Knowledge Technology
Department of InformaticsKnowledge Technology
Photo: UHH/Denstorf
17 November 2022
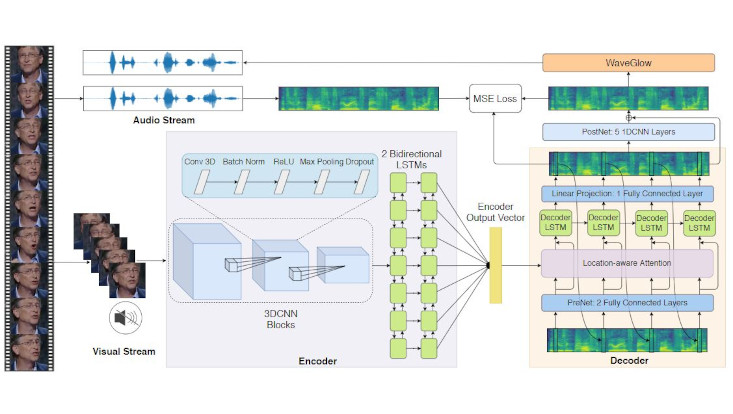
Photo: UHH/Knowledge Technology
Knowledge Technology has got a journal article published in IEEE Transactions on Neural Networks and Learning Systems (TNNLS).
Title: LipSound2: Self-Supervised Pre-Training for Lip-to-Speech Reconstruction and Lip Reading
Authors: Leyuan Qu, Cornelius Weber, Stefan Wermter
Abstract:
The aim of this work is to investigate the impact of crossmodal self-supervised pre-training for speech reconstruction (video-to-audio) by leveraging the natural co-occurrence of audio and visual streams in videos. We propose LipSound2 which consists of an encoder-decoder architecture and location-aware attention mechanism to map face image sequences to mel-scale spectrograms directly without requiring any human annotations. The proposed LipSound2 model is firstly pre-trained on ~2400h multi-lingual (e.g. English and German) audio-visual data (VoxCeleb2). To verify the generalizability of the proposed method, we then fine-tune the pre-trained model on domain-specific datasets (GRID, TCD-TIMIT) for English speech reconstruction and achieve a significant improvement on speech quality and intelligibility compared to previous approaches in speaker-dependent and -independent settings. In addition to English, we conduct Chinese speech reconstruction on the CMLR dataset to verify the impact on transferability. Lastly, we train the cascaded lip reading (video-to-text) system by fine-tuning the generated audios on a pre-trained speech recognition system and achieve state-of-the-art performance on both English and Chinese benchmark datasets.
Paper link (open access): https://ieeexplore.ieee.org/document/9837888
Demo website: https://leyuanqu.github.io/LipSound2/
Video demo: https://www.youtube.com/watch?v=CCk50A1_v_g

