StoRM: A Stochastic Regeneration Model for Speech Enhancement and Dereverberation
This website contains supplementary material to the paper:
- [1] Jean-Marie Lemercier, Julius Richter, Simon Welker, Timo Gerkmann, "StoRM: A Diffusion-based Stochastic Regeneration Model for Speech Enhancement and Dereverberation", IEEE/ACM Trans. Audio, Speech, Language Proc., accepted, 2023. [arxiv][code]
Code
The code is availabe at https://github.com/sp-uhh/storm
Enhancement
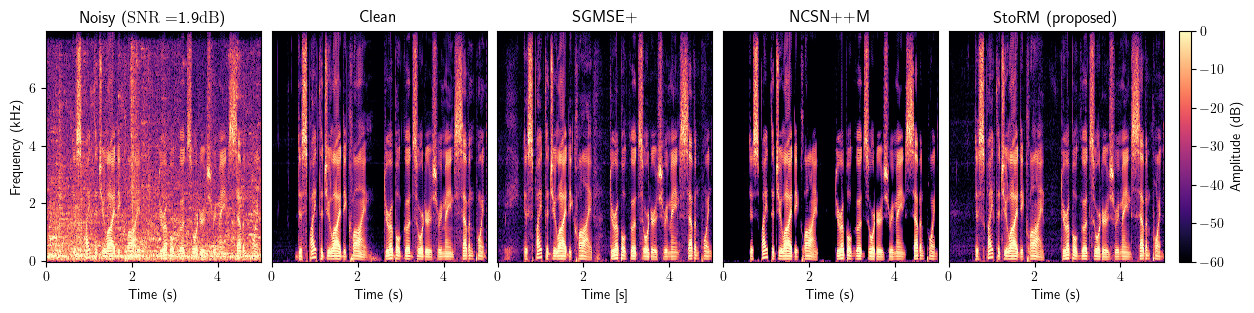
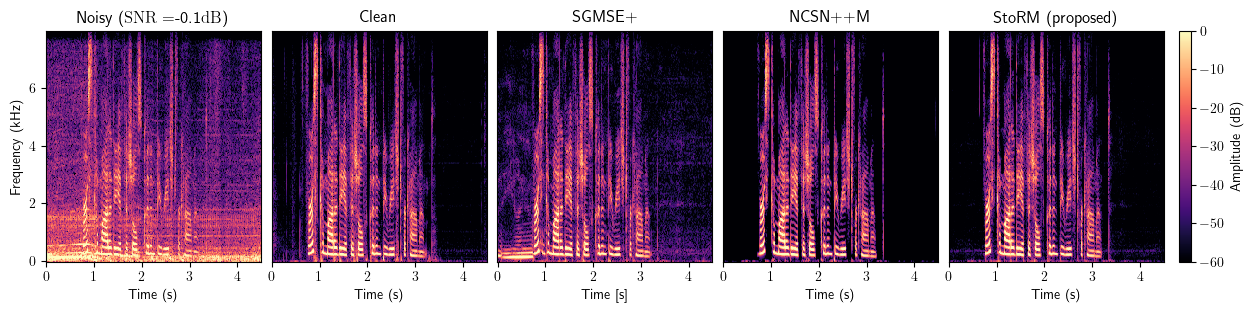
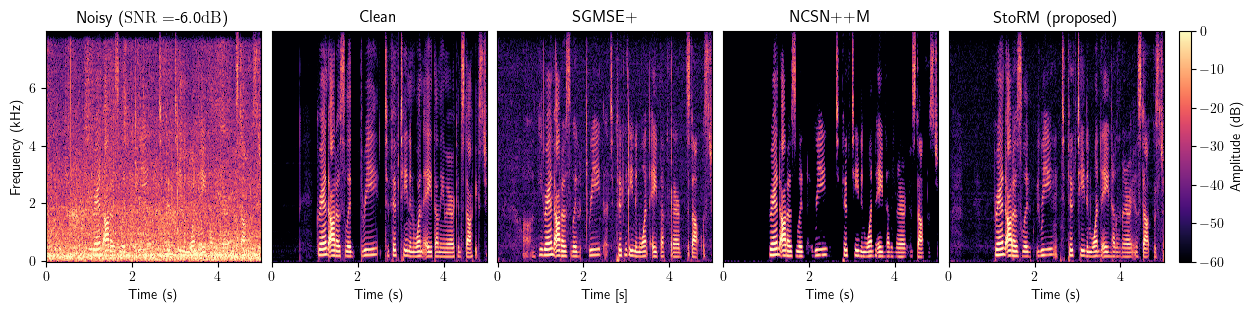
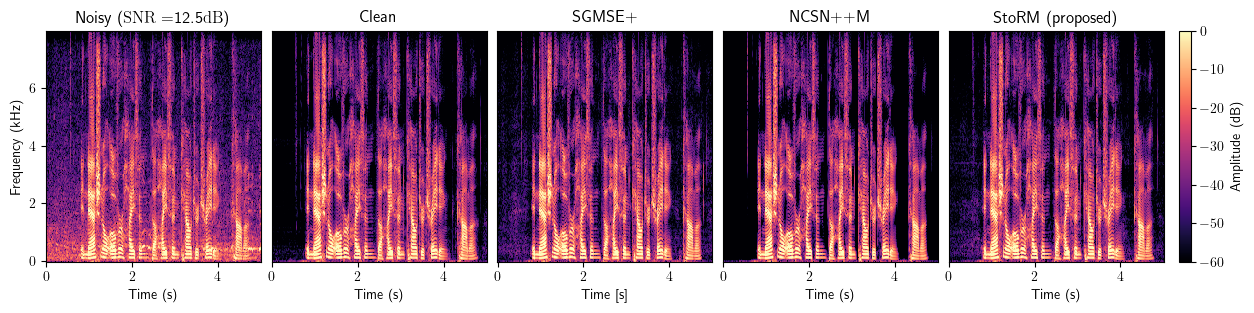
Dereverberation
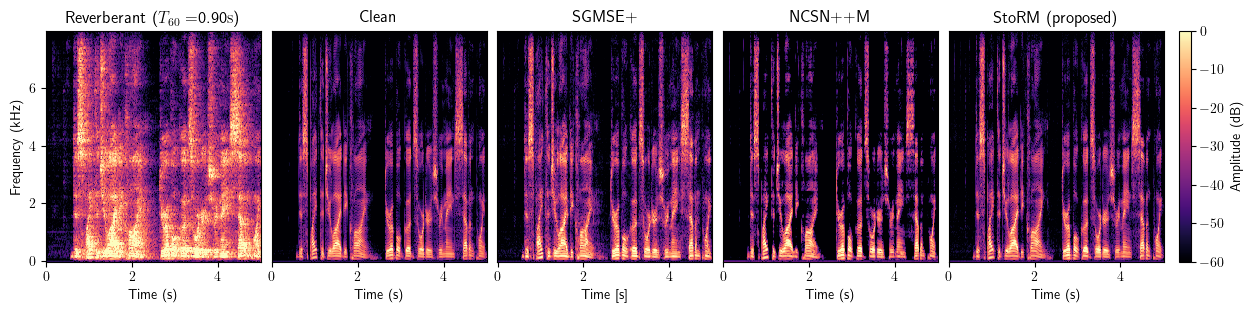
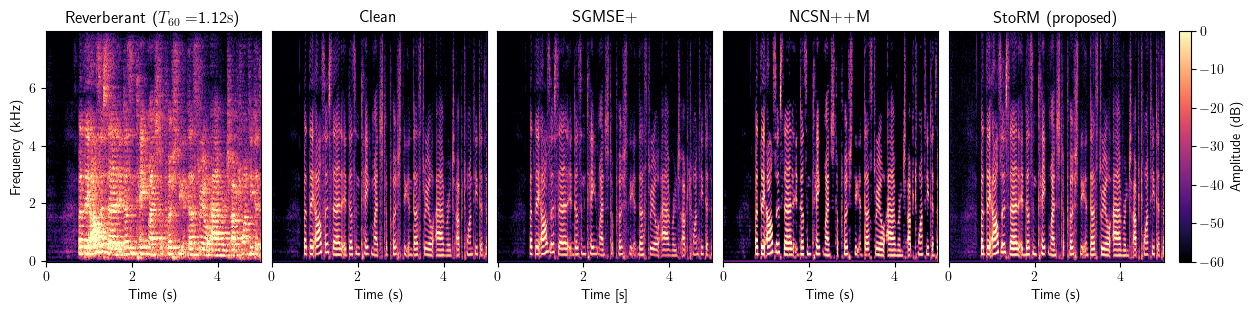
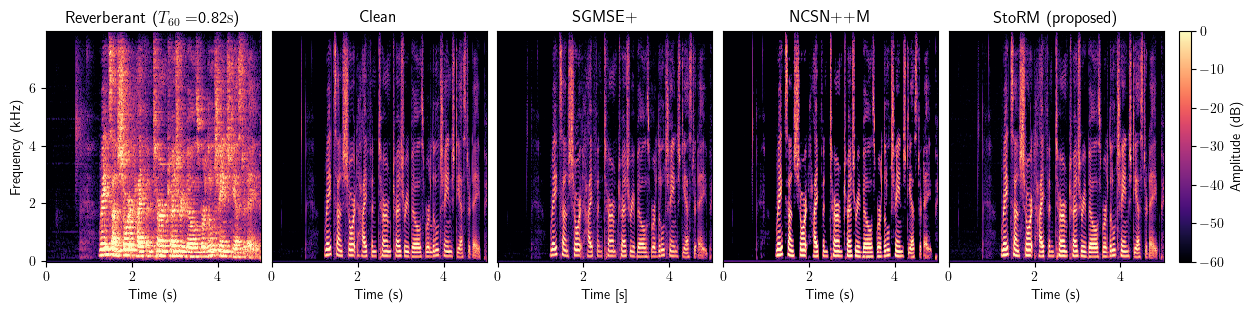
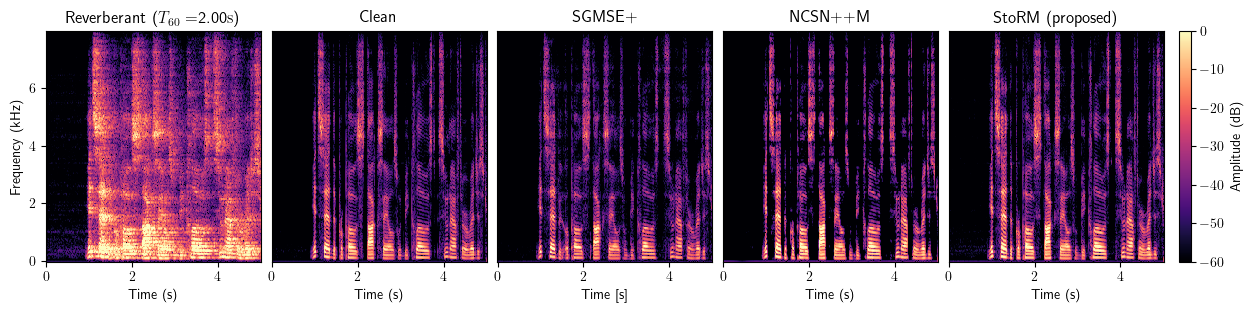
Full method comparison
Trained and tested on WSJ0+Chime3| 440o0304.wav | 447c0201.wav | 441c0204.wav | 445o030y.wav | |
|---|---|---|---|---|
| Input SNR | 0.28 dB | 2.54 dB | 0.41 dB | 2.56 dB |
| Clean | ||||
| Noisy | ||||
| StoRM [1] | ||||
| NCSN++M | ||||
| SGMSE+ [2] | ||||
| Conv-TasNet [3] | ||||
| MetricGAN+ [4] | ||||
| SGMSE [5] | ||||
| CDiffuSE [6] | ||||
| STCN [7] | ||||
| RVAE [8] |
References
[1] Jean-Marie Lemercier, Julius Richter, Simon Welker, Timo Gerkmann, "StoRM: A Diffusion-based Stochastic Regeneration Model for Speech Enhancement and Dereverberation", IEEE/ACM Trans. Audio, Speech, Language Proc., accepted, 2023. [arxiv][code][audio]
[2] Julius Richter, Simon Welker, Jean-Marie Lemercier, Bunlong Lay, Timo Gerkmann, "Speech Enhancement and Dereverberation with Diffusion-based Generative Models", IEEE/ACM Trans. Audio, Speech, Language Proc., Vol. 31, pp. 2351 - 2364, 2023. [doi] [arxiv] [code] [audio]
[3] Yi Luo and Nima Mesgarani. Conv-TasNet: Surpassing Ideal Time-Frequency Magnitude Masking for Speech Separation. IEEE/ACM Transactions on Audio, Speech, and Language Processing. 2019.
[4] Szu-Wei Fu, Cheng Yu, Tsun-An Hsieh, Peter Plantinga, Mirco Ravanelli, Xugang Lu and Yu Tsao. MetricGAN+: An Improved Version of MetricGAN for Speech Enhancement. Interspeech. 2021.
[5] Simon Welker, Julius Richter, and Timo Gerkmann. Speech Enhancement with Score-Based Generative Models in the Complex STFT Domain. ISCA Interspeech. 2022.
[6] Yen-Ju Lu, Zhong-Qiu Wang, Shinji Watanabe, Alexander Richard, Cheng Yu and Yu Tsao. Conditional Diffusion Probabilistic Model for Speech Enhancement. ICASSP. 2022.
[7] Julius Richter, Guillaume Carbajal, and Timo Gerkmann. Speech Enhancement with Stochastic Temporal Convolutional Networks. ISCA Interspeech. 2020.
[8] Xiaoyu Bie, Simon Leglaive, Xavier Alameda-Pineda and Laurent Girin. Unsupervised Speech Enhancement using Dynamical Variational Auto-Encoders. IEEE/ACM Transactions on Audio, Speech, and Language Processing. 2022.