Projektarchiv
Eine Seite mit Projektdemos gibt es hier.


















Archive
ThumbnailAnnotator, a user-driven, visual and textual, human-in-the-loop word sense disambiguation tool (WS 2018/19)
A very active topic in the natural language processing (NLP) research area is the task of word sense disambiguation (WSD). The main goal of WSD is the disambiguation of multiple, possible meanings of a word in a specific context. For example the word ‘python’ might refer to a snake or the programming language. Depending on the context it is used in, it is usually easy for humans to identify the author’s intended meaning.
For computers, this is a non-trivial task which is still not fully solved. There are many different methods to accomplish WSD but basically they can be divided into supervised or unsupervised learning algorithms, whereby both of them usually require large background corpora and/or sense inventories (Panchenko et al., 2017; Moro et al., 2014; Miller et al., 2013; Navigli, 2009). Creating these sense inventories is a time consuming and hard task. For WordNet (Miller, 1995), for example, extensive and elaborate work of linguistic and psychological specialists was required for manual acquisition, and still, completeness can not be claimed, e.g. new technical terms such as ‘python’ as a programming language, or named entities such as celebrities or organizations, are missing.
The ThumbnailAnnotator application was developed within a master’s project at the Language Technology group at the University of Hamburg. The core idea is to retrieve ’context sensitive’ thumbnails (small images usually used for previewing purposes) for noun compounds and named entities (called CaptionTokens henceforth), which appear in an input text and disambiguate a word by editing the priority of a provided thumbnail image. Hence, the thumbnail image serves as a description of the intended meaning of the word. For example, let’s consider the sentence “My computer has a mouse and a gaming keyboard”. If a user clicks on the word ‘mouse’, a list of thumbnails of animals and/or technical devices shows up. Now a user can increment or decrement the priority of a thumbnail to induce a visual sense for the word ‘mouse’ in this specific context. Also, various information about the CaptionToken is provided, such as a) the universal dependencies (de Marneffe et al., 2006) that form the context of the CaptionToken, b) the individual tokens that a CaptionToken consists of, and c) a synset from WordNet by automatic Lesk-based WSD (Miller, 1995; Banerjee and Pedersen, 2003). At the current state there is a REST API 1 as well as a WebApp 2 to interact with the ThumbnailAnnotator.
Participants
Florian Schneider
VR Prototyping Lab (WS 2018/19)
VR Prototyping Lab (WS 2018/19)
Virtual Reality wird den Zugang zu Inhalten verändern. Doch noch ist offen, welche neuen Businessmodelle sich durchsetzen werden und welche neuen Wege es zur Monetarisierung von Content geben muss, um mit VR zukünftig Geld zu verdienen.
Genau hier möchte nextMedia.Hamburg mit dem VR Prototyping Lab ansetzen und Hamburger Unternehmen eine Innovationsinfrastruktur zur Verfügung stellen.
Als Standortinitiative der Hamburger Medien- und Digitalwirtschaft möchte nextMedia.Hamburg Studierenden der Hamburger Hochschulen die Möglichkeit bieten, in enger Zusammenarbeit mit Unternehmen und dem Verein nextReality.Hamburg mit VR zu experimentieren, Marktideen zu entwickeln und einen Prototypen zu bauen und zu testen.

Im Laufe des Wintersemesters 2018/19 wird im Rahmen des Projekts Know-how ausgetauscht und die notwendige Hardware zur Verfügung gestellt, um in einem Co-Innovationsprozess VR-Projekte umzusetzen. Das Lab wird im brandneuen VR Transfercenter im Kreativspeicher M28 in der Speicherstadt stattfinden und sich in den Themenfeldern Medien, Entertainment, Werbung/Marketing und Games bewegen.
Participants
L. Kruse, V. Eckhardt und F. Meyer
Automatic animal identification on farms for customer transparency (WS 2018/19)

This project develops a system that enables customers to see the animals that were used in the product. A customer in a store scans a tag on the product and sees corresponding pictures of animals and their living conditions. This tool also helps farmers to promote their farms by offering full transparency to the consumer.
In this project, we collect images and videos of animals on a farm. Using object recognition and optical character recognition (OCR) the animals are identified by their ear tags. This data is fed into a mobile web application that allows customers to retrieve photos of the animals by tag number.
Upon successful completion of the project, we plan to automate the process of taking pictures, recognizing animals by tag and storing them. The idea is to install an automated camera system on the farm that uploads the images into the web application for processing, so that data is readily available for the farmer and the customer.
Participants
Thorben Willert
Machine Comprehension Using Commonsense Knowledge (WS 2018/19)
Ambiguity and implicitness are inherent properties of natural language that cause challenges for computational models of language understanding. In everyday communication, people assume a shared common ground which forms a basis for efficiently resolving ambiguities and for inferring implicit information. Thus, recoverable information is often left unmentioned or underspecified. Such information may include encyclopedic and commonsense knowledge. This project focuses on commonsense knowledge about everyday activities, so-called scripts. It is built upon the task defined in SemEval-2018 Task 11. A software application will be written to pick the best answer to questions referring to specified text, with focus on commonsense knowledge.
Particpants
Andy Au (TUHH)
Pun Detection and Location (WS 2018/19)
Pun, a form of wordplay, uses ambiguity of words to achieve an intended humorous or rhetorical effect. This deliberate effect is one kind of communication act, which has a number of real-world applications. For example, it can make conversations very human-like. Also, features like recognizing humorous ambiguity can enhance user experience in automatic translation for non-native speakers. If a computer can find out humor, it can better ”understand” human language.
A pun usually exploit polysemy, homonymy, or honological similarity to another sign. For instance: I used to be a banker but I lost interest. In this case, the word ”interest” shares the different meanings, thus this sentence contains a
pun. The aim of this project is to detect if the context contains a pun, and if so, which word is the pun, i.e. locate the pun
Particpants
Eva Jingyuan Feng (TUHH)
VR Game Jam (WS 2018/19)
The Global Game Jam (GGJ) is the world's largest game jam event (game creation) taking place around the world at physical locations. Think of it as a hackathon focused on game development. It is the growth of an idea that in today’s heavily connected world, we could come together, be creative, share experiences and express ourselves in a multitude of ways using video games – it is very universal. The weekend stirs a global creative buzz in games, while at the same time exploring the process of development, be it programming, iterative design, narrative exploration or artistic expression. It is all condensed into a 48 hour development cycle. The GGJ encourages people with all kinds of backgrounds to participate and contribute to this global spread of game development and creativity.
The Human-Computer Interaction group organizes a jam site in the XR LAB at Informatikum Hamburg especially for all jammers interested in creating Virtual Reality and Augmented Reality games. We offer a collection of VR/MR/AR devices for the jam, e.g., several HTC Vive systems, Oculus Rifts, a HoloLens and a CAVE system. Students of the Department of Informatics are able to earn 3 Credits (3LP) when participating at the jam.
Participants
Results
Implementation and Comparison of Different Reinforcement Learning Approaches for Chess (SoSe 2019)
Chess is a two-player strategy board game played on a checkered gameboard with 64 squares arranged in an 8x8 grid. Due to its popularity there have been many different approaches to implement AI opponents. In this project we focus on applying reinforcement learning. The goal is to implement two different algorithms, which will eventually be able to play against each other. One of them will be deep reinforcement learning while the other will be a simpler approach such as Q-Learning or TD(λ). Both of these will learn by playing against themselves for a certain number of times.
For the implementation we will use OpenAI Gym and python-chess. OpenAI Gym is a toolkit for developing and comparing reinforcement algorithms and will enable us to use it for the training of our own algorithms. python-chess is a python library containing the complete

logic of the game, from setting up the 8x8 board, to making moves and finishing a game. It also enables to print the current state of the board in ASCI format, enabling limited visualization out of the box. We will use python-chess to create an environment for OpenAI Gym.
Participants
Sidney Hartmann, Niklas Winkemann
Mobile CRM Application for B2B Communication enabling Ordering, Messaging and Connecting between Suppliers and Retailers (SoSe 2019)
Introduction
Today, communication between a retailer and his supplier has no standardization regarding the communication channel. In fact, both of those kinds of business partners do use individual forms of communication which leads to the fact that suppliers receive orders and messages through different channels of communication. Communication in such cases is done by e-mailing, calling, or by using messaging apps such as WhatsApp. From a supplier´s perspective receiving orders, complaints and questions through different channels causes higher transaction costs and more errors than receiving a major part of the communication through one channel which is primarily designed for this information management task.
There are several possibilities to efficiently connect two businesses via standardization of communication, by using standards like EDI, or by using a B2B web shop. Nevertheless there is still the issue that not every business implements the same way of communication, either because of the complexity of a specific channel, or because of a long-term practice using one specific communication channel, without evaluating it over time.
Talking to business owners reveals that there is another issue of doing too many things manually in the process of receiving orders. E.g. when one supplier plans to deliver to one customer, it is common practice to manually contact all other customers which are located near that first customer to request them to place orders. There are several other situations in which the supplier manually has to define and then contact customers, to receive a certain reaction from them. This causes the transaction costs to be higher than doing such tasks by automation.
Our solution
This project has the goal to build and distribute a mobile first B2B-Communication application to efficiently design and implement a tool so that suppliers and retailers of different goods can do their business communication through one central channel and automate basic tasks.
The access to the app is supposed to be exclusively limited to businesses with a business registration. After registration and getting access to the account every user is supposed to customize it´s user account by entering data which is relevant for business communication. Within the app every user can connect an in-app shop to its account. This lets everyone in this network potentially see and shop at different suppliers on their mobile phones, as soon as they get the access from the specific shop owner. For a better imagination assume there is a global shop for every user, where all the products from all connected suppliers are shown. In this global shop there is the possibility to filter by user product, etc. As soon as the shop owner enables the access, a user can send orders, which will be sent via pdf or similar to the recipient in the messaging display, who can easily send order confirmations back and export that order in different formats to get it into their ERP-system. Like in other messaging apps one user can write messages to another user. The whole application has the objective to let every user see and easily adjust the visibility of it´s personal information, shop, etc. Every user can easily manage and see all the connected suppliers and the connected retail-customers. To support every user there will be an implementation to automate certain communication tasks such as automatically finding out which customers have to be contacted concerning purchasing orders by entering the transportation route of the suppliers´
vehicle. By implementing such functions in this application the user’s processes will have faster lead times, because of less errors.
Analysis of Comments on Online News Articles (SoSe 2019)
The shift from paper based news sources towards online news hubs allows readers to voice their opinions and interact by using the comment function that is often provided alongside the news articles. In 2017 the German news website Spiegel Online (abbr. SPON) reported that usually around 8000 comments are published in a single day. This increasingly high amount of semantically rich natural language data could, in various ways, be used to enhance interaction between users, or to allow aggregated insight into the topics addressed in the comments. The task of this base.camp project is to collect the news articles and comments from the popular news website SPON and apply recently developed natural language models for the following two tasks:
Automated integration of user comments into news articles
Even though the number of users actively participating in discussions on news articles steadily increases, the comment sections are often clearly separated from the articles themselves. In the case of SPON, comments can be accessed either through forums or below articles, visually separated by links to social media and related articles. Furthermore, comments are sorted chronologically instead of topically. Throughout the actual article there is a topical structure, making it easy to follow along for users. Comments, however, are sorted chronologically, meaning that comments concerning different sections of the article are mixed. This makes it harder for users to keep an overview over which aspects of the article are being discussed. The idea is to enhance the discourse between users by showing the comments alongside the specific section of the article they concern. To achieve this, I want to automatically recognize strong semantic relatedness between comments and sections of the article in the sense of aspect mining The preliminary approach I would like to explore is for the model to learn the relation of comments and article sections from known relations between forum comments, i.e. users answering to other users. My goal is to explore whether or not I can successfully transfer the learned comment-to-comment relationships onto comment-to-article relations. I plan to make the results available as a browser extension, customizing the user experience when using the SPON news page.
Identification and classiffication of meta-comments
A special kind of comment is the meta-comment. This kind of comment does not only address the content of the article, but primarily focuses on how this content is covered, e.g. giving feedback on the journalist, moderators or the news website. Previous work by Häring et al. has already explored this topic, applying both traditional as well as end-to-end machine learning approaches to group meta-comments into three classes. Subsequent manual content analysis has shown that a more fine-grained classification may be useful. My goal is to improve the meta-comment identification performance achieved by Häring et al. and to revise the classification structure. This new classification model will be based on the Bidirectional Encoder Representations from Transformers (abbr. BERT) architecture.
This project was proposed by Marlo Häring from the MAST research group and is actively supported by him and Prof. Dr. Maalej. It is related to the Forum 4.0 research project which aims to analyze, aggregate, and visualize the content and quality of comments in order to enable constructive participation.
Participant
Tim Pietz
MineRL Competition for Sample-Efficient Reinforcement Learning (SoSe 2019)
We are planning to take part in the MineRL competition. The goal of the competition is to foster the development of sample efficient reinforcement learning algorithms while providing a level playing field for all participants regarding available resources. The competition is organized by various universities, sponsored by Microsoft and one of the eight competitions in the NeurIPS Competition track. Participants will devise a general algorithm that will be evaluated in Minecraft, a popular video game. The target for the agent is to mine a diamond as soon as possible which requires various previous crafting and gathering steps. These previous steps or subtasks will also give a reward and are specified by the organizers. The use of any domain specific feature extraction or code is forbidden. For training, a dataset containing more than 60 million state-action pairs is provided by the organizers.
Participants
Anton Wiehe, Florian Schmalzl and Brenda Vasiljevic Souza Mendes
Supervisor
Manfred Eppe
V-connect-U (SS 19)
We developed the app V-connect-U during a hackathon hosted by VSIS. lts concept is the sharing of any kind of good with other users of the app. lnstead of monetary compensation, sharing goods shall invite social interactions between users. At the end of the hackathon, the app was in a presentable state with partially implemented core functionality. In this proposal, we will display the current state of the app and describe the features we would like to develop as part of the base.camp with the goal of finishing all core features and performing a field study to evaluate the usability of the app.

A moderate amount of people carry objects like power banks with them everyday, but rarely come into a situation where they actually need to use them. Sometime a group of friends will have a BBQ in a public park, but they might only use a fraction of their grill's energy before running out of food to grill. We think that it would be great to share these commodities which would be wasted otherwise.
Sharing commodities for free has some advantages over putting a price tag on them: - Removes the hassle of picking a fair price or having to bargain - Provides the good feeling of helping someone eise out - Allows people to easily start a conversation with strangers
Our Sharing App aims to have the following features: - Creating share events (What, Where, When) - Searching for share events through multiple filters (Location, Category, etc.) - Signing in/out of events, either for the full duration of the event or for a set amount of time - Rating host and/or other participants after the event is over.
Target Features
• Registration for new users (currently users have tobe written directly into the database)
• Password functionality for users
• Fill the map-view with actual shares from the database
• Implement filtering logic for existing shares instead of showing all of them at all times
• Create a detail view for shares that can be accessed from list/map view
• Sign in/out of shares through the aforementioned detail view
• New subsection under the share section of the app to show users all of their created shares with editing/deletion functionality
• Rating of host and participants after a share event has been completed
InterUniversal File System (SoSe 2019)
As part of our bachelor project, we have built a prototype of a project called ,,IUFS” which is inspired by the "InterPlanetary File System” (IPFS). Within the scope of the base.camp, we plan to extend the project by further developing an existing prototype of a distributed, peer-to-peer file system that is based on a distributed hash table, in order to provide fast and reliable content delivery for files (e.g. article images) that are too large to be stored in any blockchain. We will especially focus on scalability of the network as well as robustness in terms of data integrity and availability.
The idea of the IUFS came up in the module ,,Projekt Einführung in die Entwicklung verteilter kontextbasierter Anwendungen” while we were developing an application called ,,BlogChain” that runs on the Cadeia blockchain 1 of the VSIS team. The project has features similar to Steemit, however, it does not incorporate a cryptocurrency. During the development of the ,,BlogChain” we learned that it is impractical to store files, e.g. article images, in the blockchain, so we looked for a solution to store files, which are needed in the context of blockchain, persistently. Since we didn’t want to heavily compress the uploaded files and also didn’t want to compel users to trust on possibly non-distributed third-party file hosting services, we decided to prototypically implement our own, distributed file system under the working title ,,InterUniversal File System” (IUFS). When the semester was over, we had written a working prototype of the ,,IUFS” which of course has much potential for improvement. The basic framework of our project is a distributed hash table (DHT) and it is inspired by the ,,InterPlanetary File System” (IPFS).
Participants
Kevin Röbert und Arne Staar
GitLab Project: https://git.informatik.uni-hamburg.de/cadeia/iufs (uni-intern)
Cyber Range (WS 2018/19)
Intrusion Detection Systems (IDS) and Intrusion Prevention systems (IPS) are supposed to prevent sophisticated attacks against the network and environment they are deployed in. For this purpose, they are getting more and more ”‘smart”’ and have built-in Machine learning. But with more automatically learning it gets harder to verify if the system detects advanced and unknown attacks.
Platforms used for teaching and even more in online Attack/Defense competitions (for example international CTFs) lots of attacks are carried out and/or tried. In a CTF scenario, the teams do not know how to proceed initially. Potentially this leads to lots of data about previously unknown vulnerabilities or combinations of them used to illegally export data.
If we combine both aspects it should be possible to use a CTF or training scenario to test IDS and IPS in an almost real scenario. With IPS systems it is even possible to integrate the IPS into the scenario to be exploited. If a good monitoring and ground truth captioning system are integrated into the platform, it is possible to analyze why the IDS/IPS did not trigger on the attack, and maybe also to replay the whole attack to test adjusted rules and training. Testing and evaluation of different IDS/IPS systems can be done on this platform.
In the project and an accomodating MA thesis, the platform should be developed using existing open-source software as far as possible. Then some exemplary scenarios should be implemented and tested. In the end, an evaluation with real IDS/IPS systems should take place, maybe with bigger competition testing all aspects of this work.
Design Goals
Easy start
The platform as a whole should enable users to start easily and participate in cybersecurity challenges. A web interface should be used to chose and start a predefined scenario as well as display a description what to do, give feedback and possibly offer some help.
Intuitive User Interface
It should be simple for the users to access the resources from the scenarios. the easiest way would be via some web based shell emulation or Remote desktop like access via the Web browser. For more advanced users and/or Scenarios a VPN access can be used.
Sharing
It should be possible to export and import scenarios. This would allow to share a scenario with different instances of the platform and maybe build a marketplace for challenges. It should also be possible to take one scenario as a base and extend it by, for example, adding some resources.
Extensibility
Defining new scenarios should be aided by a library of existing components like OS images, applications, and monitoring software. It should also be possible to add additional IDS/IPS systems to existing scenarios to test the response in an already specified environment or even attach them to a replay. An other direction of extensiblity would be adding support for different architectures and processors. With it it would be possible to simulate arm based IoT devices or smartphones. It would add possibilities too if simulated or real industry components like SCADA or Modbus systems can be integrated.
Complete Visibility
The monitoring of the platform should capture all events necessary to start a replay of all actions, so a retest for the tested IDS/IPS is possible. It should also provide data to the instructor how the teams are doing and if possible determine how far each team is in the progress of the scenario. Also, a dashboard showing the progress should be available for the instructor and/or the user.
Multiple Teams
It should be possible to use the platform as a team. Optionally the possible to do Red/Blue Team scenarios on the platform, e.g. one team attacking and one defending the infrastructure can be built. For some scenarios to work, some dummy use of the systems is needed. For example, users logged in on a windows machine to get the auth hashes of the logged in users for lateral movement in the network. This can be provided by the instructors manually, as a Green Team or via recorded actions and network dumps.
For bigger CTF style competitions it would be possible to have each team attack a separate instance of the scenario and only share a scoreboard. But it could also be interesting if each team is the defending (Blue) Team in one instance and attacking all other teams. This scenario is also known as Attack and Defense CTF.
Networking
Each scenario involving more than one host has to have a separated, own virtual network. It has to be possible to have scenarios with more than one network to simulate multi-network setups like a DMZ or a separate office and production network. This would allow having scenarios where hopping from one network to another is necessary.
Scalability
As the platform should be usable with multiple teams at once doing complex scenarios it is necessary that the platform could be scaled to more than a single server per component, especially to execute the target networks on different VM hosts. This would make it possible to add more executing servers quite simple. If the networks of different teams should be joined to attack each other a private network spanning the executing hosts is necessary.
Security
As it is the purpose of the platform to have components of it hacked and exploited it is necessary to ensure that the attackers are confined into the targets and can’t gain unprivileged access to the platform itself. Also the different users have to be shielded from each other so no user can harm other users of the platform.
Participants
Nils Rokita
VR Prototyping Lab (WS 2019/20)
Virtual Reality wird den Zugang zu Inhalten verändern. Doch noch ist offen, welche neuen Businessmodelle sich durchsetzen werden und welche neuen Wege es zur Monetarisierung von Content geben muss, um mit VR zukünftig Geld zu verdienen.
Genau hier möchte nextMedia.Hamburg mit dem VR Prototyping Lab ansetzen und Hamburger Unternehmen eine Innovationsinfrastruktur zur Verfügung stellen.
Als Standortinitiative der Hamburger Medien- und Digitalwirtschaft möchte nextMedia.Hamburg Studierenden der Hamburger Hochschulen die Möglichkeit bieten, in enger Zusammenarbeit mit Unternehmen und dem Verein nextReality.Hamburg mit VR zu experimentieren, Marktideen zu entwickeln und einen Prototypen zu bauen und zu testen. Die beteiligten Unternehmen sind in diesem Jahr SPIEGEL MEDIA, die Bauer Media Group und N-JOY.

Im Laufe des Wintersemesters 2019/20 wird im Rahmen des Projekts Know-how ausgetauscht und die notwendige Hardware zur Verfügung gestellt, um in einem Co-Innovationsprozess VR-Projekte umzusetzen. Das Lab wird im brandneuen VR Transfercenter im Kreativspeicher M28 in der Speicherstadt stattfinden und sich in den Themenfeldern Medien, Entertainment, Werbung/Marketing und Games bewegen.
Participants
Eric Bergter, Tim Fischer, Brigitte Kwasny, Hoa Josef Nguyen, Finn Rietz, Sophia Zell
Curious Hierarchical Actor-Critic Reinforcement Learning (WS 19/20)
Inspired by the human event cognition, this project expounds the use of model-based approaches to solve tasks in a more efficient manner. With a combination of continuous optimization of upcoming future events and pondering about the past, an agent can flexibly plan regarding the task and context given. Ongoing optimization of the internal state leads to potentially better event encodings, resulting in improved goal-oriented actions. To handle and predict sequences of events, recurrent neural networks in various shapes represent possible solutions. Besides, techniques like experience replay and model-predictive control could be used to build an architecture capable of adapting its internal reasoning for the given task. For the evaluation, the physics simulation MuJoCo and a goal-based Robotics simulation are used to apply the concept to different environments. This project extends the Hindsight Experience Replay technique by a forward-model, to show improvements in learning performance in comparison to a purely model-free approach.
Participants
Frank Röder
Supervisor
Manfred Eppe
Results
Präsentation
LAMP – Learning Analysis and Management Project (WS 19/20)
The constant improvements of quality management in university teaching have been a focus topic in recent years and its importance has increased accordingly which has also been the case for the department of informatics at the University of Hamburg. In this context, formative-adaptive tests based on the open source platform OpenOLAT were introduced in selected modules, which are intended to deepen and interactively review the individual preparation and follow-up of the lecture content. Despite the potential of data analysis and the adaptation of the lecture contents and exercises based on the student results, the analysis options of these software solutions have so far been very limited and have had a low informative value.

The LAMP base.camp project is intended to develop a software solution that provides advanced management and analysis options of these tests, which enable lecturers to gain specific insights into the learning progress of the students and to develop learning profiles based on that, which characterize those achievements. The solution aims to provide an option of compiling those tests and creating process mining based analyses that characterize the difficulty of individual questions and thus creating an expandable platform that significantly increases the teaching quality through data-driven statements that can be derived from those analyses.
Participants
Julien Scholz, Pascal Wiesenganger
Presentation
#EUvsVirus Hackathon (SS 20)
Am Wochenende vom 24. - 26.04. 2020 fand der #EUvsVirus Hackathon (https://euvsvirus.org/) statt, bei dem 40 Studierende des Fachbereichs Informatik im Rahmen eines base.camp Projektes teilnahmen.
Bei dem von der EU Kommission organisierten Hackathon ging es darum, innovative Lösungen für Bereiche zu finden, die von Corona beeinflusst werden. Insgesamt nahmen mehr als 20.900 Teilnehmer aus ganz Europa an der Challenge teil. Am Ende wurden 2150 Lösungsvorschläge eingereicht. Themenbereiche waren unter anderem Gesundheit + Leben, Wirtschaft, Remote Working, Lehre und Digital Finance.

Da wir als base.camp solche „bottom-up-Ansätze“ unterstützen wollen, haben wir uns dafür entschieden, den Studierenden die Teilnahme an dem Hackathon als base.camp Projekt im freien Wahlbereich anzurechnen. 40 Studierende nahmen die Chance wahr und beteiligten sich an dem Hackathon.
Das base.camp bedankt sich bei den Teilnehmern und hat sich sehr über die große Anzahl an Studierenden gefreut. Wir hoffen, dass möglichst viele Projekte im Rahmen des base.camp fortgeführt werden!
drasyl (SS 20)
Existing overlay networks almost always come as highly specialized, contextrelated bulk frameworks. This means that they handle nearly all aspects from communication,consistency checks, (un-)marshalling of application-specific entities up to particular method calling models for Remote Method Invocation (RMI) support. Often this happens by a forced specification of a programming paradigm/model, such as the actor or agent model.

Besides, there are typical usage constraints such as the need for a network interface (which requires root privileges for installation) or additional overhead from multi-layer models that mimic IP or VLAN. These frameworks may be an optimal solution for some use cases, but also means limitations and overhead for projects based on a different model and do not need the additional features. All these approaches have in common that they have to solve the problem of communication between nodes in an optimal way. It is precisely this problem and the gap between raw IP-based communication and context-related frameworks that drasyl aims to close by offering a minimal, expandable and transparent transport layer.
Participant: Kevin Röbert
Analysing and classifying toxic speech in online forum (SS 20)
Manual moderation of comments in online forums without the assistance of any tools can be time consuming. One of the use cases of our deep learning model trained in this project could be to aid in the moderators' decision making process of determining if a comment complies with or violates the rules. Comments gathered through crawling will be used to finetune the model for this specific task. In the end the model will give suggestions to whether or not a comment should be removed or approved while providing a reason with confidence level. This model will be based on approaches of distilling the knowledge of larger, heavier models such as BERTLARGE (Delvin et al., 2019) into smaller, faster models to achieve near real time classification of comments while retaining a high accuracy.
Based on the Forum 4.0 project, the deep learning model trained in this project is going to assist moderators of online forums in real time to ease their decision of approving or removing a user comment. The goal of this project is to use the model to classify clear-cut comments that violate the rules. As for comments that are borderline acceptable, the aim is to have the moderator decide. With this human-in-the-loop approach we strive to quickly deal with clear cut cases and focus on the hard cases. The deep learning model could also be used in other cases. For example labeling comments as part of a study to see how many people are coronavirus sceptics. In the case of Spiegel Online, they receive roughly 300,000 comments in a month. With that amount of comments we average a comment every 8.6 seconds. This leaves little time for the model to classify the comment in real time. Even in this example a state-of-the-art model won't be able to keep up with the speed the comments are being made. In this project we explore different implementations and uses of the state-of-the-art natural language processing model BERT (Delvin et al., 2019). This model trains itself by looking at the given text sequence from both left-to-right and right-to-left thus achieving a better understanding of language context compared to previous models that only worked in one direction. Our goal here is to find a distilled model of BERT so that we get an inference time on the CPU low enough for near real time classification while still retaining a high accuracy.
Participant: Kevin Friedrich
EHIC2IoT (SS 20)
When doctors and laboratories are communicating about probes, e.g. those taken from corpses, the documentation of test results is currently handled by hand-written notes and pages which have to be physically transmitted to each party or have to be typed in a software manually. EHIC2IoT wants to help doctors, laboratories and medical staff to deal with probes more efficiently so that measurement can be applied faster.

The basic idea for this project one may find here: https://devpost.com/software/ehic2qr. During the EUvsVirus Hackathon in 2020 students of the university of Hamburg came together to build an app for the laboratories especially in Hamburg who are dealing with the probes taken from suspected Coronavirus infected people. The idea is to extend and adjust the EHIC2QR App so that it has not only one use case of helping the medical procedure when dealing with a Coronavirus case, but rather helping the general procedure of medical staff communicating with laboratories. To get the time and effort in this communication task reduced is a very crucial challenge as it is the key factor of how fast infectious diseases can spread. Just imagine, today an infected person possibly could be told one week after testing if he/she was tested positive or negative. This is unacceptable and that is why Dr. Armin Hoffmann from the UKE, Hamburg and J. Harder and J. Khattar want to build this app.
Participants: Jan Harder, Johnvir Khattar
Towards a Decentralized Trust-Based Reputation System for Citizen-Driven Marketplaces (SoSe 2020)
As part of the master project “Projekt Smart Cities” InfM-Proj-VS work started on implementing a marketplace to share self-generated data. This proposal describes why further effort is necessary for the functionality of the project in the context of the base.camp. In the modern world where every residence is getting smarter and producing more data the need for sharing data is rising. This data can be produced by e.g. selfbuilt weather stations, smartwatches, or other “smart” devices. Currently the data is only locally available for individuals who produced it. The topic of the project was to develop a platform for sharing this self-generated data independent from the type that is produced.
Participant: Fin Töter
Prototype Development and Integration of a Modular Tactile Sensor Array for Robotic Grippers (WS 20/21)

The project presented in this project aims to develop and integrate a prototype of a modular tactile sensor array for robotic grippers. While many grippers are able to control the force with which they grip an object, they are incapable of making assumptions about the texture or shape of the object. The work planned for this project is supposed to pave the way for experiments involving tactile measurements inside the gripper and for further evaluations of tactile sensor arrays. It is features novelties such as wireless data transmission, a modular design and is easy to recreate.
Participant: Niklas Fiedler
YOEO - You Only Encode Once (WS 20/21)

Fast and accurate visual perception utilizing the limited robot’s hardware is necessary to compete in the RoboCup Humanoid Soccer League domain. Such a computer vision architecture needs to adapt to various and dynamic scenarios. We are planning to develop a novel architecture, YOEO, a hybrid CNN unifying previous object detection and semantic segmentation approaches using one shared encoder backbone with model optimizations for the deployment on edge devices in mind. We also address solutions regarding incomplete and insufficient labeling data. This is required because of the unification of the two previously separate handled and trained approaches.
Participants: J. Gutsche, F. Vahl
Object-Oriented Value Function Approximators (WS 21/22)
Standard universal value functions are used in most actor-critic algorithms. Although these algo- rithms achieved high success, they still lack a property that would allow the agent to distinguish the object to manipulate and potentially further improve the training performance. This exten- sion on universal value function introduces a new type of UVFs so-called object-oriented UVFs. OO-UVFs use object-oriented properties to represent the environment’s goals and subgoals in the case of hierarchical reinforcement learning. The object-oriented representations should allow not only to tell the agent which goal to achieve but also determine to which object in the environ- ment this goal refers. That would be achieved by simplification of the goal space that comes with object determination. As an example, we could imagine the block-stacking task, where there are two blocks in the area and the agent must stack one block on another block. In object-oriented terms, we could describe this task as a sequence of two goals (1. set the object on someplace, 2. stack the object on the object from step 1) and two objects so that the first goal applies to one object and the second goal on another object. This study addresses the potential benefits of object-oriented universal value functions and intrinsically suggests experiment conduction and training performance comparison between object-oriented approach and standard algorithms.
Participants: E. Alimirzayev
Trash King (SS 21)

Photo: Hans Braxmeier | Pixabay
During a Hackathon we built an application called “Trash King”. It is an app designed to help clean the city of Hamburg. It should motivate citizens to report and collect trash in public environments. We integrated the public API of the Melde-Michel, a service from the city of Hamburg used to report polluted spots around the city. From this we display trash that is already reported but also provide the ability to report other trash. Additionally there are trash areas, that we believe to get polluted frequently. Those areas can be cleaned periodically by users. To give some kind of reward we assigned points to each trash point and area and implemented a highscore as gamification aspect.
Using gamification to gain users’ participation comes with challenges we were not yet able to address. While awarding users points for reporting and cleaning trash will motivate them to contribute it is rather easy to cheat for selfish users the way this is currently implemented. Therefore we plan on building a trust based system. Users will check other participants’ inputs and can gain trust by continuously being truthful. For this we will integrate the Peertrust metric as introduced in the paper “Peertrust: Supporting reputation- based trust for peer-to-peer electronic communities”. Peertrust defines a general trust metric for each user. This metric consists of two parts: a weighted average of trust based on all previous interactions of a user u with all other users of the system and an additional trust change based on community-specific interactions.
Participants: F. Stiefel, L. van der Veen
Superpixel-Klassifikation mit Graph Neural Networks (WS 21/22)
![]()
The goal of this project is to build a new superpixel classifier for the superpixel-based object proposal refinement system that was developed by Wilms and Frintrop.
The task of object proposal generation or object discovery is a fundamental step of many state-of-the-art object detection systems because it enables them to focus their attention on the image regions that are most likely to contain objects. One way to propose objects is as a pixel-precise segmentation mask that shows the object’s location on the input image and, ideally, perfectly adheres to the object boundaries. However, the latter is not easy to achieve since the segmentation masks are, in most cases, generated from highly downscaled versions of the input and therefore do not contain detailed information about object boundaries.
Participants: R. Johanson
Folding a set of scenarios specified by causal nets to a system net (SS 23)
This project focuses on the folding of a set of scenarios into one Petri net model. We assume the scenarios to be defined as causal nets, specifying one concrete run of a system.
In particular, we will look at ideas from structured occurrence nets and scenario nets to accomplish a compact folded model. This will lead to a prototype for Renew which is a tool to create and simulate various kinds of Petri net formalism.
Participants: Leon Zander
Mining Code Reviews and Using Pre-trained Models for Code Suggestions Automation (SS 23)
This project aims to understand code suggestions and feedback of developers reviewing pull requests on GitHub and to propose a machine learning-based solution for automating code suggestions for these pull requests. To this end, a representative data set of open-source software repositories hosted on GitHub will be created.

The mined data, which consist of the pull requests and their corresponding comments and code suggestions, will be pre-processed, and analyzed using an empirical methodology. In the next step, the gathered data will be used to train a Transformer- based machine learning model to automatically recommend code suggestions.
Participants: Aref El-Maarawi Tefur
Die Letzte Generation: A Study of Events and Reactions Around the Glueing Protests (SS 23)
Hamburg is a vibrant city with many events taking place throughout the year. To gain insights into these events, it is essential to observe and visualize them in a comprehensive manner. The proposed system aims to develop an automated application that can detect events related to the letzte- generation activist groups in Hamburg and extract relevant information such as the date and time of the event, location of the event, type of event, and description of the event.

This information then later can be used by different stakeholders to analyse the event history, correlate new laws with the intensity and frequency of their events, and so on. The system will use NLP techniques such as keyword matching, NER, and machine learning algorithms to identify events and extract relevant information from different sources such as social media and news outlets. The extracted information will be visualized using different techniques such as heat maps, graphs, and maps to provide a better understanding of the events related to the letzte-generation activist groups in Hamburg. The proposed system will provide a valuable tool for tracking events related to the letzte-generation activist groups in Hamburg and understanding their impact.
Participants: Shaista Shabbir
Laudan: Dynamic Kill Chain State Machine (WS 23/24)
Kill Chain State Machines is a concept of correlating sparse alerts in a noisy environment. This project addresses the limitations of Kill Chain State Machines (KCSM) in dynamic cyber threat detection. The immutability of the underlying data structure creates bottlenecks, hindering real-time alerting and adaptive data modification. The proposed solution introduces two approaches: incremental changes and a query-based system. Emphasizing the latter, the project focuses on efficient database design using tools like Tenzir, Elastic, and Graph Databases. By prioritizing dynamic data retrieval, the project aims to enhance KCSM’s scalability and applicability.
Participants: Jona Laudan
A Proposal-Based, Decentralized Demand-Side Management Peak-Reduction Algorithm (SS 23)
Electricity grids have to employ expensive infrastructure to remain stable at peak consumption times. The peak usage is only required for a short time each day.

Currently most devices achieve tasks by running immediately. More intelligent scheduling using demand-side management enables a more effective usage of the grid. But few algorithms look at the problem with the context of the devices being in a network. We plan to implement a demand-side management optimization algorithm which locally decides on a limited number of suggestions based on input suggestions received from other devices in a network. We will compare different scenarios and test against randomized and eager baseline strategies. The project will conclude with a final presentation and a scientific paper.
Participants: Tom Schmolzi
Bundestagsanalysen (WS 23/24)
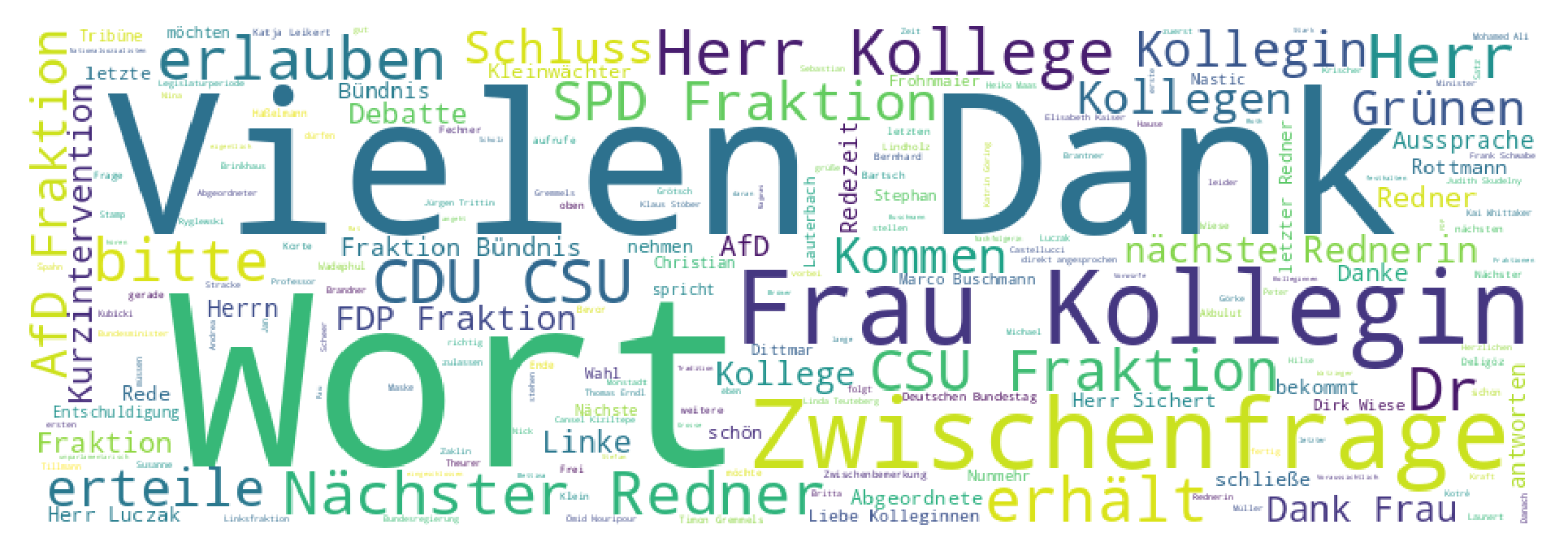
Um lange Bundestagsdebatten schnell erfassbar zu machen, soll für jede Sitzung automatisiert eine Wordcloud erstellt werden. Diese kann dann von einem Twitterbot als Zusammenfassung gepostet werden. Außerdem soll auf einer Website für jeden Abgeordneten eine Wordcloud aus allen Reden erstellt werden. Ziel ist es, eine weitere Möglichkeit der Zusammenfassung des Bundestagsgeschehens anzubieten.
Participants: Anton Trappe
Laundry Sorting Robot (SS 23)
Hoping robotics will assist people in the future with house chores, I will look at doing laundry. One aspect is sorting clothes either by color or kind. The task can be split into the following parts: First finding the clothes, second picking them up, third deciding on what kind of clothing it is and last putting it into the right basket. To fulfill these steps, a robot needs to interact autonomously with non-rigid objects in a known environment.

Robots can do unfavorable tasks for humans. When doing laundry, it usually needs to be sorted by color, material, and type. A robot that can sort laundry is a necessary step for having an autonomous setup that does the complete laundry chore.
The project in itself can be broken down into several parts. Each can be well defined on its own: Grasping clothes from a heap or basket, moving it in front of a camera, applying a classifier, and finally placing it in a predefined place accordingly. It is a good introduction to working with a robot and corresponding software.
During the project a Universal Robotics UR-5 or an Agile Robotics Diana 7 is used as hardware with ROS and MoveIT to move the robot. To process image date OpenCV is used as well as Open3D for the depth information.
Participants: Valerie Bartel
Automatic Detection and Analysis of Wind Turbine Sites with AI and Satellite Data (WS 23)
The development of onshore wind energy plays a crucial role in the global effort to achieve a sustainable energy transition. This project requires precise planning, especially for the construction of new wind farms and the optimisation of existing ones. In Germany, operators are legally obliged to register their wind turbines in the Market Master Data Register (MaStR). Unfortunately, this register suffers from significant shortcomings in terms of the accuracy of the site data, which makes the planning of new turbines and repowering measures difficult.

This project aims to improve the database by using existing satellite imagery and databases. Using artificial intelligence, the data will be corrected and optimised to create a more accurate information base. While the success of these optimisations is not guaranteed, they have the potential to speed up the planning of new wind farms and identify potential sites and repowering measures. This could potentially enable operators and planners to make more informed decisions, contributing to the development of a forward-looking and environmentally friendly energy infrastructure.
Participants: Justus Middendorf
Retrofitting Fridges with IoT Devices - Enabling Smart Capabilities with Sensors and AI (WS 22/23)
The goal of this work is to evaluate different methods for detecting the fill level of a beverage refrigerator. In addition, the system to be designed should be able to track which person has taken how many drinks.
To do this, it must first be possible to measure the fill level of the refrigerator. The sensors must be accurate enough to measure the level down to a single bottle. It should also be possible to detect whether a person has just placed something else in the refrigerator (for example, an empty bottle or a brick) in order to bypass the system.

In addition, the refrigerator must be lockable so that it can be tracked which person is removing drinks. This locking mechanism should be secure (barrier to tampering sufficiently high), simple and, if possible, not obstruct the view of the drinks. For this purpose, a system must be designed that opens the refrigerator after authentication by a person.
In order for this solution to be used as easily as possible, the design must not be too complicated and not too expensive. In addition, the maintenance effort of the system should be as low as possible.
Participants: Jakob Fischer, Markus Behrens
Providing accessibility to analyzing eLearning course data for lecturers (WS 22/23)
Many universities use e-learning platforms like Moodle and Olat. At the University of Hamburg, in the department of informatics, the platforms are frequently used to accompany the lessons with tests. These tests make correcting easy, as the platform allows automatic checking of the answers by matching them with a stored solution (OpenOlat, Benutzerhandbuch, Tests). This speeds up marking tests, but the lecturer has difficulties seeing the reasons for the student's performance. While, for example, Olat provides some form of test statistics (OpenOlat, eTesting), these statistics are on a rudimentary level and do not provide detailed analytic possibilities. To enable enhancing their course, lecturers should have the possibility to create their personal analytics and explore the available data in depth.
To optimize their courses better, it should be easy for lecturers to analyze their course data. The given statistics by the platforms are not enough to understand the course to adapt the following courses or units. For this, the complete course must be analyzed and not the result of individual students. Multiple tools to analyze the data exist but configuring these to work together as a complete system is tedious, time-consuming, and requires knowledge of all the tools used. Lecturers do not have the time and often do not have the knowledge to set up such a system.

This is accompanied by the fact that most of the available data is not in an easily analyzable format and can be spread apart across multiple files or databases. As each course and lecturer have different requirements, creating new metrics has to be possible without deep knowledge of the tools and the data structures.
Participants: Matthias Feldmann