Theses
Here you can find what which topics our students are currently working on. If you are interested in one of these topics, please reach out to the listed contact person. If you have your own idea for a thesis topic in the field of signal processing, please contact us and we will see how we can develop your idea together.
Proposal 2: Phase-Aware Speech Enhancement
The ease of speech understanding in noise degrades greatly with decreasing signal-to-noise ratios. This effect is even more severe for hearing impaired people, hearing aid users and cochlear implant users. Noise reduction algorithms aim at reducing the noise to facilitate speech communication. This is particularly difficult when the noise signal is highly variant.
Many speech enhancement algorithms are based on a representation of the noisy speech signal in the short-time Fourier transform domain (STFT) domain. In this domain, speech is represented by the STFT magnitude and the STFT phase. In the last two decades research in speech enhancement algorithms mainly focused on improving the STFT magnitude, while the STFT phase was left unchanged. However, more recently, researchers pointed out that phase processing may improve speech enhancement algorithms further.
This thesis aims at implementing, analyzing and developing algorithms for phase processing. The overall goal is to obtain intelligible, high quality speech signals even from heavily distorted recordings in real-time. Of special interest in this context are the robust estimation of the clean speech phase from the noise-corrupted recording, the interplay between the traditional enhancement of spectral amplitudes and the recent developments in spectral phase enhancement, as well as the potential of modern machine learning techniques like deep learning.
First, existing approaches will be implemented and analyzed with respect to their strengths and weaknesses. Starting from this, new concepts to push the limits of the current state-of-the-art will be developed and realized. Finally, the derived algorithm(s) will evaluated and compared to existing approaches by means of instrumental measures and listening experiments. Depending on the outcome of this work, we encourage and strive for a publication of the results at a scientific conference or journal.
Experience and basic knowledge of signal processing are definitely helpful but not mandatory.
Contact: Tal Peer, Prof. Timo Gerkmann (UHH)

Proposal 3: Sound Source Localization and Tracking
 Humans are remarkably skilled at localizing sound sources in complex acoustic environments. This ability is largely due to spatial cues, such as time and level differences, that our brain can interpret. In technical systems, microphone arrays enable similar spatial processing, allowing algorithms to estimate the positions of speakers and track them over time. Accurate and low-latency speaker tracking is a key component in many downstream applications, such as steering spatially selective filters (SSFs) that enhance a specific target speaker in multi-speaker scenarios.
Humans are remarkably skilled at localizing sound sources in complex acoustic environments. This ability is largely due to spatial cues, such as time and level differences, that our brain can interpret. In technical systems, microphone arrays enable similar spatial processing, allowing algorithms to estimate the positions of speakers and track them over time. Accurate and low-latency speaker tracking is a key component in many downstream applications, such as steering spatially selective filters (SSFs) that enhance a specific target speaker in multi-speaker scenarios.
Traditional localization methods rely on statistical models and techniques such as time difference of arrival (TDOA) estimation, steered response power (SRP), or subspace-based methods like MUSIC. While these techniques can be effective, they are often based on oversimplified statistical assumptions and struggle under real-world conditions. On the other hand, data-driven approaches can learn complex mappings between spatial features and speaker positions, thereby improving robustness in challenging noisy and reverberant environments. However, since they are usually very resource intensive, their practical applicability is limited. Hybrid methods address this issue by incorporating lightweight neural networks (NNs) into traditional estimation frameworks to refine the underlying statistical models while retaining a small computational overhead.
In this thesis, we will investigate low-complexity speaker localization and tracking algorithms that can reliably provide target direction estimates in real-time. These estimates are intended to guide deep SSFs in order to continuously enhance a target speaker in dynamic multi-speaker scenarios. Instead of completely replacing classical spatial filtering with deep learning, the focus will be on developing hybrid approaches as a lightweight front-end. The aim is to explore the trade-off between localization accuracy, robustness, and algorithmic complexity in realistic acoustic settings.
Basic knowledge of statistical signal processing, machine learning, and programming experience in Python is required for this thesis. Familiarity with machine learning frameworks such as PyTorch is an advantage but not strictly necessary.
Contact: Jakob Kienegger, Alina Mannanova, Prof. Timo Gerkmann
Proposal 4: Multichannel Speech Enhancement

Humans have impressive capabilities to filter background noise when focussing on a specific target speaker. This is largely due to the fact that humans have two ears that allow for spatial processing of the received sound. Many classical multichannel speech enhancement algorithms are also based on this approach. So-called beamformers (e.g. delay-and-sum beamformer or minimum variance distortionless response beamformer) enhance a speech signal by emphasizing a signal from the desired direction and attenuating signals from other directions.
In the field of single-channel speech enhancement, the use of machine learning techniques and in particular deep neural networks (DNNs) led to significant improvements. These networks can be trained to learn arbitrarily complex nonlinear functions. As such, it seems possible to improve the multichannel speech enhancement performance by using DNNs to learn spatial filters that are not restricted to a linear processing model as beamformers are.
In this thesis, we will investigate the potential of DNNs for multichannel speech enhancement. As a first step, existing DNN-based multichannel speech enhancement algorithms will be implemented and evaluated. Of particular importance is the question under which circumstances the ML-based approaches outperform existing methods. The gained insights and experience can then be used to improve the existing DNN-based algorithms.
Basic knowledge of signal processing, machine learning, and programming experience in any language (most preferable Python) is required for this thesis. Experience with a machine learning toolbox (e.g. PyTorch or TensorFlow) is helpful but not mandatory.
Contact: Alina Mannanova, Jakob Kienegger, Prof. Timo Gerkmann
Proposal 6: Real-Time Diffusion-based Speech Enhancement
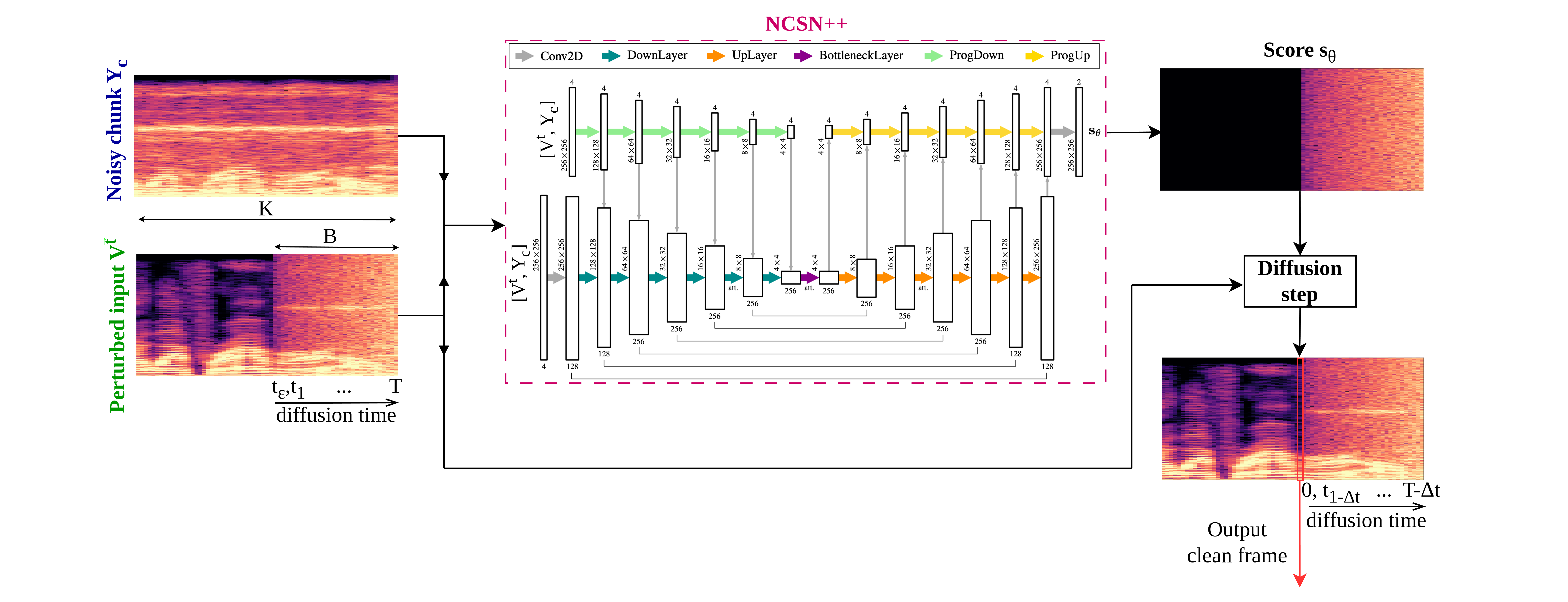
Diffusion models represent a leading class of generative methods and have recently advanced the state of the art in speech enhancement. The Signal Processing Group has contributed several publicly recognised systems, including SGMSE+, STORM, and BUDDY.
Despite their excellent perceptual quality, current diffusion‑based approaches are unsuitable for online operation because they require many neural network evaluations per time frame.
The objective of this project is to develop and evaluate techniques that enable real‑time diffusion speech enhancement. Potential avenues include Diffusion Buffer , knowledge distillation, and latent‑space diffusion;
The proposed algorithms will be implemented and demonstrated in our laboratory on a laptop GPU. We are aiming for further optimization for laptop CPU or smartphone class hardware.
Please be familiar with Python and PyTorch; basic knowledge of digital signal processing, Bayesian statistics and deep learning is necessary, but passion and curiosity are most important.
Contact: Rostislav Makarov, Bunlong Lay, Prof. Timo Gerkmann