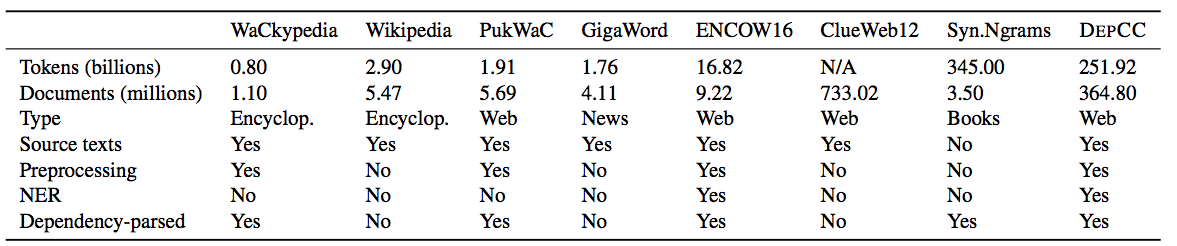
This page contains a large dependency parsed corpus which was constructed from the web crawls of the CommonCrawl project. DepCC is the largest to date (see the table below) linguistically analyzed corpus in English including 365 million documents, composed of 252 billion tokens and 7.5 billion of named entity occurrences in 14.3 billion sentences from a web-scale crawl. The sentences are processed with a dependency parser and with a named entity tagger and contain provenance information, enabling various applications ranging from training syntax-based word embeddings based on to open information extraction and question answering. We demonstrate the utility of this corpus on the verb similarity task by showing that a distributional model trained on our corpus yields better results than models trained on smaller corpora, like Wikipedia. This distributional model outperforms the state of art models of verb similarity trained on smaller corpora on the SimVerb3500 dataset.
Comparison of existing large text corpora for English with the DEPCC corpus:
Using the Corpus
The files are distributed currently from a server at Hamburg University: http://ltdata1.informatik.uni-hamburg.de/depcc. In addition, you can access the corpus from Amazon S3 as our corpus was published permanently by CommonCrawl as a part of their "contrib" resources: https://commoncrawl.s3.amazonaws.com/contrib/depcc/CC-MAIN-2016-07/index.html. If you use the corpus on Amazon you do not need to download it: you can directly use it from the S3 file system for free (in the us-east-1 zone) from any Amazon EC2 instance.
Data Format
The documents are encoded in the CoNLL-U format. The corpus is delivered in as a set of gz archives. A fragment of a produced document is presented below: a document header plus a sentence are shown. Here, ID is a word index, FORM is word form, LEMMA is lemma or stem of word form, UPOSTAG is universal part-of-speech tag, XPOSTAG is language-specific part-of-speech tag, FEATS is a list of morphological features, HEAD is head of the current word, which is either a value of ID or zero, DEPREL is universal dependency relation to the HEAD, DEPS is enhanced dependency graph in the form of head-deprel pairs, and NER is named entity tag.
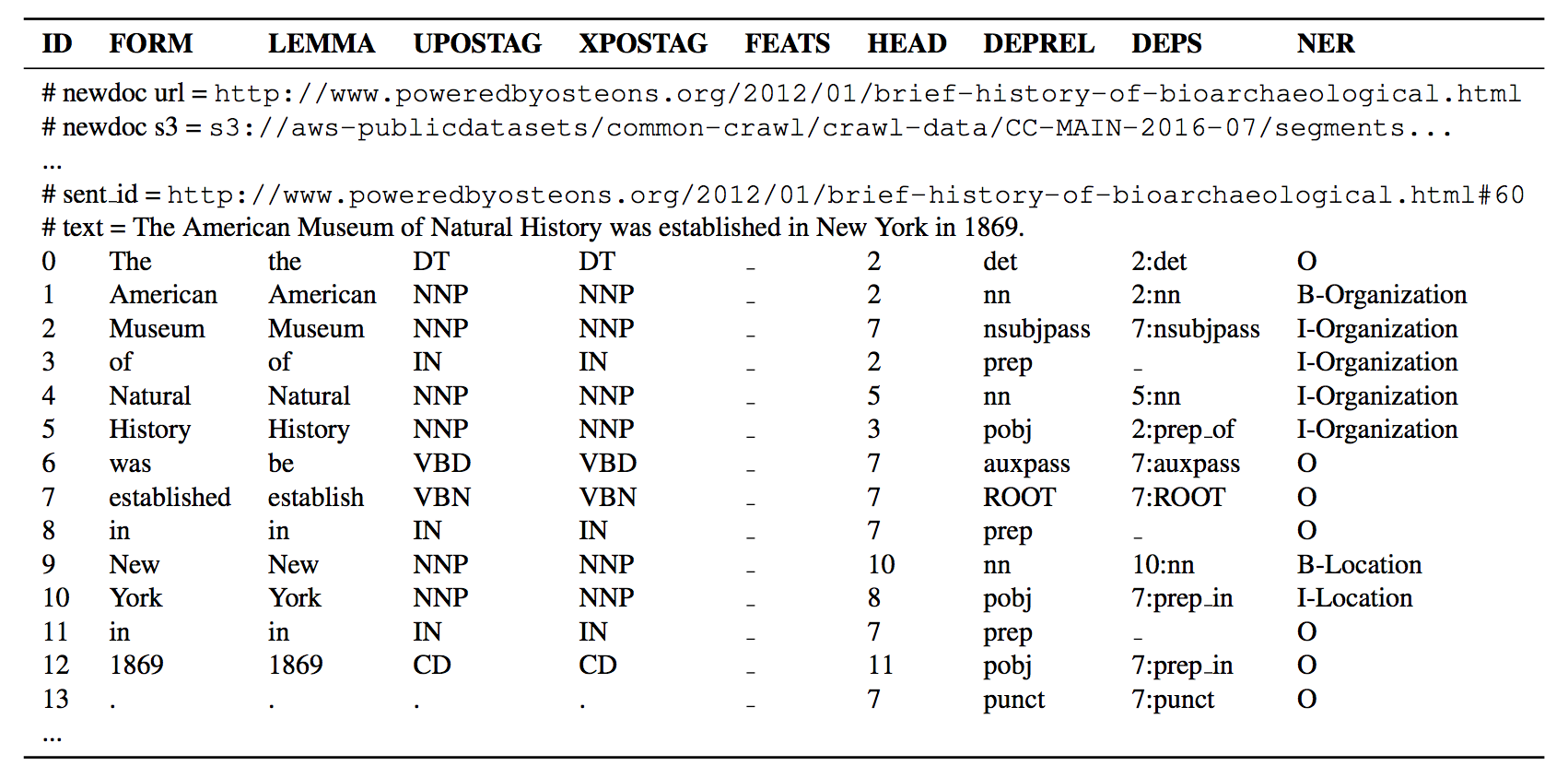
Download Code for Building Corpus from a CommonCrawl
The building of the corpus involves three stages illustrated in the figure below: First, crawling of the web pages is performed. This is done by the crawler of the CommonCrawl project. Second , preprocessing of the corpus is performed using the c4corpus tool based on the MapReduce framework. Finally, we use the lefex tool based on the MapReduce framework to perform linguistic analysis of the corpus. In particular, the CoNLL class is used: an example script for running it is available here. The tool can be launched on the Hadoop cluster to reach optimal performance on the large datasets.

Download Large-Scale Distributional Model Trained on the Corpus
The files are distributed currently from a server at Hamburg University: http://ltdata1.informatik.uni-hamburg.de/depcc. The distributional models are computed the basis of the corpus using the JoBimText framework. Each model is located in a separate directory with two subdirectories containing sparse word vectors (FeaturesPruned) and word similarity graph, aka distributional thesaurus (SimPruned).