Knowledge Technology
Department of InformaticsKnowledge Technology
Photo: UHH/Denstorf
13 May 2025
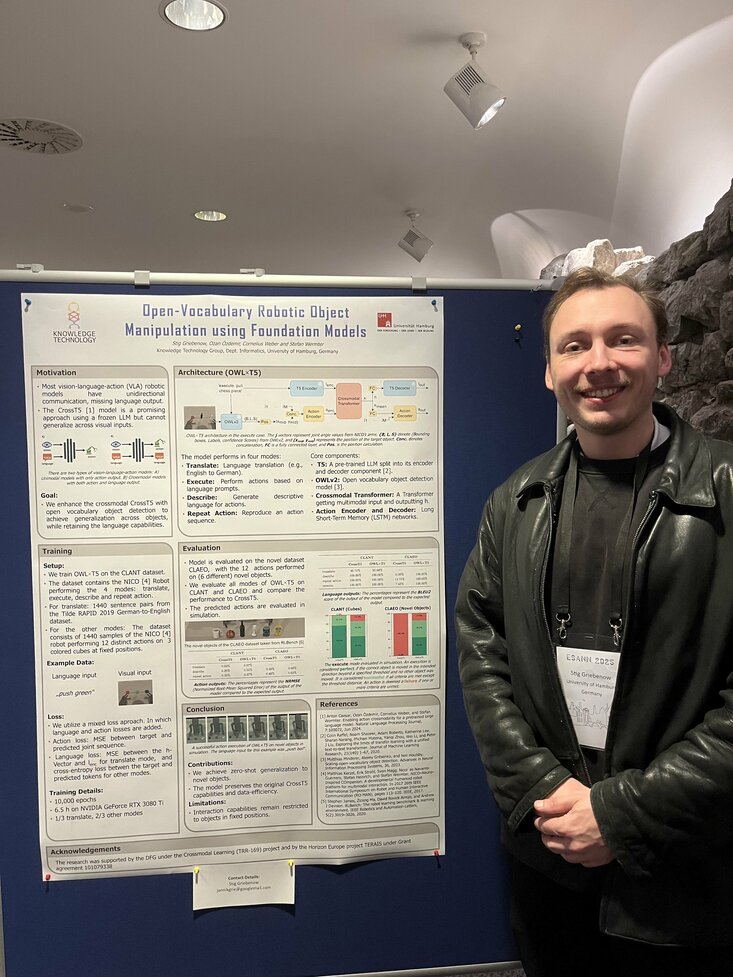
From our group, Master's student Stig Griebenow presented the OWL×T5 model at ESANN 2025 in Bruges, Belgium. OWL×T5 builds upon the CrossT5 architecture by incorporating the open-vocabulary OWLv2 object detection model, enabling robotic systems to perform actions on previously unseen objects through natural language instructions. Here's more information about the paper:
Title: Open-Vocabulary Robotic Object Manipulation using Foundation Models
Authors: Stig Griebenow, Ozan Özdemir, Cornelius Weber and Stefan Wermter
Abstract: Classical vision-language-action models are limited by unidirectional communication, hindering natural human-robot interaction. The recent CrossT5 embeds an efficient vision action pathway into an LLM, but lacks visual generalization, restricting actions to objects seen during training. We introduce OWL×T5, which integrates the OWLv2 object detection model into CrossT5 to enable robot actions on unseen objects. OWL×T5 is trained on a simulated dataset using the NICO humanoid robot and evaluated on the new CLAEO dataset featuring interactions with unseen objects. Results show that OWL×T5 achieves zero-shot object recognition for robotic manipulation, while efficiently integrating vision-language-action capabilities.
You can reach the full paper here.

