SNR-Based Features and Diverse Training Data for Robust DNN-Based Speech Enhancement
This webpage accompanies the paper “SNR-Based Features and Diverse Training Data for Robust DNN-Based Speech Enhancement” [1]. In this paper single-channel speech enhancement using deep neural networks (DNNs) are considered. Further, the issue of generalization to unseen acoustic conditions is investigated when limited training are available, where we focus limitations in size and diversity of the available noise data. Here, we analyze how the generalization can be improved using noise-aware features.
Deep learning based approaches have gained attention over the last years because of promising results in comparison to conventional non-machine-learning based approaches. Especially, highly non-stationary noises, e.g., transient noises such as the cutlery in the restaurant, can be more efficiently removed using DNN based approaches. But a potential issue with learning based approaches is that they may not generalize to unseen acoustic conditions, e.g., unseen noise sounds. Non-machine-learning based approaches, however, generally cope well with unseen situations.
![Figure 1: Algorithms considered in [1]. Blocks with dashed lines indicate conventional algorithms.](/25655098/introduction-web-3332fc4d018943e68e7c7154f5263853f667be20.png)
To improve the generalization of DNN based approaches to unseen noise conditions, we consider combinations of DNN based approaches and conventional speech and noise PSD estimators in our paper. Fig. 1 depicts the three approaches that are investigated in our paper. All methods operate in the short-time Fourier transform (STFT) domain and predict a gain or mask function, respectively. The input features are different though.
- The first approach only uses the noisy logarithmized periodogram as input feature for a DNN.
- The second approach is similar to dynamic noise aware training (NAT) which has been proposed in [2], [3]. Here, a continuously updated noise PSD estimate is appended to the logarithmized periodogram feature. Similar to [3] we use the conventional approach proposed in [4], [5] to estimate the noise PSD.
- Last, we propose a novel approach where a noise PSD estimator and a speech PSD estimator are used to compute the a priori SNR and the a posteriori SNR as defined in [6]. We refer to this approach as signal-to-noise ratio (SNR) noise aware training (SNR-NAT). Also here, conventional approaches are used to estimate the PSDs. The speech PSD is estimated using the described in [7], while the noise PSD is estimated using [4], [5] again.
Furthermore, the influence of the noise training data is analyzed. For this, the DNN based approaches shown in Fig. 1 are trained using three different noise databases that differ in size and diversity. Specifically, the three noise databases are considered:
- The Hu Corpus [8] with the extensions proposed in [9]. This corpus and its extension have in total 115 different sound types, but in total the audio material is only about 14 minutes. Hence, this corpus is diverse but very small.
- The second noise corpus that is considered are the noise recordings in the CHiME~3 challenge [10], [11]. This corpus has four different acoustic environments, so its is less diverse than the Hu corpus. However, it is with about 8.5 hours much longer. Hence this, corpus is large, but less diverse.
- Third, we propose a corpus that is based on recordings taken from freesound.org. It has audio material of about 13.5 hours and many different noise types. This corpus is therefore considered large and highly diverse.
The speech training data is the same for all DNN based approaches and is taken from the TIMIT corpus [12].
Using the three different input features and the three different noise data corpora, two different types neural networks have been trained. The first network is a three-layer feed-forward network, while the second network is a three-layer long short-term memory (LSTM).
The website contains the audio examples for the spectrograms shown in Fig. 8 and Fig. 9 in the our paper [1]. Additionally, the results on real noisy speech samples from the real evaluation set CHiME 3 corpus [10], [11] and a recording from our lab are presented.
Examples in Paper
These are the sound examples shown Fig. 8 and Fig. 9 of the paper. Here, only LSTM networks are considered which have been used to process a speech signal that has been artificially corrupted by two different noises, namely an F16 jet noise taken from the NOISEX database [13] and a vacuum cleaner noise taken from freesound.org. The SNR has been set to 0 dB for both signals. The LSTM network has been trained using NAT features and SNR-NAT features, as well as, the three different noise corpora mentioned above yielding six different versions of the network.
The sound examples show that even using a large and diverse soundset for training and a recurrent network type, NAT features do not necessarily lead to a noise robust enhancement scheme. For the F16 noise, the network that has been trained on the freesound.org corpus using NAT features modulates speech like tones into the noise. Furthermore, if NAT features and the Hu corpus, which contains only little noise data, are used for training, the noise generally cannot be correctly removed. In all these cases the proposed SNR-NAT features yield better results. The noise generally sounds more smooth in noise only regions while the speech sounds similar.
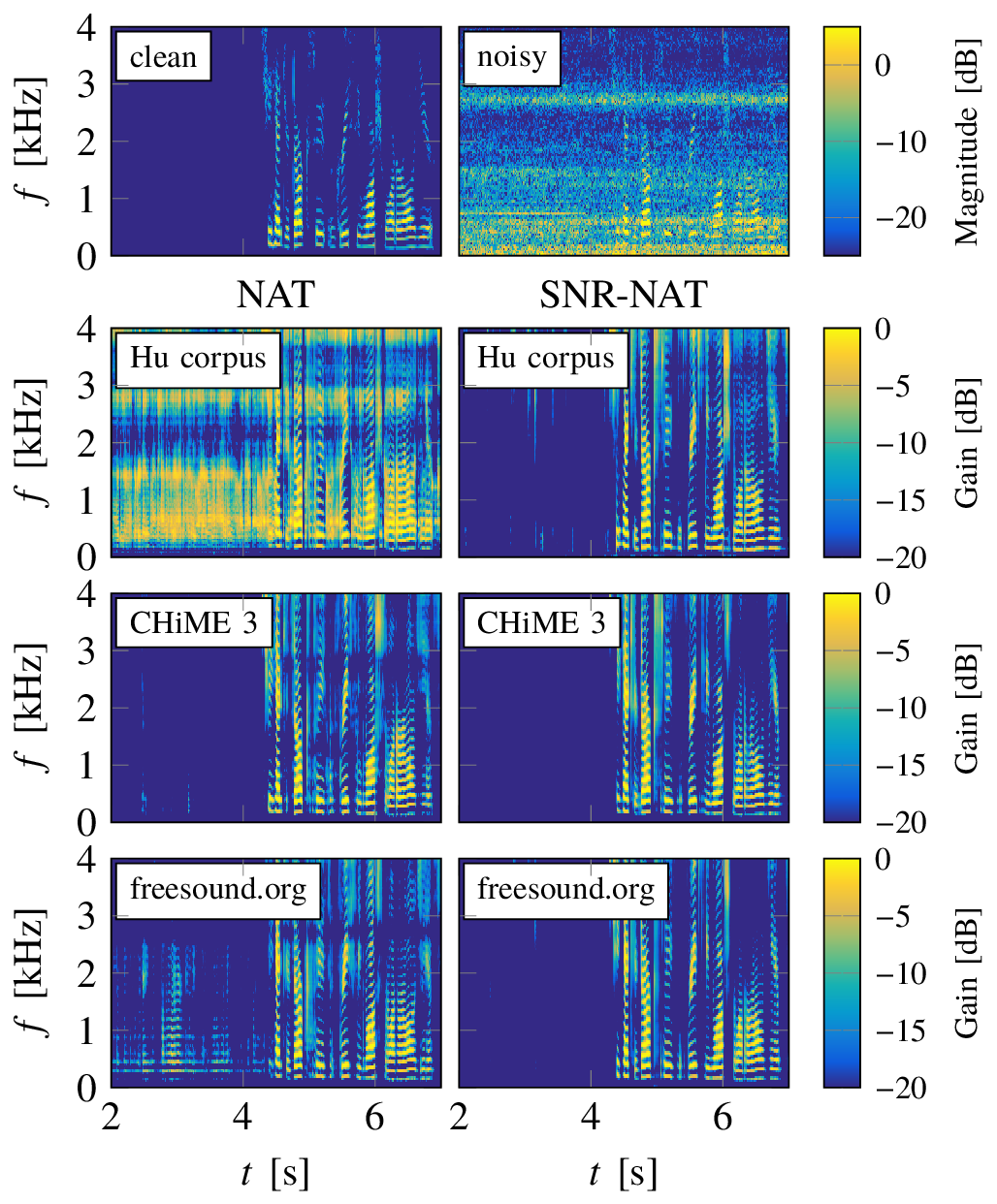
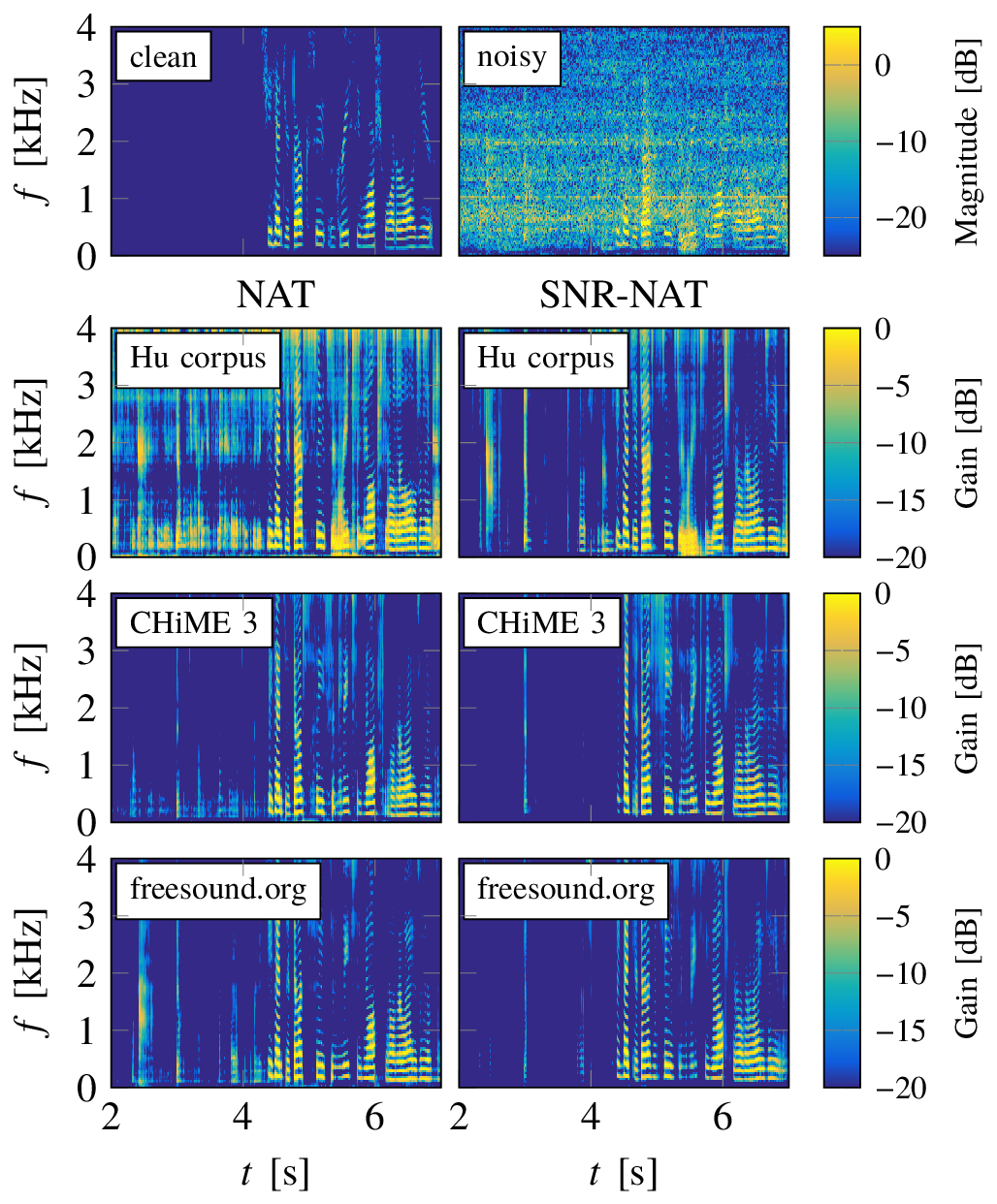
Lab Video
The following video has been recorded in our lab and demonstrates how the DNN based approaches and a conventional speech enhancement approach compare in real-world situations. In the first part, the advantage of SNR-NAT features are demonstrated and compared to conventional features using a feed-forward network. Furthermore, the advantage of DNN based speech enhancement schemes in non-stationary noises are highlighted in the second part of the video.
Sound Examples from CHiME 3 Challenge
The following examples where generated from the real recordings in the CHiME 3 evaluation corpus [10], [11]. The sound examples in the upper table are processed using the feed-forward network, while the sound examples in the lower table are processed using the LSTM network. The networks in both tables are trained on the three different sound corpora and three different input features as described above.
The sound examples demonstrates the effects that have been highlighted in the analysis in our paper [1]. When using a training set with only small little noise data such as the Hu corpus, the DNN based enhancement approaches have trouble reducing the noise if the logarithmized periodogram or NAT features are used for training. Similar effects can also be sometimes heard if the CHiME 3 corpus is used for training which is large in size but is less diverse. This is especially the case when comparing logarithmized periodogram features to NAT or SNR-NAT for the feed-forward networks.
Using large and diverse training datasets and complex networks, i.e., the freesound.org noise corpus and the LSTM networks, the differences between the approaches become smaller and are less clearly audible. This shows that despite the somewhat lower results in Fig. 2 and Fig. 3 in [1] for the combination of LSTM network and freesound.org corpus, the proposed SNR-NAT features also cope well with real-world noisy recordings.
| Feedforward | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Hu corpus | Chime | Freesound | |||||||||
| # | Noisy | Conv. | Per. | NAT | SNR-NAT | Per. | NAT | SNR-NAT | Per. | NAT | SNR-NAT |
| 1 | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ |
| 2 | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ |
| 3 | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ |
| 4 | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ |
| 5 | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ |
| 6 | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ |
| LSTM | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Hu corpus | Chime | Freesound | |||||||||
| # | Noisy | Conv. | Per. | NAT | SNR-NAT | Per. | NAT | SNR-NAT | Per. | NAT | SNR-NAT |
| 1 | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ |
| 2 | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ |
| 3 | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ |
| 4 | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ |
| 5 | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ |
| 6 | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ | ▸ |
References
[1] R. Rehr and T. Gerkmann, “SNR-Based Features and Diverse Training Data for Robust DNN-Based Speech Enhancement,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021.
[2] Y. Xu, J. Du, L.-R. Dai, and C.-H. Lee, “Dynamic noise aware training for speech enhancement based on deep neural networks,” in Interspeech, 2014, pp. 2670–2674.
[3] A. Kumar and D. Florencio, “Speech enhancement in multiple-noise conditions using deep neural networks,” in Interspeech, 2016, pp. 3738–3742.
[4] T. Gerkmann and R. C. Hendriks, “Noise power estimation based on the probability of speech presence,” in IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), 2011, pp. 145–148.
[5] T. Gerkmann and R. C. Hendriks, “Unbiased MMSE-based noise power estimation with low complexity and low tracking delay,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 20, no. 4, pp. 1383–1393, May 2012.
[6] Y. Ephraim and D. Malah, “Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator,” IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 32, no. 6, pp. 1109–1121, Dec. 1984.
[7] C. Breithaupt, T. Gerkmann, and R. Martin, “A novel a priori SNR estimation approach based on selective cepstro-temporal smoothing,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2008, pp. 4897–4900.
[8] G. Hu, “A corpus of nonspeech sounds.” http://web.cse.ohio-state.edu/pnl/corpus/HuNonspeech/HuCorpus.html, 2005.
[9] Y. Xu, J. Du, Z. Huang, D. Li-Rong, and C.-H. Lee, “Multi-Objective Learning and Mask-Based Post-Processing for Deep Neural Network Based Speech Enhancement,” in Interspeech, 2015.
[10] J. Barker, R. Marxer, E. Vincent, and S. Watanabe, “The third ‘CHiME’ speech separation and recognition challenge: Dataset, task and baselines,” in IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), 2015, pp. 504–511.
[11] J. Barker, R. Marxer, E. Vincent, and S. Watanabe, “The third ‘CHiME’ speech separation and recognition challenge: Analysis and outcomes,” Computer Speech & Language, vol. 46, pp. 605–626, Nov. 2017.
[12] J. S. Garofolo et al., “TIMIT acoustic-phonetic continuous speech corpus.” Linguistic Data Consortium, Philadelphia, 1993.
[13] A. Varga and H. J. M. Steeneken, “Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems,” Speech Communication, vol. 12, no. 3, pp. 247–251, 1993.