Analysing Diffusion-based Generative Approaches against Discriminative Approaches for Speech Restoration
This website contains supplementary material to the paper:
- Analysing Diffusion-based Generative Models against Discriminative Approaches for Speech Restoration Tasks, Oct 2022 [1]
Code
The code is availabe at https://github.com/sp-uhh/sgmse on the "icassp_2023" branch
Enhancement
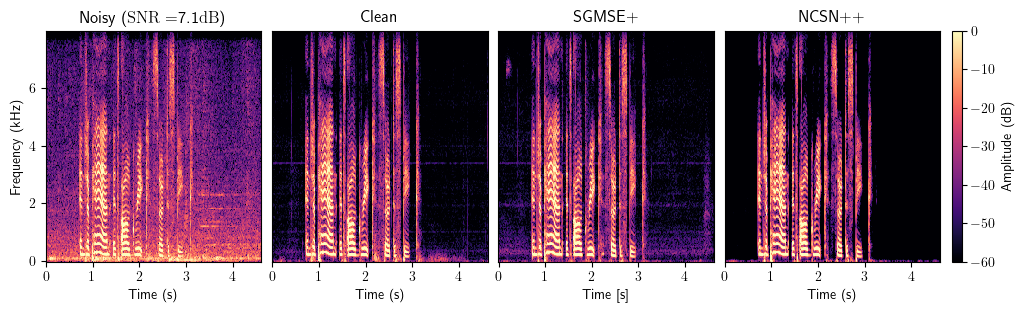
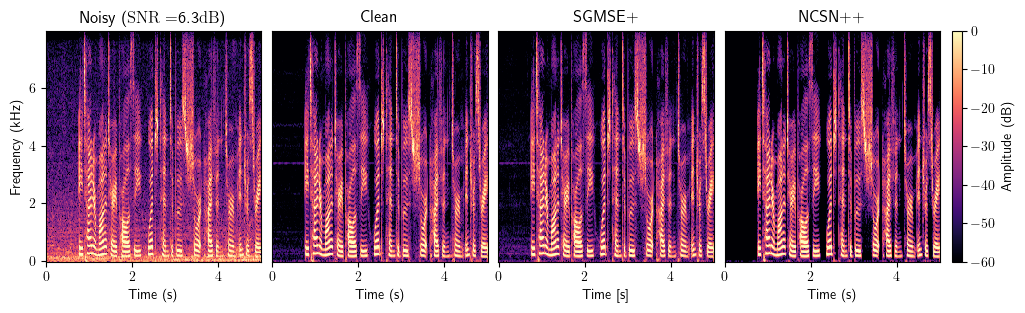
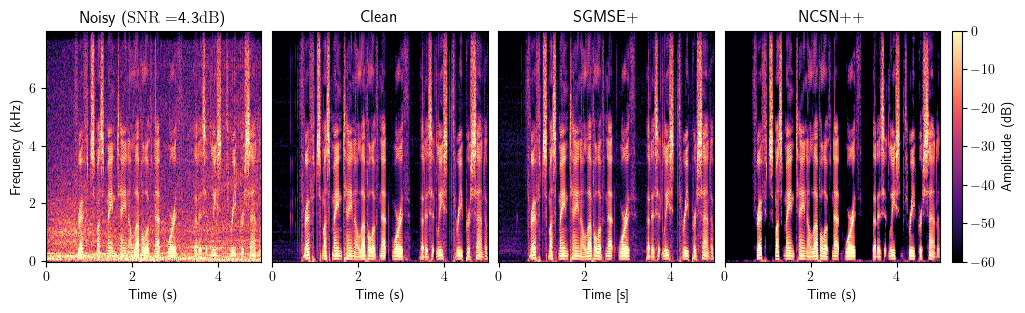
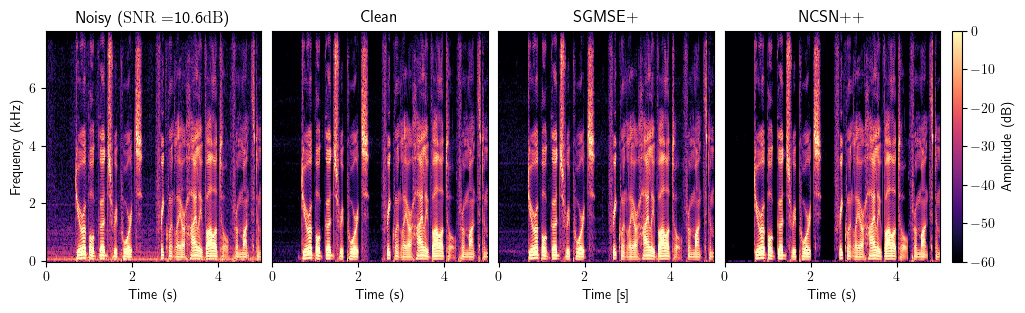
Dereverberation
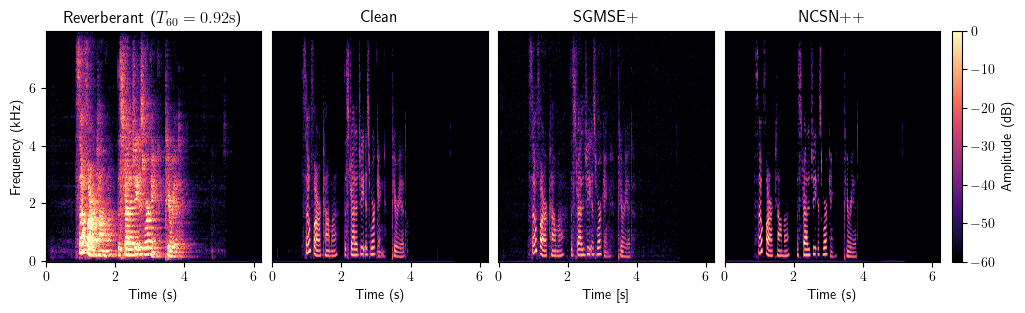
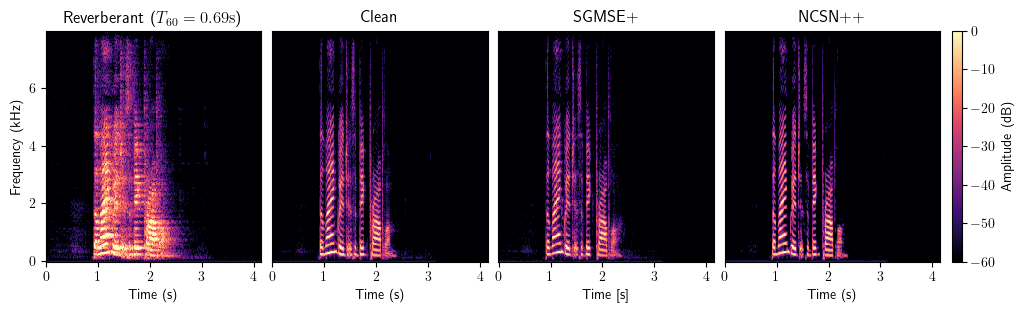
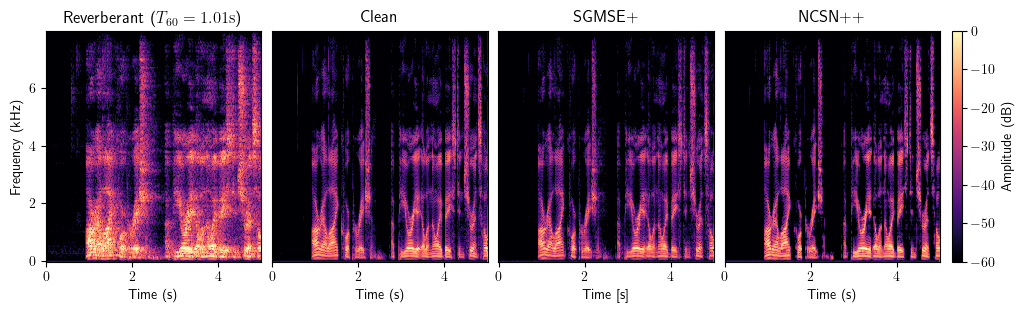
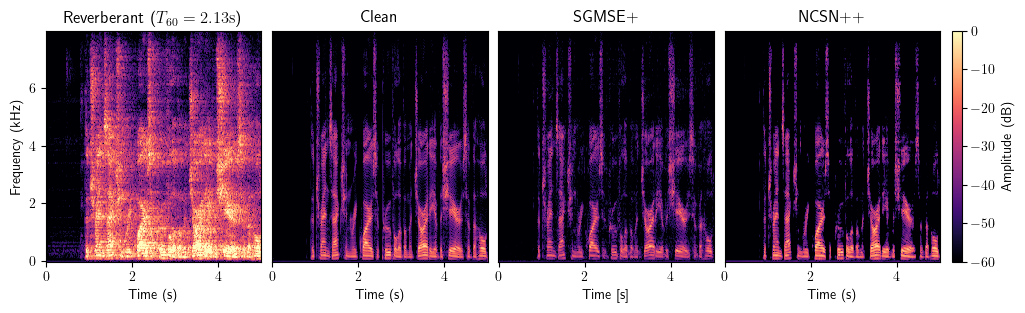
Bandwidth Extension
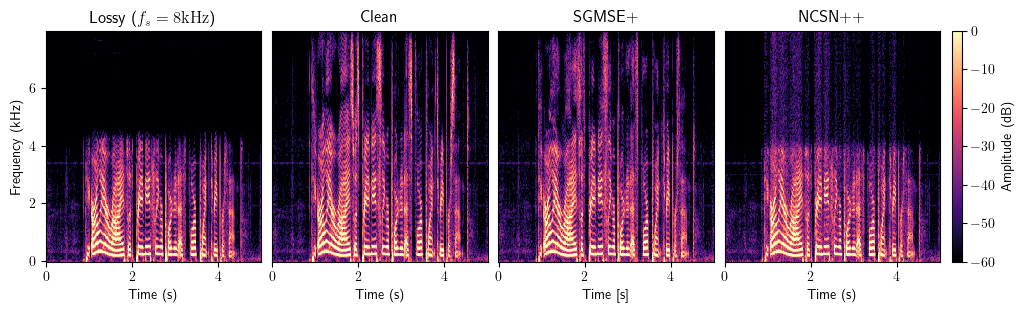
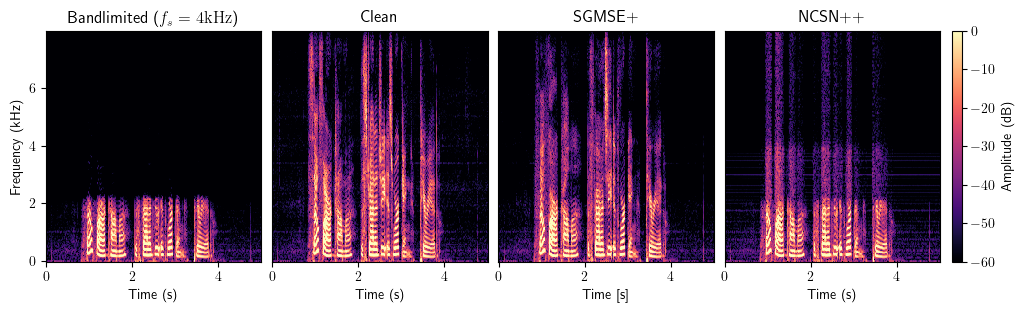
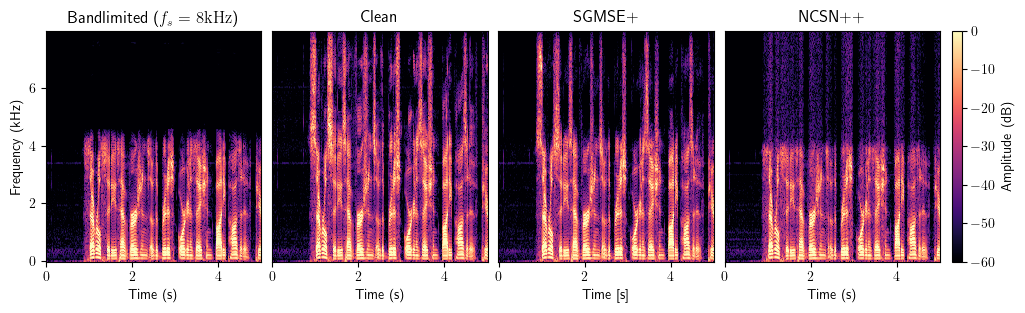
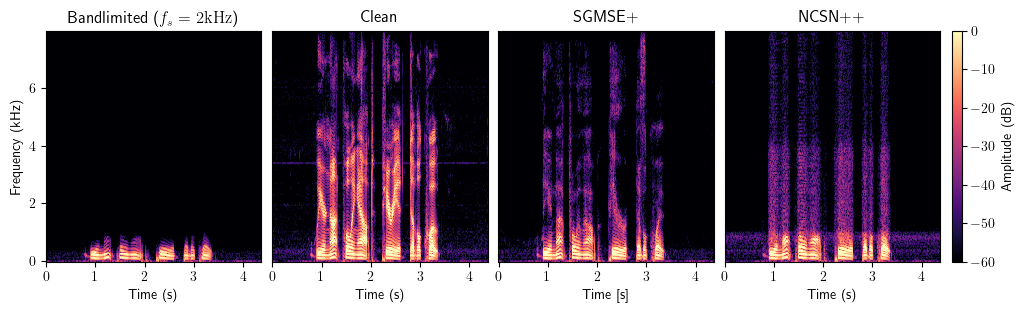
Full method comparison
The starred methods were trained on the specific input bandwidth. Other methods are bandwidth-agnostic. All models were trained on the VCTK corpus.
| 14p351317down4.wav | 116p351098down2.wav | 1346p360146down8.wav | 1511p360340down2.wav | |
|---|---|---|---|---|
| Input Sampling Frequency | 4kHz | 8kHz | 2kHz | 8kHz |
| Clean | ||||
| Bandlimited | ||||
| SGMSE+M [1] | ||||
| VoiceFixer [3] | ||||
| TUNet * [4] | ||||
| NuWave 2 [5] |
References
[1] Jean-Marie Lemercier, Julius Richter, Simon Welker and Timo Gerkmann. Analysing Diffusion-based Generative Models against Discriminative Approaches for Speech Restoration Tasks. arXiv preprint arXiv:2211.02397. 2022.
[2] Julius Richter, Simon Welker, Jean-Marie Lemercier, Bunlong Lay, and Timo Gerkmann. Speech Enhancement and Dereverberation with Diffusion-Based Generative Models. arXiv preprint arXiv:2208.05830. 2022.
[3] Haohe Liu, Qiuqiang Kong, Qiao Tian, Yan Zhao, DeLiang Wang, Chuanzeng Huang and Yuxuan Wang. VoiceFixer: Toward General Speech Restoration with Neural Vocoder. ISCA Interspeech. 2022.
[4] Viet-Anh Nguyen, Anh H. T. Nguyen and Andy W. H. Khong. TUNet: A Block-online Bandwidth Extension Model based on Transformers and Self-supervised Pretraining. ICASSP. 2022
[5] Seungu Han and Junhyeok Lee. NU-Wave 2: A General Neural Audio Upsampling Model for Various Sampling Rates. ISCA Interspeech. 2022