Cross-modal Interaction in Natural and Artificial Cognitive Systems (CINACS)
General Information
Our research concept focuses on the topics of cross-modal interactions and integration. A unique and novel feature of the project is the integration of biological and engineering/robotics approaches, allowing for the creation of complementary knowledge in those fields. We also expect the exploitation of the insights obtained for potential clinical and technical applications.
Research in the Knowledge Technology Group is inspired by principles found in natural systems (biology, cognition, and neurosciences). In particular there is a common interest in the foundations and applications of intelligent systems. The topics addressed in the research agenda include multisensory perception, representation and attention, cross-modal learning, association and problem-solving, and multimodal communication.
Leading Investigator: Prof. Dr. S. Wermter, Dr. C. Weber
Associates: J. Bauer, J. D. Chacón, J. Kleesiek
Multi-Modal Orientation Alignment for Action Selection Based on Superior Colliculus - Johannes Bauer
The superior colliculus (sc) is a region in the brain that is widely recognized to play a vital role in integrating different kinds of sensory information spacially, and generating motor responses, particularly orienting eye movements. An especially interesting aspect of the superior colliculus is its ability to enhance weak or noisy input to the individual sensory modalities by combining them, and suppressing one input in favor of another depending on its quality and modality in case inputs disagree.
In this project, we are going to build and evaluate neural network models for the processes in the sc, paying special attention to enhancement and depression. Our goal in this is to make aligning multi-sensory information and action selection in robots more robust and thus help them navigate in noisy environments. In this early stage of our project, we are collecting what is known about the workings of enhancement and depression to create a uniform picture of the state of the art. We are also selecting likely candidates for neural network types for our model.
Action-Driven Perception - Neural Architectures for Sensorimotor Laws - Jens Kleesiek
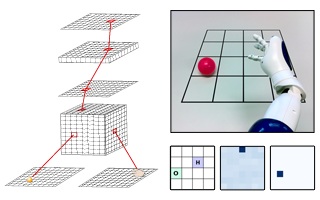
Actions are fundamental for perception and help to distinguish the qualities of sensory experiences in different sensory modalities (e.g. 'seeing' or 'touching'). The intimate relation between action, perception and cognition has been emphasized in philosophy and cognitive science for a long time, not only by putting forward an enactive approach that suggests that cognitive behavior results from interaction of organisms with their environment [Varela 1991]. However, most of the current robotic approaches do not rely on active perception. A robot is embodied and it has the ability to act and to perceive. Its action-triggered sensations are guided by the physical properties of the body, the world and the interplay of both. This concept is exploited to solve various (robotic) tasks such as reaching towards an object (figure on the left) and visually guided navigation (figure below).
For successful grasping two steps are necessary. First, the position of the target has to be identified and it has to be known in which relation this position is with respect to the hand. To learn the relation of object and hand as well as the movement of the hand towards the object, a novel two-layer neural architecture combining unsupervised learning of Sigma-Pi neurons and reinforcement learning (RL) has been developed [Kleesiek 2010]. In RL the prediction error between estimates of neighboring state values is determined and in turn used to modulate learning of action weights that encode both, value function and action strategy. We show that this prediction error can be used at the same time to adapt the weights of the Sigma-Pi neurons, leadingto sensorimotor laws required for successful reaching.
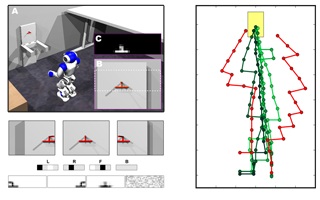
A similar concept can also be exploited for the autonomous visual navigation of a humanoid robot [Kleesiek 2011]. The robot learns sensorimotor laws and visual features simultaneously and exploits both for navigation towards a docking position. The control laws are trained using a two-layer network consisting of a feature (sensory) layer that feeds into an action layer. Again, the RL prediction error modulates not only the action but at the same time the feature weights [Weber 2009]. Under this influence, the network learns interpretable visual features and assigns goal-directed actions.
Project Publications
|
Bauer, J., Dávila-Chacón, J., Strahl, E., Wermter, S. Smoke and Mirrors - Virtual Realities for Sensor Fusion Experiments in Biomimetic Robotics. Proceedings of the 2012 IEEE International Conference on Multisensor Fusion and Information Integration (MFI 2012), pp. 114-119, IEEE. Hamburg, DE, September 2012. |
|
|
Dávila-Chacón, J., Heinrich, S., Liu, J., Wermter, S. Biomimetic Binaural Sound Source Localisation with Ego-Noise Cancellation. Proceedings of the 22nd International Conference on Artificial Neural Networks (ICANN 2012), LNCS 7552, pp. 239-246, Springer. Lausanne, CH, September 2012. |
|
|
Bauer, J., Weber, C., Wermter, S. A SOM-Based Model for Multi-Sensory Integration in the Superior Colliculus. Proceedings of the International Joint Conference on Neural Networks (IJCNN 2012), pp. 3245-3252, IEEE. Brisbane, AU, June 2012. |
|
|
Kleesiek, J., Badde, S., Wermter, S., Engel, A.K. What Do Objects Feel Like? - Active Perception for a Humanoid Robot. Proceedings of the 4th International Conference on Agents and Artificial Intelligence (ICAART 2012), Vol. 1, pp. 64-73, SciTePress. Vilamoura, PT, January 2012. |
|
|
Kleesiek, J., Weber, C., Wermter, S., Engel, A.K. Reward-Driven Learning of Sensorimotor Laws and Visual Features. Proceedings of the 1st Joint IEEE International Conference on Development and Learning and on Epigenetic Robotics, Vol. 2, pp. 1-6, IEEE. Frankfurt, DE, August 2011. |
|
|
Kleesiek J., Engel A.K., Wermter S., Weber C. Object Affordances in the Context of Sensory Motor Contingencies. Front. Comput. Neurosci. Conference Abstract: Bernstein Conference on Computational Neuroscience, Frontiers. Berlin, DE, September 2010. |
|
Further Information
Project Website: https://cinacs.informatik.uni-hamburg.de/
The CINACS International Research Training Group is funded by the DFG (IGK 1247). It is a joint project of the University of Hamburg and Tsinghua University of Beijing, provides outstanding and internationally competitive research and PhD training.