Doctoral Projects
Tom Weber: Error Mitigation for Quantum Computing
While quantum computers are expected to surpass their classical counterparts in the future, current devices are prone to high error rates. Methods to reduce the impact of these errors are crucial to enable reliable quantum computations. Quantum error mitigation can improve computational results significantly but rely on knowledge about the dominant types of error in the system. Noise models offer a means to represent these errors mathematically. Our research in this project focusses on constructing noise models and benchmarking their quality.
Ongoing doctoral project, since 2020, in cooperation with DASHH (Project “Quantum Explorer”)
Contact: Tom Weber
Supervision: Matthias Riebisch/André van Hoorn & Kerstin Borras (DESY, RWTH Aachen)
Marion Wiese: Sustainably establishing a technical debt management process
In our previous interview study, we found that IT managers
- think that technical debt management (TDM) is an important topic,
- concede that establishing a TDM process is their duty and
- have the capabilities in form of budget and time responsibility to establish such a process.
However, non of our interviewees had a TDM process set up. This is called a status quo bias, i.e. a cognitive bias that presents itself as an irrational preference for maintaining the current state of things.
The aim of this project is to develop and evaluate in practice a guideline that describes how to create and maintain awareness of TD and how to implement a TDM process. The guideline should combine the individual TD activities (recognizing, recording, prioritizing, repaying, etc.) into a sustainable TDM and be transferable to different contexts (companies, meeting structures and issue trackers), with a focus on agile companies/teams and a collaborative design of the TDMprocess.
RESEARCH QUESTIONS:
- How can a TDM be established sustainably?
a. What steps are necessary for this?
b. What obstacles are there and how can they be circumvented?
c. What are the similarities and differences in different companies/contexts? - Can the introduction of a TDM raise awareness of TD?
a. What impact does the TDM have on which stakeholders?
b. Are there differences in different companies/contexts? - What effects, e.g. prevention of TD, discussion culture, decision-making, etc., does a TDM have?
To answer these research question, I will perform action research studies in three teams of three different companies introducing a TDM process in five steps. Each step includes a workshop to make decisions based on the teams preferences, follow-up action, and evaluations of the actions effects. Based on these results, I will then create a guideline (possibly an online course) on how to establish a TDM process and evaluate this on two more teams from the same companies.
This project is funded by the Federal Ministry of Education and Research of Germany as part of the Software Campus.
Ongoing doctoral project, since 2020
Contact: Marion Wiese
Supervision: Matthias Riebisch/André van Hoorn/Eva Bittner
Leif Bonorden: Supporting API Deprecation Processes
Deprecation is a mechanism to discourage using an API element – often because it will be dropped in an upcoming version.
Despite the increasing popularity and importance of remote APIs, research, and tool support in the context of deprecation have been focused on static APIs. Furthermore, suppliers and clients of APIs are usually considered distinctly, although both are involved in deprecation and deprecation processes.
This project aims to
- look at deprecation in its entirety – building a model that considers suppliers and clients jointly,
- support deprecation processes for remote APIs – testing and evaluating new mechanisms for clients and suppliers,
- assist related processes – preventing deprecation if possible, and documenting deprecation if necessary.
Ongoing doctoral project, since 2019
Contact: Leif Bonorden
Supervision: Matthias Riebisch†/André van Hoorn†/Janick Edinger & Justus Bogner
Sebastian Frank: Specification and Comprehension of Change in Microservice-Based Software Systems
Microservice-based systems are exposed to transient behavior caused, for example, by (frequent) deployments, failures, or self-adaption. While microservice-based software systems aim to be resilient to changes, precisely specifying resilience requirements is challenging, as transient behavior is complex and subject to uncertainty. The vision of this project is a process of continuous resilience requirement specification, verification, and refinement at runtime, which assists software architects in understanding their system and continuously improves the quality and quantity of the specified resilience requirements.
In particular, this project aims to:
- Provide an interactive method for specifying testable resilience scenarios
- Generate knowledge through method-agnostic, specification-driven resilience assessment (chaos experiments, simulation, monitoring)
- Assist architects in interactive elicitation and refinement of resilience scenarios through refinement strategies, e.g., modifying parameters in resilience scenarios
- Provide visual support in comprehension of the relation between transient behavior and resilience scenarios
Ongoing doctoral project, since 2019
Contact: Sebastian Frank
Supervision: André van Hoorn
Paula Rachow: Refactoring Decision Support for Developers and Architects based on Architectural Impact
Refactorings are key activities for achieving sustainable software systems. However, refactorings demand high effort and features are often deemed more important. The time pressure to deliver is always high and to select important refactorings, one has to consider manifold criteria. Current approaches only relate to code smells and design flaws, and do not take architectural impact into consideration. The project aims at developing a decision framework integrating architecture smell detection, selection of appropriate refactorings and impact analysis to prioritize refactorings and support not only developers but also software architects.
Ongoing doctoral project, since 2018
Contact: Paula Rachow
Supervision: Matthias Riebisch/André van Hoorn
Thomas F. Düllmann: Exploiting DevOps Practices for Dependable and Continuous Delivery Pipelines
Sebastian Gerdes: Recommendation for Architects for Technology Decisions
Taking the right decisions is a major challenge for architects during the initial design phase and especially the ongoing evolution of a software system. Wrong decisions result in high effort and costs in case they need to be revised. A large number of the decisions target at the selection of suitable technologies. On the one hand, continuous technological progress and changing requirements lead to new technologies come into the market. On the other hand, outdated technologies and missing features demand a replacement. A great many of technologies, the analysis of their dependencies and the lack of knowledge about specific benefits and drawbacks even hamper the selection, especially if different technologies a quite similar. This uncertainty often makes architects to opt for technologies they already have in mind, which increases the risk of poor decisions.
The research project aims to support the architect in taking technology design decisions during software evolution. To achieve this, we propose three major steps. Firstly, we analyze existing software systems to provide an overview of current technologies and features. This will be based on the identification of features in the source code. Secondly, to suggest potential alternatives for a technology being replaced, we analyze the features, prerequisites and dependencies and build up a knowledge base allowing for reuse and efficient matching of solutions. Thirdly, we provide guidance for the replacement of a technology to ease the migration process.
Ongoing doctoral project, since 2013
Contact: Sebastian Gerdes
Supervision: Matthias Riebisch/Janick Edinger
Completed Doctoral Projects
Henning Schulz: Automated generation of tailored load tests for continuous software engineering
Continuous software engineering (CSE) aims to produce high-quality software through frequent and automated releases of concurrently developed services. By replaying workloads that are representative of the production environment, load testing can identify quality degradation under realistic conditions. The literature proposes several approaches that extract representative workload models from recorded data. However, these approaches contradict CSE's high pace and automation in three aspects: they require manual parameterization, generate resource-intensive system-level load tests, and lack the means to select appropriate periods from the temporally varying production workload to justify time-consuming testing. This dissertation addresses the automated generation of tailored load tests to reduce the time and resources required for CSE-integrated testing. The tailoring needs to consider the services of interest and select the most relevant workload periods based on their context, such as the presence of a special sale when testing a webshop. Also, we intend to support experts and non-experts with a high degree of automation and abstraction. We develop and evaluate description languages, algorithms, and an automated load test generation approach that integrates workload model extraction, clustering, and forecasting. The evaluation comprises laboratory experiments, industrial case studies, an expert survey, and formal proofs. Our results show that representative context-tailored load tests can be generated by learning a workload model incrementally, enriching it with contextual information, and predicting the expected workload using time series forecasting. For further tailoring the load tests to services, we propose extracting call hierarchies from recorded invocation traces. Dedicated models of evolving manual parameterizations automate the generation process and restore the representativeness of the load tests. Furthermore, the integration of our approach with an automated execution framework enables load testing for non-experts. Following open-science practices, we provide supplementary material online. The proposed approach is a suitable solution for the described problem. Future work should refine specific building blocks the approach leverages. These blocks are the clustering and forecasting techniques from existing work, which we have assessed to be limited for predicting sharply fluctuating workloads, such as load spikes.
Doctoral project, 2017–2020
Supervision: André van Hoorn
Sandra Schröder: Monitoring and Controlling Software Architecture Erosion
During the development and maintenance activities, it is likely that architectural violations are introduced and consequently the implementation diverges from the intended software architecture. The agglomeration of such architectural violations is known as architecture erosion causing degradation of software quality attributes, e.g. maintainability. In order to ensure longevity of a software system, it is important to monitor and control architecture erosion during the entire software life cycle.
This project aims at detecting and evaluating critical architectural violations in a software system. First, we identified the most critical architectural concerns regarding architecture erosion by interviewing software architects from industry and how they identify and prevent architecture erosion. Second, we provide an approach that aims to detect and prioritize architectural violations of a software system. We not only investigate the source code but additionally use software data like source code comments, commits from source code versioning systems, pull requests, issue tracking systems etc. Additionally, we want to describe how architecture erosion emerges when the source code is changed. We investigate if recurring evolution styles of architecture erosion exist that can be used further for prediction and prevention of architecture erosion.
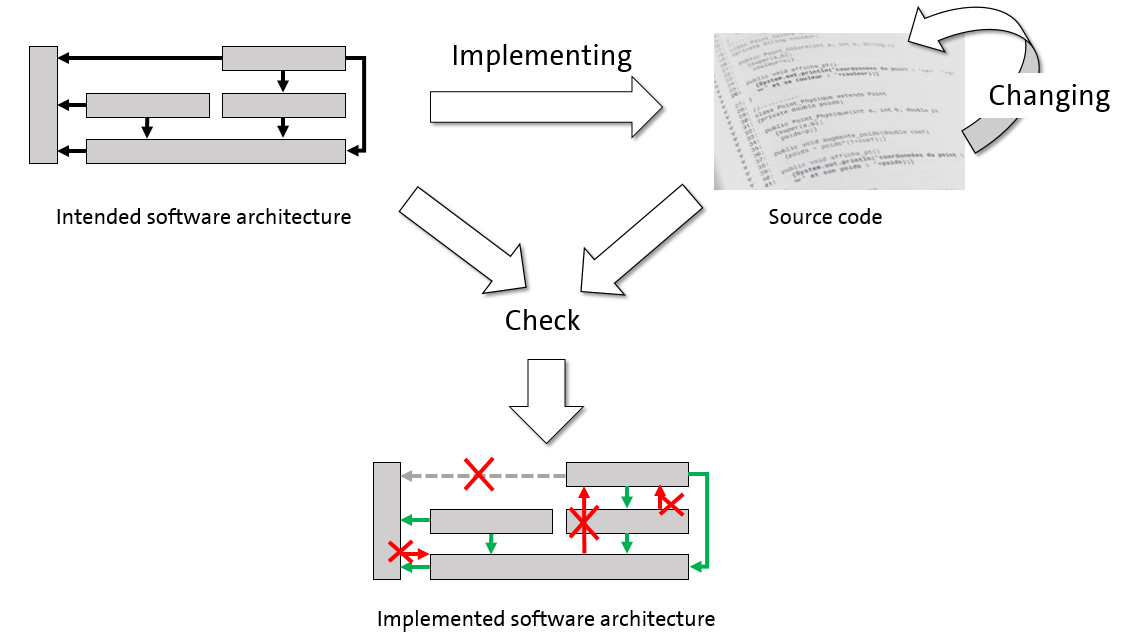
Doctoral project, 2014–2020
Supervision: Matthias Riebisch
Tilmann Stehle: Porting for Synchronized Cross-Platform Development of Mobile Apps
Porting software systems to new platforms nowadays is a key issue in software engineering, developers have to target multiple platforms in order to reach a higher number of users. Existing cross-platform frameworks and methodologies however are applicable only to greenfield development. There is hardly any technical or methodological support for the frequent situation that an existing mature software shall be ported rather than being completely re-implemented for an additional platform. This leads to superfluous work during the further evolution and maintenance of the original software and its target platform version. Furthermore, the lack of traceability between the versions makes the evolution process prone to structural and functional inconsistencies.
This project strives to develop a flexible method both for porting and synchronized evolution. During porting, traceability and structural equivalences between both versions are introduced. The synchronized evolution leverages the traceability and equivalencies by refactoring support, cross-platform feature localization and navigation support. These means help developers to keep multiple platform versions of a software system consistent and reduce redundant work during their evolution and maintenance.
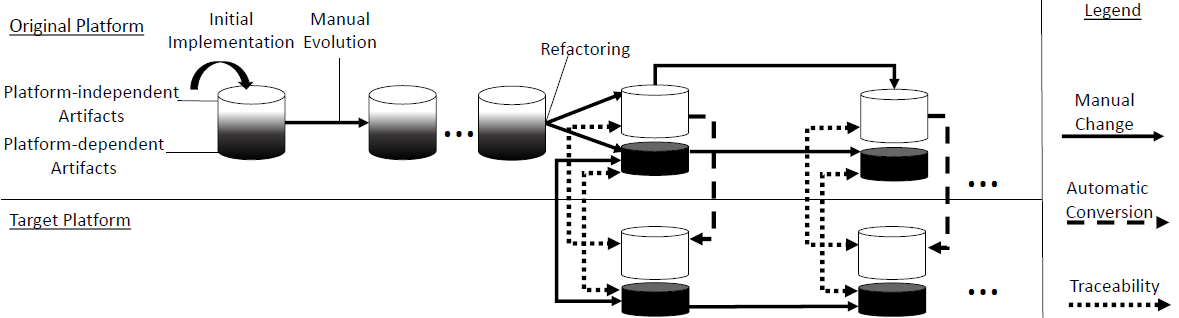
Case Studies
Metropole des Wissens: The developed porting method has been applied to the original implementation of the iOS app "Metropole des Wissens" in order to port it to the Android platform. Both the original and ported code are currently being published as open-source software.
DESMO-JS: The method has additionally been applied to the simulation Framework DESMO-J in order to port parts of the original code to JavaScript. The project code can be obtained from https://github.com/TilStehle/DESMO-JS
Doctoral project, 2015–2020
Supervision: Matthias Riebisch
Mohamed Soliman: Acquiring Architecture Knowledge for Technology Design Decisions
Software became an essential and important part of our life. A useful software with a high quality has bigger influence on our daily activity. Architectural design decisions have a big influence on the quality of a software system, and are difficult to change once implemented. Software architecture is developed as a result of selecting several software architectural solutions. However, the complexity, diversity and evolution nature of architectural solutions force software engineers to make critical design decisions based only on their own experience. This could lead to wrong or sub-optimal design decisions. In order to support software engineers to take the right design decisions, assistance is required for exploring the architectural knowledge, which encompasses various architectural solutions, their relationships and distinctions.
Technology design decisions are one of the most frequently occurring types of architectural decisions, which impact several quality attributes of a software architecture. In the past decades, the number of available technology options has increased significantly, which make technology decisions harder to take. Current architecture knowledge management approaches try to support architects by offering a rich base of architectural solutions, decision factors, and rules. However, current architecture knowledge management approaches depend on manually capturing knowledge about decisions and architectural solutions. Obtaining and evaluating the quality of relevant and reusable knowledge requires significant manual maintenance effort, which is not feasible with the fast pace of advance in technological development.
The overall problem addressed in this dissertation is to facilitate acquiring relevant architectural knowledge to take technology design decisions. We addressed this problem by achieving three main goals: First, we understand technology design decisions in practice. This ensures the practicability of our knowledge capturing solutions. Second, we explore developer communities for architecture knowledge. Developer communities contain an enormous amount of discussions between software engineers, which could be a reliable and an effective source of architecture knowledge. Third, we propose solutions to effectively search for relevant architectural information in developer communities.
To understand technology design decisions in practice, we interviewed practitioners and asked them about their decision making process. Based on the interviews with practitioners, we found that software engineers consider certain technology aspects as their main factor to take technology design decisions. These aspects differentiate technologies from each other. While technology vendors describe technology solutions as a set of features, software engineers discuss the differences between technologies in developer communities. As a result from our interviews, we extended existing architecture knowledge models with additional concepts for technology design decisions.
Current approaches for architecture knowledge management depend on knowledge repositories, which requires much effort to gather, populate and maintain knowledge. Therefore, we explored the most popular software development community (StackOverflow) as a source of architectural knowledge. We analysed posts in Stack Overflow to explore the type of architectural questions and solutions. We found different types of architecture relevant posts, which identify and evaluate technology features and components design. To ensure that we explore relevant architecture-relevant posts, we evaluated our classification of posts through feedback from practitioners to create the first corpus of architecture-relevant posts in developer communities, and the first ontology for architecture knowledge in developer communities. The ontology specifies the structure and textual representation of architecture knowledge concepts in developer communities. Moreover, the ontology is empirically grounded through qualitative analyses of different Stack Overflow posts, as well as inter-coder reliability tests.
To facilitate searching for architectural information in developer communities. We developed and compared in a series of experiments a set of classification approaches to identify and classify architecture-relevant posts on StackOverflow. The classification approaches rely on our proposed ontology of architectural concepts and therefore allow capturing semantic information in StackOverflow posts rather than only relying on keyword matching and lexical information. Furthermore, we present a novel approach to search for architecture-relevant information in Stack Overflow posts. We implemented this approach in a web-based search engine and compared its effectiveness to a pure keyword-based search in a series of tasks given to practitioners. Our results show that the effectiveness of searching has been improved significantly compared to a conventional keyword-based search.
Doctoral project, 2013–2019
Supervision: Matthias Riebisch
Teerat Pitakrat: Architecture-aware online failure prediction for software systems
Failures at runtime in complex software systems are inevitable because these systems usually contain a large number of components. Having all components working perfectly at the same time is, if at all possible, very difficult. Hardware components can fail and software components can still have hidden faults waiting to be triggered at runtime and cause the system to fail. Existing online failure prediction approaches predict failures by observing the errors or the symptoms that indicate looming problems. This observable data is used to create models that can predict whether the system will transition into a failing state. However, these models usually represent the whole system as a monolith without considering their internal components. This thesis proposes an architecture-aware online failure prediction approach, called Hora. The Hora approach improves online failure prediction by combining the results of failure prediction with the architectural knowledge about the system. The task of failure prediction is split into predictingthe failure of each individual component, in contrast to predicting the whole system failure. Suitable prediction techniques can be employed for different types of components. The architectural knowledge is used to deduce the dependencies between components which can reflect how a failure of one component can affect the others. The failure prediction and the component dependencies are combined into one model which employs Bayesian network theory to represent failure propagation. The combined model is continuously updated at runtime and makes predictions for individual components, as well as inferring their effects on other components and the whole system. The evaluation of component failure prediction is performed on three different experiments. The predictors are applied to predict component failures in a microservice-based application, critical events in Blue Gene/L supercomputer, and computer hard drive failures. The results show that the failures of individual components can be accurately predicted. The evaluation of the whole Hora approach is carried out on a microservice-based application. The results show that the Hora approach, which combines component failure prediction and architectural knowledge, can predict the component failures, their effects on other parts of the system, and the failures of the whole service. The Hora approach outperforms the monolithic approach that does not consider architectural knowledge and can improve the area under the Receiver Operating Characteristic (ROC) curve by 9.9%.
Doctoral project, 2013–2018
Supervision: André van Hoorn
Qurat-Ul-Ann Farooq: Model-based Regression Testing of Evolving Software Systems
Changes are required to evolve software systems in order to meet the requirements emerging from technological advances, changes in operating platforms, end user needs, and demands to fix errors and bugs. Studies have shown that about one third of a project’s budget is spent to test these changes to ensure the system correctness. To minimize the testing cost and effort, model-based regression testing approaches select a subset of test cases earlier by tracing the changes in analysis and design models to the tests. However, modeling of complex software systems demands to cover various views, such as structural view and behavioral view. Dependency relations exist between these views due to overlapping and reuse of various concepts. These dependency relations complicate regression testing by propagating the changes across the models of different views and tests. Change impact analysis across the models and tests is required to identify the potentially affected test cases by analyzing the change propagation through dependency relations.
This thesis presents a holistic model-based regression testing approach, which exploits the interplay of changes and dependency relations to forecast the impact of changes on tests. A baseline test suite, the one used for testing the stable version of software, is required for the selection of test cases. To enable a test baseline, our approach supplements a model-driven test generation approach that uses model transformations to generate various test aspects. The approach uses BPMN and UML models and generates test models expressed as UML Testing Profile (UTP).
Dependency relations are recorded prior to the impact analysis by using a two-fold approach; during the generation of baseline test suite and by using a rule-based dependency detection approach. This prevents repeated search of dependency relations for each change and makes our approach less time extensive. Change impact analysis across tests is supported by integrating a rule-based impact analysis approach. The approach enables a set of rules, which analyze previously recorded dependency relations and change types to further propagate the impact of a change. To precisely define various changes in models, the approach also synthesizes a change taxonomy for a consistent representation of complex changes in the models. Finally, to distinguish between various potentially affected tests, our approach presents the concept of test classification rules. Test classification rules analyze the type of an affected element, the type of the applied change, and other related elements to decide whether the affected element is obsolete, unaffected, or required for regression testing.
To demonstrate the applicability of our approach in practice, we adapted our approach for the domain of business processes and support BPMN, UML, and UTP models. The tool support for our approach is available in two prototype tools; VIATRA Test Generation Tool (VTG) and EMFTrace. VTG generates UTP test baseline from BPMN and UML models using model transformations. EMFTrace is a tool, which was built initially to support the rule-based dependency detection among models. It is further extended to support the rule-based impact analysis and rule-based test classification. These tools help us to evaluate our approach on a case study from a joint industrial project to enable business processes of a field service technician on mobile platforms. The results of our evaluation show promising improvements with an average reduction of the test cases by 46% achieved with an average precision and recall of 93% and 87% respectively.
Doctoral project, 2009–2016
Supervision: Matthias Riebisch
Steffen Lehnert: Multiperspective Change Impact Analysis to Support Software Maintenance and Reengineering
The lifecycle of software is characterized by frequent and inevitable changes to address varying requirements and constraints, remaining defects, and various quality goals, such as portability or efficiency. Adapting long-living systems, however, poses the risk of introducing unintended side effects, such as new program errors, that are typically caused by dependencies between software artifacts of which developers are not aware of while changing the software. Consequently, research has focused on developing approaches for software change impact analysis to aid developers with assessing the consequences of changes prior to their implementation. Yet, current change impact analysis approaches are still code-based and only able to assess the consequences of changing source code artifacts. Software development on the other hand is accompanied by various different types of software artifacts, such as software architectures, test cases, source code files, etc. which in turn demand for comprehensive change impact analysis.
This thesis presents a novel approach for change impact analysis that is able to address heterogeneous software artifacts stemming from different development stages, such as architectural models and source code. It allows to forecast the impacts of changes prior to their implementation and is able to address a multitude of different change operations. The approach is based on a novel concept for computing the propagation of changes, for which the interplay of the types of changes, types of software artifacts, and the types of dependencies between them is analyzed by a set of predefined impact propagation rules. To accomplish this, the heterogeneous software artifacts are first mapped on a common meta-model to allow for a multiperspective analysis across the different views on software. Secondly, their dependencies are extracted and explicitly recorded as traceability links, while the type of change to be implemented is specified and modeled using a taxonomy and meta-model for change operations supplied by this thesis. A set of impact propagation rules is then recursively executed to compute the overall impact of the change, where each rule addresses a specific change operation and determines the resulting impact. Meanwhile, the impact computed by each rule is fed back into the analysis process where it may trigger the execution of further rules. Once the overall impact of a change has been determined, the impacted software artifacts are presented to the developer who is then able to understand the overall implications of the change and to implement it more efficiently.
The presented approach is implemented by the prototype tool EMFTrace and currently enables change impact analysis of UML models, Java source code, and JUnit test cases to support developers with their everyday modifications of software systems. The approach was deployed during a comprehensive case study to evaluate its efficiency and correctness when determining the impacts of changes. The approach helped to maintain the consistency of the architecture and the source code of the test system by reliably forecasting the impact propagation between both. The study furthermore confirmed that the approach achieves both high precision (90%) and recall (93%) when determining impacted software artifacts. Consequently, it computed only few false-positives and did not overestimate the impact propagation, which in turn enables developers to understand the effects of changes more easily and with less effort.
Doctoral project, 2010–2015
Supervision: Matthias Riebisch
Robert Brcina: Goal-Driven Detection and Correction of Quality Deficiencies in Software Systems for Evolvability
Zielorientierte Erkennung und Behebung von Qualitätsdefiziten in Software-Systemen am Beispiel der Weiterentwicklungsfähigkeit
Doctoral project, 2006–2011, TU Ilmenau
Supervision: Matthias Riebisch
Stefan Bode: Quality Goal Oriented Architectural Design and Traceability for Evolvable Software Systems
Sven Wohlfarth: A Process of Rational Decision-making for Architectural Decisions
Entwicklung eines rationalen Entscheidungsprozesses für Architekturentscheidungen
Doctoral project, 2004–2008, TU Ilmenau
Supervision: Matthias Riebisch
Periklis Sochos: The Feature-Architecture Mapping Method for Feature-Oriented Development of Software Product Lines
Ilian Pashov: Feature Based Method for Supporting Architecture Refactoring and Maintenance of Long-Life Software Systems
Detlef Streitferdt: Family Oriented Requirements Engineering
Kai Böllert: Object-Oriented Development of Software Product Lines for Serial Production of Software Systems
Objektorientierte Entwicklung von Software-Produktlinien zur Serienfertigung von Software-Systemen
Doctoral project, 1999–2002, TU Ilmenau
Supervision: Matthias Riebisch