This work was done in collaboration between the following authors:
Eloi Moliner and Prof. Vesa Välimäki from the Acoustics Lab of the Department of Information and Communications Engineering in Aalto University, Espoo, Finland
Jean-Marie Lemercier, Simon Welker and Prof. Dr-Ing. Timo Gerkmann from the Signal Processing group of Universität Hamburg, Hamburg, Germany
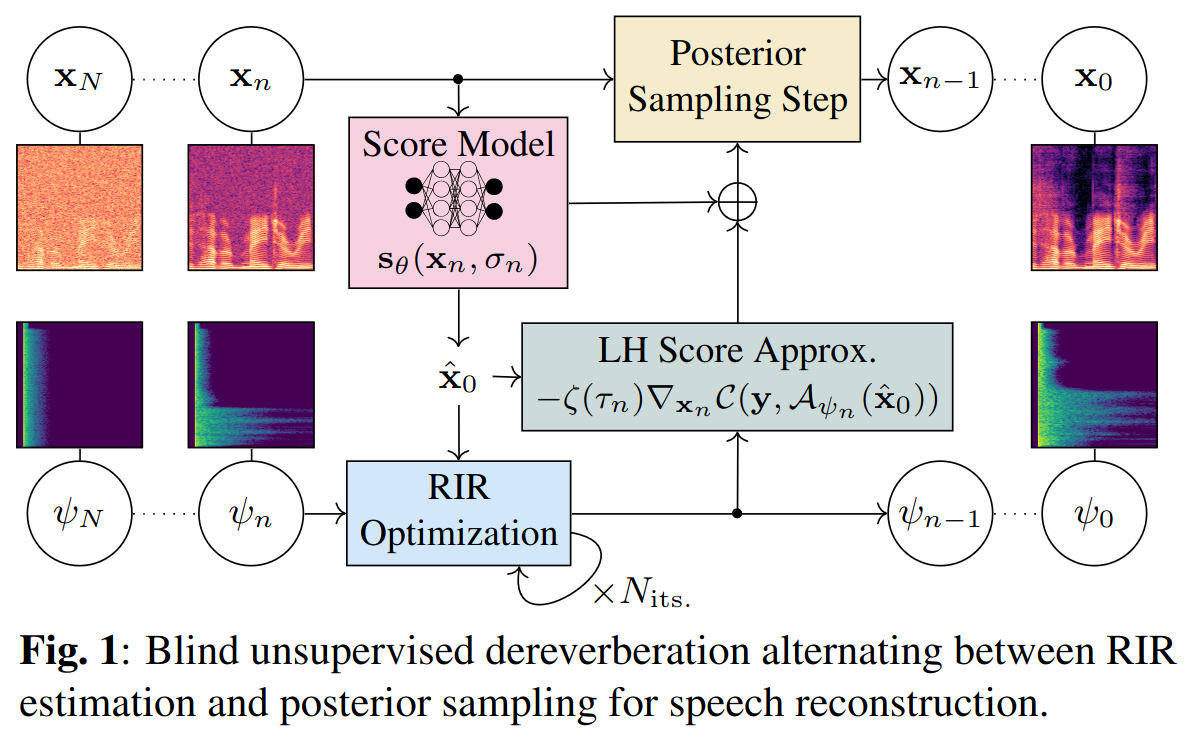
We present in these papers an unsupervised single-channel method for joint blind dereverberation and room impulse response estimation, based on posterior sampling with diffusion models.
We parameterize the reverberation operator using a filter with exponential decays for each frequency subband, and iteratively estimate the corresponding parameters as the speech utterance gets refined along the reverse diffusion trajectory.
As in the informed scenario, a measurement consistency criterion enforces the fidelity of the generated speech with the reverberant measurement, while an unconditional diffusion model implements a strong prior for clean speech generation.
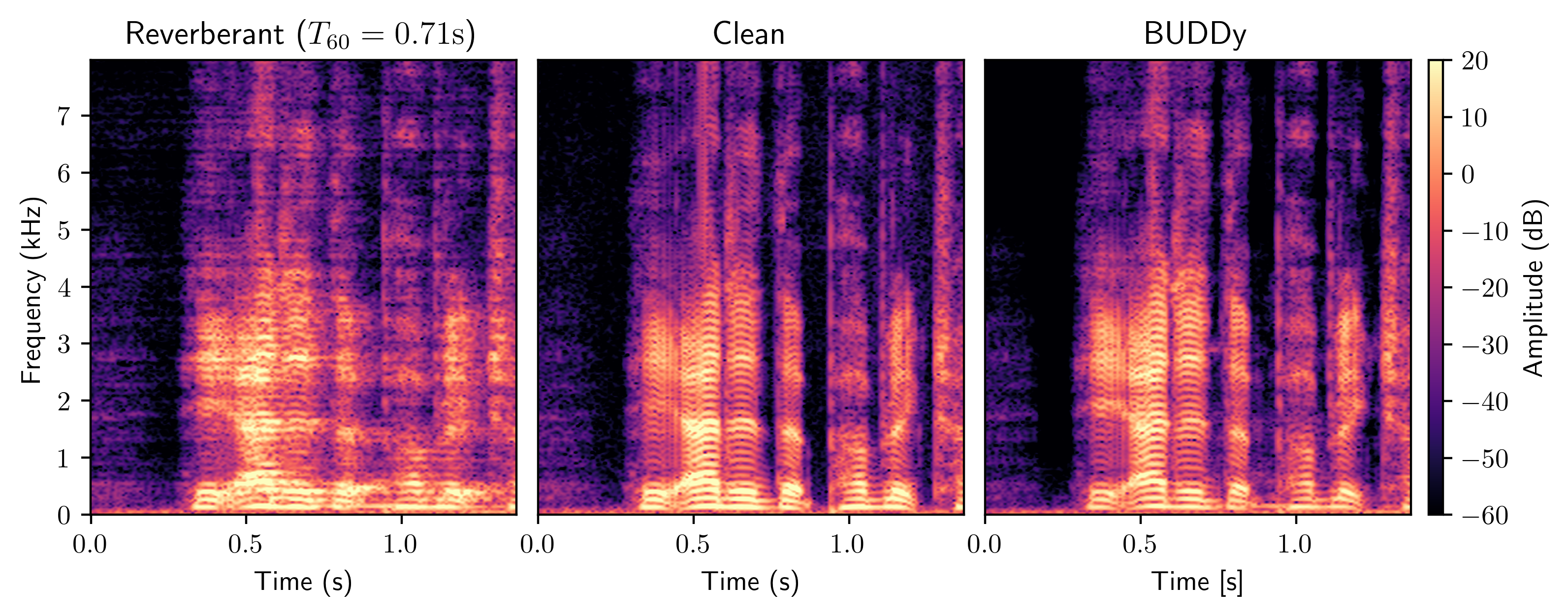
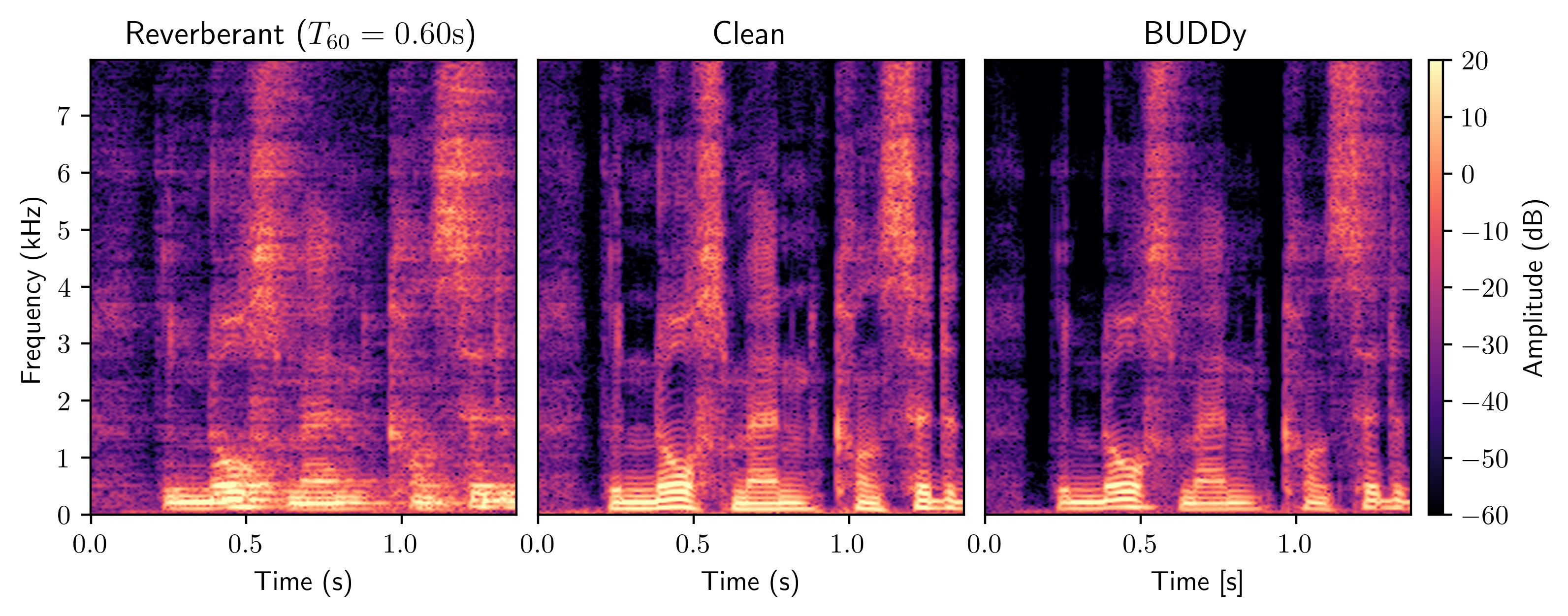
Without any knowledge of the room impulse response nor any coupled reverberant-anechoic data, we are able to successfully perform dereverberation in various acoustic scenarios, significantly outperforming previous blind unsupervised baselines.
We show that our method is more robust to unseen acoustic conditions than previous blind supervised methods, and that we significantly outperform approaches that combine an informed dereverberation method with a plug-in room impulse response estimator.