GermEval 2020 Shared Task on the Classification and Regression of Cognitive and Motivational style from Text
Important: We with all institutions involved acknowledge that the boundary between science and pseudo-science is contested and highly politicized when the science of IQ is involved.
Please notice the section on the aptitude test and criticism or visit the provided link on that topic here under 'Aptitude test and criticism'.
General Information
The validity of high school grades as a predictor of academic development is controversial. Researchers have found indications that linguistic features such as function words used in a prospective student's writing perform better in predicting academic development (Pennebaker et al., 2014) than other methods such as GPA values.
During an aptitude test, participants are asked to write freely associated texts to provided questions, regarding shown images. Psychologists can identify so-called implicit motives from those expressions. Implicit motives are unconscious motives, which are measurable by operant methods. Psychometrics are metrics, which can be utilized for assessing psychological phenomena. One flawed but well-known example are the infamous ink dots, which ought to be described. Operant methods, in turn, are psychometrics, which is collected by having participants write free texts (Johannßen et. al, 2019). Those motives are said to be predictors of behavior and long-term development from those expressions (McClelland, 1988, Scheffer 2004, Schultheiss, 2008).
From a small sample of an aptitude test collected at a college in Germany, the classification and regression of cognitive and motivational styles from a text can be investigated. Such an approach would extend sole text classification and could reveal insightful psychological traits.
Operant motives are unconscious intrinsic desires that can be measured by implicit or operant methods, such as the Operant Motive Test (OMT) or the Motive Index (MIX). Psychologists label these textual answers with one of five motives (M - power, A - affiliation, L - achievement, F - freedom, 0 - zero) and corresponding levels (0 to 5), which roughly describe the emotional mood from positive to negative. The identified motives allow psychologists to predict behavior and longterm development. For our task, we provide extensive amounts of textual data from both, the OMT and MIX, paired with IQ and high school grades and labels.
With this task, we aim to foster novel research within the context of NLP and the psychology of personality and emotion. This task is focusing on utilizing German psychological text data for researching the connection of text to cognitive and motivational style. For this, contestants are asked to build systems to restore an artificial 'rank' as well as performing classification on an image description that psychologists can investigate on implicit motives.
The shared task is organized by Dirk Johannßen, Chris Biemann, Steffen Remus, and Timo Baumann from the Language Technology group of the University of Hamburg (Germany), as well as David Scheffer from the NORDAKADEMIE Elmshorn (Germany). The data was provided by Nicola Baumann from the Universität Trier and Gudula Ritz from the Impart GmbH (Germany).
This task is accompanied by a Codalab website: https://competitions.codalab.org/competitions/22006
Proceedings
- GermEval 2020 Task 1: Classification and Regression of Cognitive and Motivational Style from Text
Dirk Johannßen, Chris Biemann, Steffen Remus, Timo Baumann, and David Scheffer - Idiap & UAM participation at GermEval 2020: Classification and Regression of Cognitive and Motivational Style from Text
Esáu Villatoro-Tello, Shantipriya Parida, Sajit Kumar, Petr Motlicek, and Qingran Zhan - Predicting Cognitive and Motivational Style from German Text using Multilingual Transformer Architecture
Henning Schäfer, Ahmad Idrissi-Yaghir, Andreas Schimanowski, Michael Raphael Bujotzek, Hendrik Damm, Jannis Nagel, and Christoph M. Friedrich - Predicting Educational Achievement Using Linear Models
Çăgrı Çöltekin - Ethical considerations of the GermEval20 Task 1. IQ assessment with natural language processing: Forbidden research or gain of knowledge?
Dirk Johannßen, Chris Biemann, and David Scheffer
Please visit the official SWISSTEXT YouTube channel with the SWISSTEXT + KONVENS playlist, which includes the GermEval20 Task 1 video presentations:
https://www.youtube.com/channel/UCGsc1P6JWvWBxHwWPvnQ43A/playlists
aptitude-test-and-criticism
The Aptitude Test, college and criticism
Since 2011, the private university of applied sciences NORDAKADEMIE performs an aptitude college application test.
Zimmerhofer and Trost (2008, p. 32ff.) describe the developments of the German Higher Education Act. A so-called Numerus Clausus (NC) Act from 1976 and 1977 ruled that colleges in Germany with a significant amount of applications have to employ a form of selection mechanism. For most colleges, the NC was the threshold for many applicants. Even though this value is more complex, it roughly can be understood as a GPA threshold. Since this second Higher Education Act, colleges are also free to employ alternate selection forms, as long as they are scientifically sound, transparent and commonly accepted in Germany (BVerfGE 43, 291 - numerus clausus II).
Even though Hell, Trapmann und Schuler (2008, p. 46) found the correlation coefficient of high school grades of r = 0.517 to be the most applicable measure for academic suitability, criticism emerged as well. The authors criticized that the measure of grades by just one single institution (i.e. a high school) does not reflect upon the complexity of such a widely questioned concept of intellectual ability. Schleithoff (2015, p. 6) researched the high school grade development of different German federal states on the issue of grade inflation in Germany and found evidence, that supports this claim. Furthermore, in most parts of Germany, the participation grade makes up 60% of the overall given grade and thus is highly subjective.
Since operant motives are said to be less prone to subjectivity, the NORDAKADEMIE decided to employ an assessment center (AC) for research purposes and a closely related aptitude test for the application procedure (NORDAKADEMIE, 2018). Rather than filtering the best applicants, the NORDAKADEMIE aims with the test for finding and protecting applicants that they suspect to not match the necessary skills required at the college (Sommer, 2012). Thus, every part of the aptitude test is skill-oriented.
During an hour-long aptitude test, participants are asked to write freely associated texts to provided questions and images. Those motives are said to be predictors of behavior and long-term development from those expressions. This test contains multiple parts, e.g. a math- and an English test, Kahnemann scores, intelligence quotient (IQ) scores, a visual questionnaire, knowledge questions to the applied major or the implicit motives, called the Motive Index (MIX).
The MIX measures implicit or operant motives by having participants answer questions to those images like the one displayed on the Tasks tab such as "who is the main person and what is important for that person?" and "what is that person feeling". Furthermore, those participants answer the question of what motivated them to apply for the NORDAKADEMIE.
Even though parts of this test are questionable and are currently under discussion, no single part of this test leads to an application being rejected. Only when a significant amount of those test parts are well below a threshold, applicants may not enter the second stage of the application process, which is applying at a private company due to the integrated study program the college offers. Roughly 10 percent of all applicants who took this aptitude test get rejected from this aptitude test. Furthermore, every applicant has the option to decline the data to be utilized for research purposes and still can apply to study at the Nordakademie. All anonymized data instances emerged from college applicants that consented for the data to be utilized in this type of research setting and have the opportunity to see any stored data or to have their personal data deleted at any given moment (e.g. sex, age, the field of study).
Any research performed on this aptitude test or the annually conducted assessment center (AC) at the NORDAKADEMIE is under the premise of researching methods of supporting personnel decision-makers, but never to create fully automated, stand-alone filters (NORDAKADEMIE, 2019). First of all, since models might always be flawed and could inherit biases, it would be highly unethical. Secondly, the German law prohibits the use of any - technical or non-technical - decision or filter system, which can not be fully and transparently be explained. Aptitude diagnostics in Germany are highly legally regulated.
The most debated upon the part of the aptitude test is the intelligence quotient (IQ). Intelligence in psychology is understood as results measured by an intelligence test (and thus not the intelligence of individuals itself). Furthermore, intelligence is always a product of both, genes and the environment. Even though there are hints that the IQ does not measure intellectual ability but rather cognitive and motivational style (DeYoung, 2011), it is defined and broadly understood as such.
Mainly companies in Europe employ IQ tests for selecting capable applicants. In the United Kingdom, roughly 69 percent of all companies utilize the IQ. In Germany, the estimate is 13 percent (Nachtwei & Schermuly, 2009).
Since IQ tests only measure the performance in certain tasks that rather ask for skill in certain areas (logics, language, problem-solving) than cognitive performance, such intelligence tests should rather be called comprehension tests. Minorities can be discriminated by a biased due to unequal environmental circumstances and measurements in non-representative groups (Rushton, & Jensen, 2005). One result of research on the connection between implicit motives and intelligence testing could help to improve early development and guided support.
It is this bias, which leads to unequal opportunities especially in countries where there is a rich diversity among the population. Intelligence testing has had a dark history. Eugenics during the great wars e.g. in the US by sterilizing citizens (Buck v. Bell) or in Germany during the Third Reich are some of the most gruesome parts of history.
But even in modern days, the IQ is misused. Recently, IQ scores have been used in the US to determine which death row inmate shall be executed and which might be spared. Since IQ scores show a too large variance, the Supreme Court has ruled against this definite threshold of 70 (Hall v. Florida). However, Sanger (2015) has researched an even more present practice of 'racial adjustment', adjusting the IQ of minorities upwards to take countermeasures on the racial bias in IQ testing, resulting in death row inmates, which originally were below the 70 points threshold, to be executed.
There is an ethical necessity to carefully view, understand and research the way intelligence testing is conducted and how those scores are - if at all - correlated with what we understand as 'intelligence', as they might be mere cognitive and motivational styles. Further valuable research can be conducted to investigate connections between other personality tests such as implicit motives with intelligence or comprehension tests. Racial biases are measurable, variances are great and many critics state that IQ scores reflect upon skill or cognitive and motivational style rather than real intelligence as it is broadly understood.
Regarding commercial interests: While of course there is interest from the people that provide this data, we find it remarkable that the data is made available freely. We aim to share the data with the international scientific community, to better understand and learn from the data and discuss interesting findings publicly, for the benefit of everyone. Note that this is the entire data that currently exists, not a sub-sample, so it likewise supports the commercial interests of competitors. Furthermore, professors at Universities for Applied Sciences in Germany (especially private colleges) are supposed to work in the private industry on their specific research field (Wikipedia, 2019). Thus, an alleged conflict of interest is a result of the educational system in Germany. The interests of the task organizers are strictly scientific. There is no funding for this task, neither from the public nor from commercial sources.
faqs
FAQs
Evaluation
System submissions are done in teams. There is no restriction on the number of people in a team. However, keep into consideration that a participant is allowed to be in multiple teams, so splitting up into teams with overlapping members is a possibility. Every participating team is allowed to submit 3 different systems to the competition. For submission in the final evaluation phase, every team must name their submission (.zip and the actual submission .txt file) in the form "[Teamname]__[Systemname]" (note the two underscores!). Important: Please do not include more than one double underscore in the naming scheme. E.g. your submission could look like
Funtastic4__SVM_ensemble1.zip
|
+-- Funtastic4__SVR_TF_IDF_ensemble1_task1.txt
Funtastic4__SVM_ensemble1.zip
|
+-- Funtastic4__SVC_TF_IDF_ensemble1_task2.txtWe also ask you to put exactly this name into the description before submitting your system. This identification method is needed to correctly associate each submitted system with its description paper. Thus, please make sure to write the name exactly as it will appear in your description paper (i.e. case sensitive). If your submission does not follow these rules it might not be evaluated. The evaluation script has been adopted for a formality check.
Only the person who submits is required to register for the competition. All team members need to be stated in the description paper of the submitted system. The last submission of a system will be used for the final evaluation. Participants will see whether the submission succeeds, however, there will be no feedback regarding the score. The leaderboard will thus be disabled during the test phase.
The evaluation script is provided with the data so that participants can still evaluate their data splits. The zip located at the Data section contains the evluate.py program among other files. If you use the standalone functionality of this file, you need to call it as:
python evaluate.py <input_dir> <output_dir>
The submission files have to comply with the tab-separated format as follows for Subtask 1, reproducing the target rank (as averaged z-standardized scores of a participant) relative to all participants in a collection (i.e. test / dev / train):
student_ID rank and for Task 2:
UUID motive level Important: Please always include the header "task1" or "task2", directly followed by the gold- or your predicted lines. For references, please visit the Codalab task website and download the exemplary data or download it here in the Data section.
On task1, the script computes multiple correlation coefficients. The Pearson rank correlation coefficient will be the main evaluation metric. On task2, the script computes for each class precision, recall and F1 score. As a summarizing score, the tool computes accuracy and macro-average precision, recall and F1 score.
Although the evaluation tool outputs several evaluation measures, the official ranking of the systems will be based on the macro-average F1 score for task2 or the Pearson correlation coefficient for task1 only. Please remember this when tuning your classifiers. A classifier that is optimized for the accuracy or the Spearman correlation coefficient may not necessarily produce optimal results in terms of the macro-average F1 score.
The evaluation tool on Codalab and the download versions is the same and accepts both tasks simultaneously.
System submissions are done in teams. There is no restriction on the number of people in a team. However, keep into consideration that a participant is allowed to be in multiple teams, so splitting up into teams with overlapping members is a possibility. Every participating team is allowed to submit as many different systems to the competition as they wish.
Tasks
Subtasks
The shared task on classification and regression of cognitive and motivational style of text consists of two subtasks, described below. You can participate in any of them, may use external data and/or utilize the other data respectively for training, as well as perform e.g. multi-task or transfer learning. Both tasks are closely related to the main research objective: implicit motives. Those motives are said to describe the intrinsic desires of students and allow for psychologists to, after identifying those motives, make statements on long-term behavior and development. For this first task, the so-called Motive Index (MIX) texts are the basis for classifying cognitive and motivational style. For the second task, so-called Operant Motives (OMT), which are implicit motives as well, can be classified into main motives and so-called levels, describing the emotional exertion expressed.
We encourage every participant to also include ethical positions and discussions in their system descriptions that can be the basis for an insightful and reflected podium discussion during the workshop session at GermEval 2020.
Subtask 1: Regression of artificially ranked cognitive and motivational style
This task has yet never been researched and is open: It is neither certain, whether this task can be achieved, nor how well this might be possible due to the novelty and sparsity of research.
The task is to predict measures of cognitive and motivational style solemnly based on text. For this, z-standardized high school grades and intelligence quotient (IQ) scores of college applicants are summed and globally 'ranked'. This rank is utterly artificial, as no applicant in a real-world-setting is ordered in such fashion but rather there is a certain threshold over the whole of the hour-long aptitude test with multiple different test parts, that may not be undergone by applicants. Only about 10% of initial applicants get declined and may not proceed to a second step, the application at a private company. The resulting system would be of no real-world use as those motive texts still ought to be collected and strict European data protection laws prohibit any use of unexplainable, intransparent aptitude systems (Sommer, 2012 and NORDAKADEMIE b, 2019).
The goal of this subtask is to reproduce this 'ranking', systems are evaluated by the Pearson correlation coefficient between system and gold ranking. An exemplary illustration can be found in the Data area. We are especially interested in the analysis of possible connections between text and cognitive and motivational style, which would enhance later submission beyond the mere score reproduction abilities of a submitted system.
One z-standardized example instance looks as follows (including spelling errors made by the participant) with the unique ID (consisting of studentID_imageNo_questionNo), a student ID, an image number, an answer number, the German grade points, the English grade points, the math grade points, the language IQ score, the math IQ score and the average IQ score (all z-standardized)
The data is delivered in two files, one containing participant data, the other containing sample data, each being connected by a student ID. The rank in the sample data reflects the averaged performance relative to all instances within the collection (i.e. within train / test / dev), which is to be reproduced for the task.
student_ID image_no answer_no UUID MIX_text
1034-875791 2 2 1034-875791_2_2 Die Person fühl sich eingebunden
in die Unterhatung.
student_ID german_grade english_grade math_grade lang_iq logic_iq
1034-875791 -0.08651999119820285 0.3747985587188588 0.5115559707967757
-0.010173719700624676 -0.13686707618782515
student_ID rank
1034-875791 15
The training data set contains 80% of all available data, which is 62,280 expressions and the development and test sets contain roughly 10% each, which are 7,800 expressions for the dev set and 7,770 expressions for the test set (this split has been chosen in order to preserve the order and completeness of the 30 answers per participant).
For the final results, participants of this shared task will be provided with a MIX_text only and are asked to reproduce the ranking of each student relative to all students in a collection (i.e. within the test set).
The success will be measured with the pearson rank correlation coefficient.
Subtask 2: Classification of the Operant Motive Test (OMT).
Operant motives are unconscious intrinsic desires that can be measured by implicit or operant methods, such as the Operant Motive Test (OMT)(Kuhl and Scheffer, 1999). During the OMT, participants are asked to write freely associated texts to provided questions and images. An exemplary illustration can be found under the Data tab. Psychologists label these textual answers with one of five motives. The identified motives allow psychologists to predict behavior and long-term development.
For this task, we provide the participants with a large dataset of labeled textual data, which emerged from an operant motive test. The training data set contains 80% of all available data (167,200 instances) and the development and test sets contain 10% each (20,900 instances)
UUID OMT_text
6221323283933528M10 Sie wird ausgeschimpft, will jedoch das Gesicht
bewahren.Beleidigt.Weil sie sich schämt, ausgeschimpft zu werden.
Die blaue Person ist verletzt und hört nicht auf die Worte der weißen Person.
UUID motive level
6221323283933528M10 F 5
The success will be measured with the macro-averaged F1-score.
Data
NORDAKADEMIE Aptitude Data Set
Since 2011, the private university of applied sciences NORDAKADEMIE performs an aptitude college application test, where participants state their high school performance, perform an IQ test and a psychometrical test called the Motive Index (MIX). The MIX measures so-called implicit or operant motives by having participants answer questions to those images like the one displayed below such as "who is the main person and what is important for that person?" and "what is that person feeling". Furthermore, those participants answer the question of what motivated them to apply for the NORDAKADEMIE.
The data consists of a unique ID per entry, one ID per participant, of the applicants' major and high school grades as well as IQ scores with one textual expression attached to each entry. high school grades and IQ scores are z-standardized for privacy protection.

In total there are 2,595 participants, who produced 77,850 unique MIX answers. The shortest textual answers consist of 3 words, the longest of 42 and on average there are roughly 15 words per textual answer with a standard deviation of 8 words. The (not z-standardized) average grades and IQ scores are as follows:
- German: 9.4 points
- English: 9.5 points
- math: 10.1 points
- IQ language: 118 points
- IQ logic: 72.6 points
- IQ averaged: 77 points
The IQ language measures the use of language and intuition such as the comprehension of sayings. IQ logic tests the relations of objects and an intuitive understanding of mainly verbalized truth systems. The averaged IQ includes IQ language and logic as well as further IQ tests (i.e. language, logic, calculus, technology and memorization). To enhance data protection, all provided high school grades and IQ scores are z-standardized.
To enhance data protection, all provided high school grades and IQ scores are z-standardized.
student_ID image_no answer_no UUID MIX_text
1034-875791 2 2 1034-875791_2_2 Die Person fühl sich eingebunden in
die Unterhatung.
student_ID german_grade english_grade math_grade lang_iq logic_iq
1034-875791 -0.08651999119820285 0.3747985587188588 0.5115559707967757
-0.010173719700624676 -0.13686707618782515
student_ID rank
1034-875791 15
Operant Motive Test (OMT)
The available data set has been collected and hand-labeled by researchers of the University of Trier. More than 14,600 volunteers participated in answering questions to 15 provided images such as displayed in the figure below.
The pairwise annotator intraclass correlation was r = .85 on the Winter scale (Winter, 1994).
The length of the answers ranges from 4 to 79 words with a mean length of 22 words and a standard deviation of roughly 12 words.
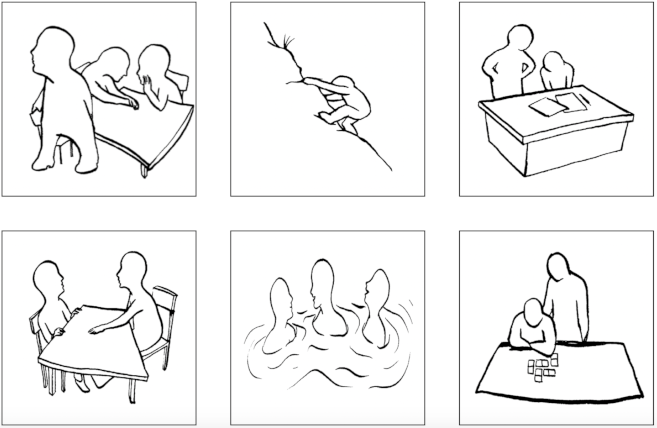
Some example answers to the very first image above are as follows (with A being the so-called affiliation motive and M being the power motive, two out of the five motives besides L for achievement, F for freedom and 0 for the zero / unassigned motive):
A sie nimmt am Gespräch nicht teil und wendet sich ab. gelangweilt. es interessiert sie nicht, worüber die anderen beiden reden. schlecht.
M weicht ängstlich zuruück. unterlegen. wird zurechtgewiesen. Gelegenheit den Fehler zu korrigieren
(Translation: A she does not take part in the conversation and turns away. bored. She does not care what the other two are talking about. Bad. M withdraws anxiously. Inferior. is rebuked. Opportunity to correct the mistake.)
The number of motives in the available data is unbalanced with power (M) being by far the most frequent with 54.5%, achievement (L) constituting 19% of the data, affiliation (A) 17%, freedom (F) 5.6% and zero 5%.
For each instance there is a unique ID, the expressed textually answers with a label for the main motive and a level. The data structure of the whole OMT data set looks as follows and is tab-separated:
UUID OMT_text
6221323283933528M10 Sie wird ausgeschimpft, will jedoch das Gesicht bewahren.Beleidigt.Weil sie sich schämt, ausgeschimpft zu werden. Die blaue Person ist verletzt und hört nicht auf die Worte der weißen Person.
UUID motive level
6221323283933528M10 F 5System Description Paper Author Guidelines
- Please use the LaTeX template provided by the main conference under https://swisstext-and-konvens-2020.org/call-for-papers/
- Language: English
- All submissions must be in PDF format and must conform to the official style guidelines, which are contained in the template files that are available above.
- The decision on paper acceptance will be based on the feedback from the reviewers.
- The review process will be single-blind, i.e. authors are allowed to enter information that might reveal their identity.
- Accepted system description papers will appear in an online workshop proceeding.
- Manuscripts must describe original work that has neither been published before nor is currently under review elsewhere.
- Submission will be made through EasyChair: https://easychair.org/conferences/?conf=gest201
- A draft of the description paper can be found here.
The shared task is organized by Dirk Johannßen, Chris Biemann, Steffen Remus and Timo Baumann from the Language Technology group of the University of Hamburg, as well as David Scheffer from the NORDAKADEMIE Elmshorn. The data was provided by Nicola Baumann from the Universität Trier and Gudula Ritz from the Impart GmbH (Germany).
Workshop Details
Date: Jun 23, 2020
Important Dates
- 01-Dec-2019: Release of trial data
- 01-Jan-2020: Release of training data (train + validation)
- 08-May-2020: Release of test data
- 01-Jun-2020 05-Jun-2020: Final submission of test results
- 03-Jun-2020 09-Jun-2020: Submission of description paper
- 04-11-Jun-2020 14-Jun-2020: Peer reviewing: participants are expected to review other participant's system descriptions
- 12-Jun-2020 15-Jun-2020: Notification of acceptance and reviewer feedback
- 18-Jun-2020 20-Jun-2020: Camera-ready deadline for system description papers
- 23-Jun-2020: Workshop in Zurich, Switzerland at the KONVENS 2020 and SwissText joint conference
Terms and Conditions
The copyright to the provided data belongs to the NORDAKADEMIE and for the OMT related tasks to the University of Trier and Impart GmbH, its licensors, vendors and/or its content providers. The scores and instances serve promotional/public purposes and permission has been granted by the NORDAKADEMIE and the University of Trier, which both share this dataset. This dataset is redistributed under the creative commons license CC BY-NC-SA 4.0.
By participating at this competition, you consent the public release of your anonymized scores at the GermEval-2020 workshop and in respective proceedings, at the task organizers' discretion.
References
- BVerfGE. (1977). BVerfGE. 43, 291 - numerus clausus II. URL http://www.servat.unibe.ch/dfr/bv043291.html [12/08/2019]
- DeYoung, C. G. (2011). Intelligence and personality. In R. J. Sternberg & S. B. Kaufman (Eds.), Cambridge handbooks in psychology. The
- Cambridge handbook of intelligence (p. 711-737). Cambridge University Press. https://doi.org/10.1017/CBO9780511977244.036 [12/08/2019]
- Hall v. Florida. Docket number 12-10882. SCOTUSblog. 27 May 2014. Retrieved 29 May 2014.
- Hell, Benedikt, Sabrina Trapmann und Heinz Schuler (2007). Eine Metaanalyse der Validität von fachspezifischen Studierfähigkeitstests im deutschsprachigen Raum. In: Jahrgang 21 (Heft 3), S. 251-270.
- Johannßen, D., Biemann, C. and Scheffer, D. (2019): Reviving a psychometric measure: Classification and prediction of the Operant Motive Test. Proceedings of CLPsych 2019, Minneapolis, MN, USA.
- Kuhl, Julius and Scheffer, David. 1999. Der operante Multi-Motiv-Test (OMT): Manual [The operant multi-motive-test (OMT): Manual]. Impart, Osnabrück, Germany: University of Osnabrück.
- McClelland, David C. 1988. Human Motivation. Cambridge University Press. Nachtwei, Jens & Schermuly, Carsten. (2009). Acht Mythen über Eignungstests. Harvard Business Manager. 09. 6-10.
- NORDAKADEMIE. (2018). Campus Forum Nr. 66/Juni 2018. P. 8. Assessment Center an der NORDAKADEMIE. [online] https://www.nordakademie.de/sites/default/files/2019-08/CF_66_final.pdf URL. [12/08/2019].
- NORDAKADEMIE b. (2019). Datenschutzbestimmungen. [online] Available at: https://auswahltest.nordakademie.de/datenschutz URL [12/08/2019]
- NORDAKADEMIE. (2019). Digitale Unterstützung für Personaler - Mitarbeitende finden mithilfe von Künstlicher Intelligenz. [online] Available at: https://www.nordakademie.de/news/digitale-unterstuetzung-fuer-personaler-mitarbeitende-finden-mithilfe-von-kuenstlicher [12/08/2019].
- Pennebaker, James W. , Chung, C. K., Frazee, J., Lavergne, G. M., and Beaver, D. I., When small words foretell academic success: The case of college admissions essays, PLOS ONE, vol. 9, no. 12, e115844, 2014, issn: 1932- 6203. doi: 10.1371/journal.pone.0115844. [Online]. Available: http: //journals.plos.org/plosone/article?id=10.1371/journal.pone. 0115844.
- Rushton, J. P., & Jensen, A. R. (2005). Thirty years of research on race differences in cognitive ability. Psychology, Public Policy, and Law, 11(2), 235-294. https://doi.org/10.1037/1076-8971.11.2.235
Sanger, Robert M., IQ, Intelligence Tests, 'Ethnic Adjustments' and Atkins (November 21, 2015). American University Law Review, Vol. 65, No. 1, 2015. Available at SSRN: https://ssrn.com/abstract=2706800 - Scheffer, David. 2004. Implizite Motive: Entwicklung, Struktur und Messung [Implicit Motives: Development, Structure and Measurement]. Hogrefe Verlag, Go ̈ttingen, Germany, 1st edition.
- Schleithoff, Fabian (2015). Noteninflation im deutschen Schulsystem - Macht das Abitur hochschulreif. In: ORDO - Jahrbuch für die Ordnung von Wirtschaft und Gesellschaft. Bd. 66. De Gruyter Oldenbourg, S. 3-26. ISBN: 978-3-8282-0621-2.
- Schultheiss, O. C. (2008). Implicit motives. In O. P. John, R. W. Robins, & L. A. Pervin (Eds.), Handbook of personality: Theory and research (p. 603-633). The Guilford Press.
- Sommer, Kristina. (2012). Erst testen, dann bewerben. [online] Available at: https://idw-online.de/de/news492748 URL [12/08/2019].
- Wikipedia. 2019. Fachhochschule. [online] Available at: https://en.wikipedia.org/wiki/Fachhochschule URL [12/08/2019].
- Winter, David. 1994. Manual for scoring motive imagery in running text. Dept. of Psychology, University of Michigan (unpublished).
- Zimmerhofer, Alexander und Günter Trost (2008). Auswahl- und Feststellungsverfahren in Deutschland - Vergangeheit, Gegenwart und Zukunft. In: Studierendenauswahl und Studienentscheidung. 1., Aufl. Hogrefe Verlag, S. 32-42.
