is overestimated, e.g., between harmonics in a spectral envelope model.
Note that the employed DNN based enhancement scheme and the NMF based enhancement scheme are used as examples that employ spectral envelopes.
In the following examples the terms super-Gaussian and Gaussian refer to the following configurations of MOSIE:
Gaussian: μ = 1, β = 1
super-Gaussian: μ = 0.2, β = 1
The minimum gain is set to -12 dB.
Listening Test
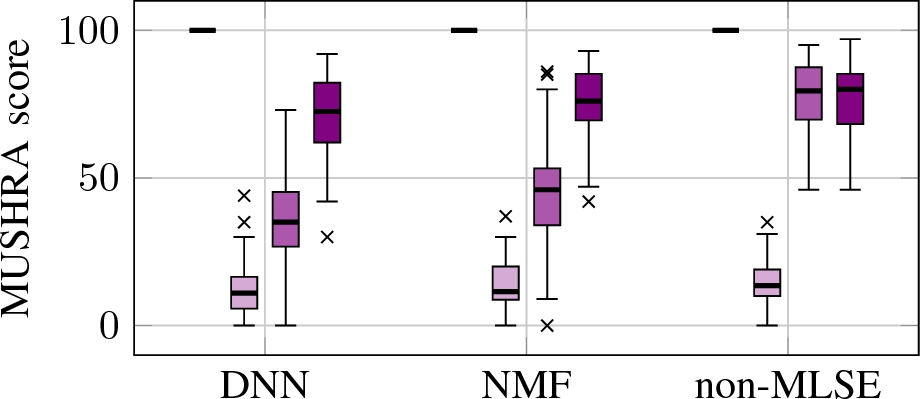
The figure above shows the results of the MUSHRA based listening test using box plots.
In this experiment, the sound examples given below have been rated on a scale from 0 to 100 by 13 participants.
In addition, to the sound examples below the participants were presented a reference and an anchor signal where the reference had to be rated with 100.
The upper and the lower edge of the box show the upper and lower quartile while the bar within the box is the median.
The upper whisker reaches to the largest data point that is smaller than the upper quartile plus 1.5 times the interquartile range.
The lower whisker is defined analogously.
The participants were able to detect the reference while the anchor was given the lowest results.
For the non-MLSE based approaches, there is only a little difference between Gaussian and super-Gaussian estimatosr.
For MLSE based enhancement schemes, the results show that super-Gaussian estimators are rated significantly higher as Gaussian estimators.
Example From Listening Experiment, Traffic Noise, 5 dB SNR