Authors: Robert Rehr and Timo Gerkmann
Conference: Interspeech 2017
Link: doi
Abstract
For single-channel speech enhancement, most commonly, the noisy observation is described as the sum of the clean speech signal and the noise signal. For machine learning based enhancement schemes where speech and noise are modeled in the log-spectral domain, however, the log-spectrum of the noisy observation can be described as the maximum of the speech and noise log-spectrum to simplify statistical inference. This approximation is referred to as MixMax model or log-max approximation. In this paper, we show how this approximation can be used in combination with non-trained, blind speech and noise power estimators derived in the spectral domain. Our findings allow to interpret the MixMax based clean speech estimator as a super-Gaussian log-spectral amplitude estimator. This MixMax based estimator is embedded in a pre-trained speech enhancement scheme and compared to a log-spectral amplitude estimator based on an additive mixing model. Instrumental measures indicate that the MixMax based estimator causes less musical tones while it virtually yields the same quality for the enhanced speech signal. For the following audio examples, the maximum suppression has been limited to 15 dB.
Audio Examples
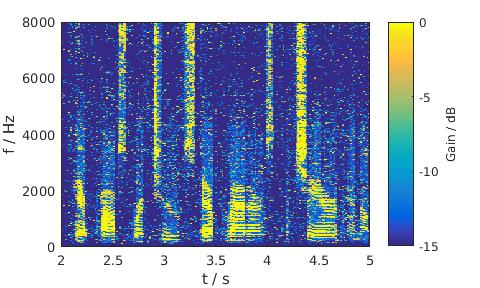
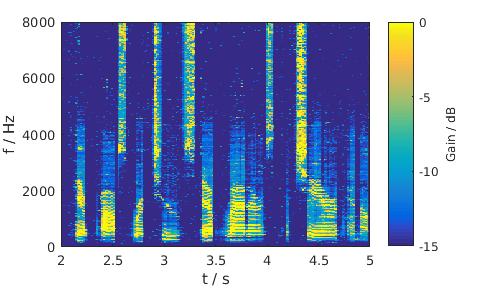
Pink noise, 5 dB SNR, Male
LSA
 |
MixMax
 |
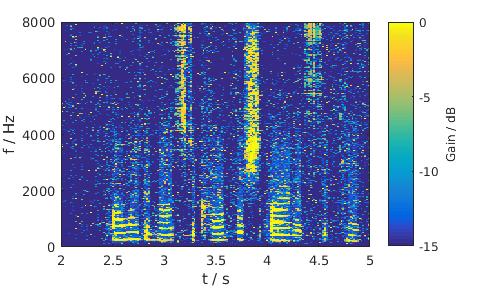
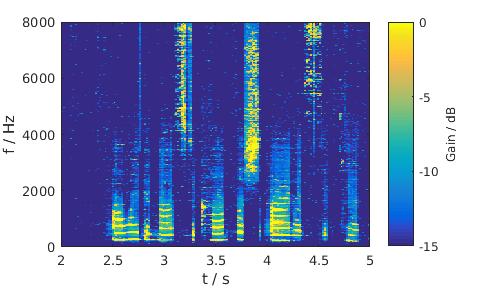
Pink noise, 5 dB SNR, Female
LSA
 |
MixMax
 |
Traffic noise, 5 dB SNR, Male
LSA
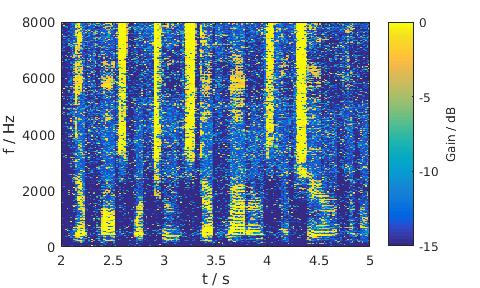 |
MixMax
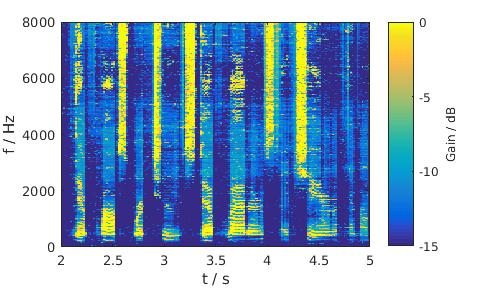 |
Traffic noise, 5 dB SNR, Female
LSA
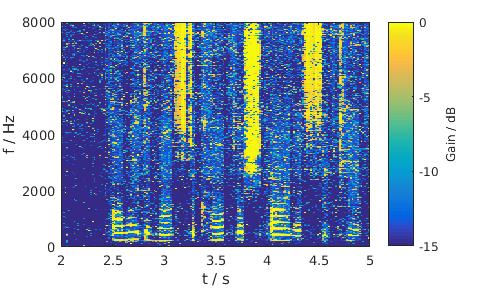 |
MixMax
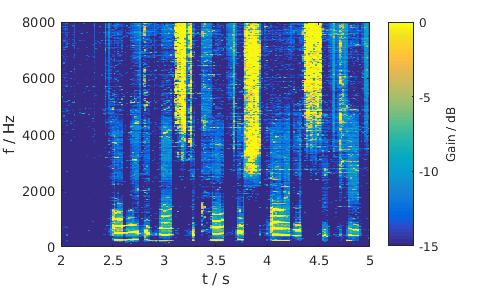 |
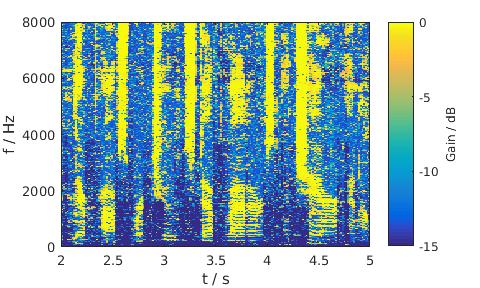
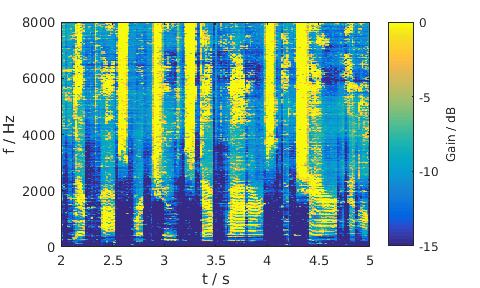
Babble noise, 5 dB SNR, Male
LSA
 |
MixMax
 |
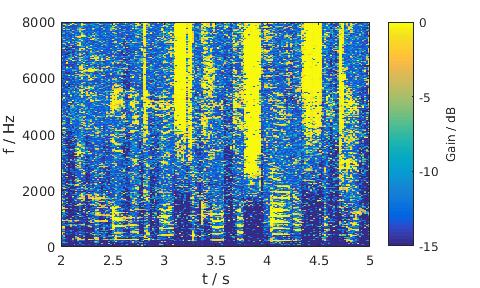
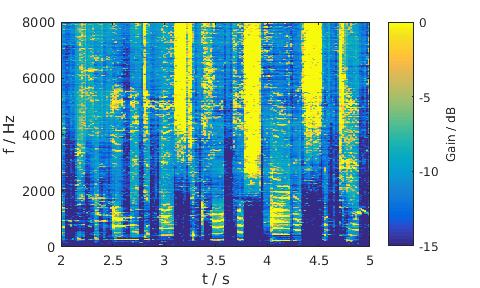
Babble noise, 5 dB SNR, Female
LSA
 |
MixMax
 |