ACQuA: Argumentation in Comparative Question Answering
Motivation
In modern society, individuals are faced with choice problems on a daily basis. The most prominent example is the choice between analogous products (e.g., what camera to buy), but more generally people aim to choose between all kinds of things: cities to visit, universities to study at, or even programming languages to use. Every informed choice assumes a comparison and objective argumentation to favor one of the candidates, for instance on the basis of important aspects of the candidates. The ubiquity of such comparative information needs is emphasized by the fact that question answering (QA) platforms are packed with questions like “How does X compare to Y?”. Furthermore, the web at large is full of pages about comparing various objects. Uncountable specialized online and offline magazines systematize results of typical comparisons (e.g., for cars, cameras, restaurants, or insurances) prepared by (expensive) human experts. Specific product comparison systems, such as Compare.com or Check24.de, go a step further, allowing comparing any subset of objects in narrow domains such as cameras. Other systems like WolframAlpha.com aim at providing comparative functionality across domains, but also usually suffer from coverage issues, since, similarly to domain-specific systems, they typically rely on structured databases as the only source of information, ignoring textual content from the web. Furthermore, in contrast to human experts and periodicals, existing online tools do not deliver any real choice suggestion when answering a comparative information need, but merely present a table containing common aspects of objects.
Somewhat surprising, no system is currently able to satisfy comparative information needs for the general domain with sufficient coverage and explanations, i.e., no system exists for comparing a broad range of object types, arguing about their relative qualities and providing objective arguments about the best choice. Indeed, information retrieval systems like Google are able to directly answer many factoid questions but do not treat comparative questions especially beyond returning default search results. Advanced question answering systems, such as IBM’s Watson (Ferrucci, 2012), answer factoid questions very well, but cannot handle comparative questions. Finally, as it will be presented below, the research community has also largely overlooked this problem. Therefore, despite the wealth of comparative information available on the web, there is still no adequate technology for its extraction and use. Developing such a technology is precisely the goal of this project.
Crucially, we argue that novel comparative question answering machines can be designed by combining different, yet complementary strains of research. The field of argument mining provides models for the extraction of claims and premises in individual documents. The field of semantic web research has concentrated on collaboratively constructing large-scale open-domain aspect-based representations of objects with applications to factoid QA. The field of sentiment analysis developed robust methods for the extraction of object aspects from text and identification of sentiment polarities with respect to these aspects. Finally, the field of information retrieval (IR) provides robust techniques for web-scale retrieval of documents mentioning objects and their aspects. In this proposal, we show how these different contributions can be combined to build a new kind of open-domain argumentative machine for comparative needs.
To overcome the limitations of state-of-the-art approaches to argument mining and comparative question answering, we propose a research project with the key objective of developing a methodology for an automatic comparative argumentative machine (CAM) for question answering. The core functionality of a CAM is the possibility to order two objects by their qualities, taking contextual information into account and providing a list of arguments supporting the answer. Interaction with the machine is performed in natural language, where some additional visualization (e.g., tables and plots) may complement an answer.
Objectives of the Research Project
In this research project, we will combine natural language processing (NLP), information retrieval (IR), and structured resources to create an open-domain approach to comparative question answering. This combination is promising to overcome the limitations of existing methods: while NLP is needed for recognizing argumentative statements, IR allows exploiting the coverage of web-scale text collections for robust argument extraction. In the proposed system, argumentative structures needed for comparisons will be extracted from both text and structured knowledge bases. These two principally different sources will be integrated for comparative questions. To achieve the vision presented above, our project focuses on the following three objectives:
1. Developing a methodology for human-computer interaction with a comparative argumentative machine using natural language, which will involve understanding questions and presenting and explaining answers.
2. Developing a methodology for joint retrieval and extraction of argumentative structures from web-scale text collections.
3. Developing a methodology for object comparison and generation of arguments on the basis of comparative argumentative structures dynamically extracted from a web-scale text collection and a structured aspect-based lexical resource.
One of the limitations of the available comparative systems is the absence of a natural language interface. Not only are existing systems limited to specific domains, but also they usually present the result of a comparative query by dumping common features of objects in a simple table, providing neither emphasis on features relevant to the query nor delivering any actual answer. In contrast, a comparative argumentative machine should act like a human-expert in the respective field: users ask comparative questions, and the CAM will answer as if it was a conversation between human beings. Such a natural language interface opens a wide perspective to integrate our technology in today’s omnipresent spoken dialogue systems, chatbots, or messengers. Consider the following question to the CAM:
User’s question: “Which programming language should I use for scientific computing: Python or MATLAB? I work in a start-up, where we need to deploy our classifiers as web services. We are a young company and try to cut costs to a minimum.”
The reply of the CAM should consist of an answer and supporting arguments as if a human expert in the domain would provide it:
CAM’s answer: “In your case, I would suggest Python, as it is open-source. While both languages can be used for scientific computing, Python is much better suited for web development as different frameworks, such as Django, are available.”
In addition to the natural language presentation of the answer, users should have access to more details, such as the pros and cons presented in the tabular or graphical form. Our approach will provide these more conventional visualizations (cf. WP6) to support users not confident about an answer’s correctness or users wanting to double-check the underlying reasoning.
Software Prototypes and Demos
- Demo of a comparative argumentative machine (CAM): http://ltdemos.informatik.uni-hamburg.de/cam/
- Demo of TARGER Argument tagging system: http://ltdemos.informatik.uni-hamburg.de/targer/
- Web-scale corpus based on the CommonCrawl: https://www.inf.uni-hamburg.de/en/inst/ab/lt/resources/data/depcc.html
- Keyword search over the DepCC corpus: http://ltdemos.informatik.uni-hamburg.de/cam/search
The figure below illustrates the CAM prototype:
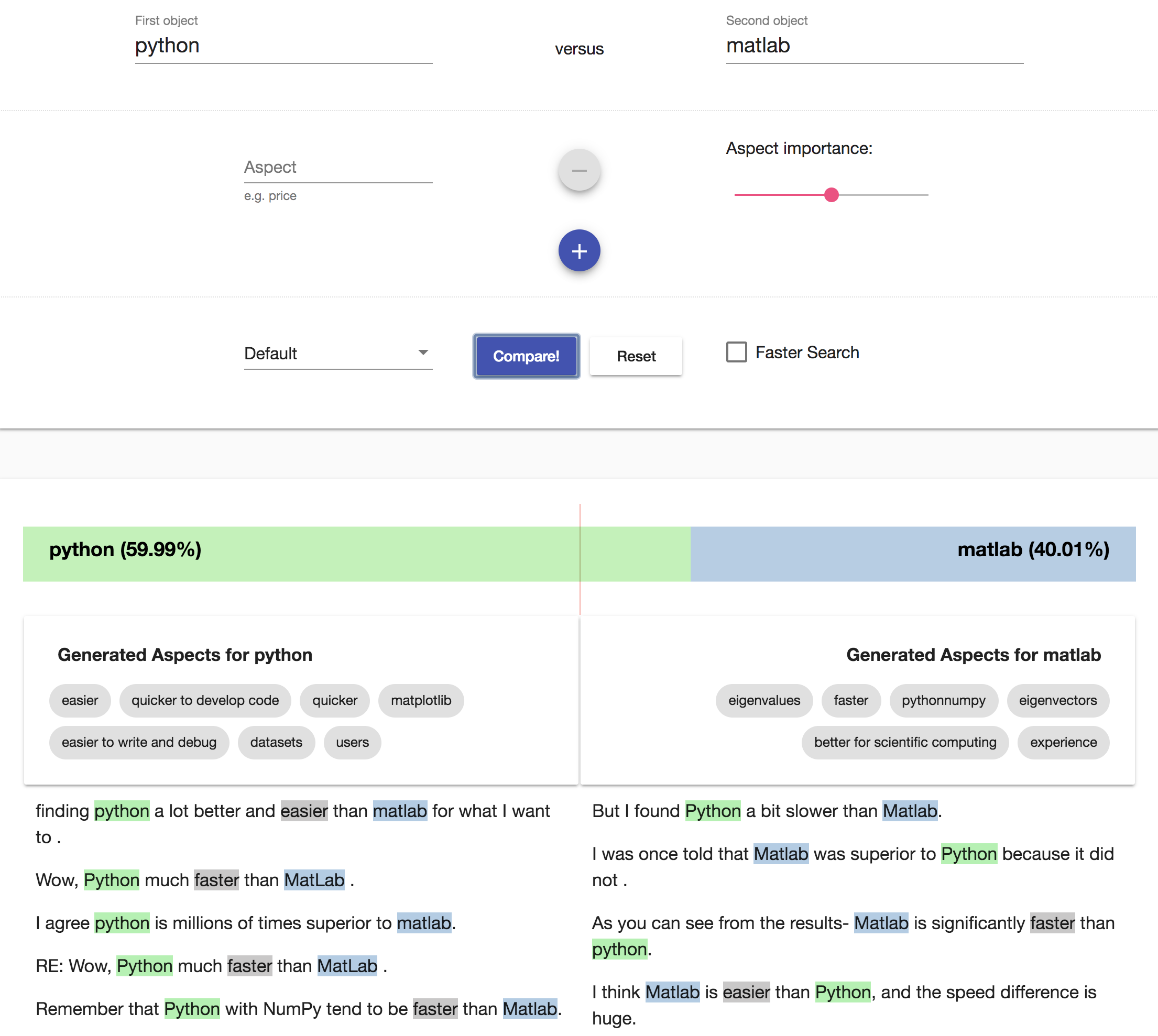
Peer-Reviewed Publications
- Bondarenko, A., Hagen, M., Potthast, M., Wachsmuth, H., Beloucif, M., Biemann, C., Panchenko, A., Stein, B. (2020): Touché: First Shared Task on Argument Retrieval. Proceedings of ECIR 2020 Clef Task papers, Lisbon, Portugal (pdf) (task page)
- Bondarenko, A., Hagen, M., Beloucif, M., Biemann, C., Panchenko, A. (2020): Answering Comparative Questions with Web-based Arguments. Proceedings of AAAI 2020 Workshop on Interactive and Conversational Recommendation Systems, New York, USA (pdf).
- Bondarenko, A., Braslavski, P., Völske, M., Aly, R., Fröbe, M., Panchenko, A., Biemann, C., Stein, B., Hagen, M. (2020): Comparative Web Search Questions. The 13th ACM International WSDM Conference, Houston, Texas, USA (pdf)
- Bondarenko, A., Kasturia, V., Fröbe, M., Völske, M., Stein, B., Hagen, M. Webis at TREC 2019: Decision Track. In Ellen M. Voorhees and Angela Ellis, editors, 28th International Text Retrieval Conference (TREC 2019), NIST Special Publication, November 2019. National Institute of Standards and Technology (NIST).
- Panchenko, A., Bondarenko, A., Franzek, M., Hagen, M., Biemann, C. (2019): Categorizing Comparative Sentences. Proceedings of the 6th Workshop on Argument Mining, Florence, Italy, pp. 36–145, ACL (pdf)
- Chernodub, A., Oliynyk, O., Heidenreich, P., Bondarenko, A., Hagen, M., Biemann, C., Panchenko, A. (2019): TARGER: Neural Argument Mining at Your Fingertips. Proceedings of ACL 2019 (demo papers), Florence, Italy, pp. 195-200, ACL. (pdf) (github) (demo link)
- Schildwächter, M., Bondarenko, A., Zenker, J., Hagen, M., Biemann, C., Panchenko, A. (2019): Answering Comparative Qestions: Better than Ten-Blue-Links? Proceedings of ACM SIGIR Conference on Human Information Interaction and Retrieval (CHIIR), Glasgow, Scotland, UK, pp. 361-365 (pdf) (demo link)
- Bondarenko, A., Völske, M., Panchenko, A., Biemann, C., Stein, B., Hagen, M. (2018): Webis at TREC 2018: Common Core Track. In Ellen M. Voorhees and Angela Ellis, editors, 27th International Text Retrieval Conference (TREC 2018), NIST (pdf)
- Panchenko, A., Ruppert, E., Faralli, S., Ponzetto, S.P., Biemann, C. (2018): Building a Web-Scale Dependency-Parsed Corpus from Common Crawl. Proceedings of LREC 2018, Myazaki, Japan, pp. 1816-1823. ELRA (pdf)
Unpublished/Not Peer-Reviewed
- Hauke Heller: Comparative Query Suggestion. B.Sc. Thesis, Universität Hamburg, 2019
- Matthias Schildwächter: An Open-Domain System for Retrieval and Visualization of Comparative Arguments from Text. M.Sc. thesis, Universität Hamburg, 2018 (pdf)
- Mirco Franzek: Comparative Argument Mining. M.Sc. Thesis, Universität Hamburg, 2018 (pdf)