JOIN-T: Joining Ontologies and Semantics Induced from Text
(Please click here for newest updates)
JOIN-T: Joining Ontologies and Semantics Induced from Text
In the information society, the ability to understand the meaning encoded within documents is of utmost importance for enabling the next generation of information technologies. Crucially, this includes key applications such as text search – e.g., the one provided by Web search engines – as well as plagiarism detection – i.e., systems that can automatically detect instances of (typically, illegal) reuse of text within a collection of document. These, in turn, have the potential to impact a variety of strategic areas such as E-learning and E- science platforms.
Current state-of-the-art techniques for these high-end intelligent tasks, however, rely at their core on rather shallow text understanding techniques. This is arguably because deep text understand- ing relies at its very heart on very large amounts of machine readable knowledge (Schubert, 2006, Poon & Domingos, 2010), a requirement which is very hard to satisfy even for current state-of-the-art knowledge bases. Web-scale open information extraction systems like NELL (Carlson et al., 2010) or ReVerb (Fader et al., 2011), albeit successful in acquiring massive amounts of machine-readable knowledge, do not provide a clean, fully semantified output, which, on the other hand, could be provided by the vocabulary of large-scale ontologies like YAGO (Suchanek et al., 2007) or DBpedia (Auer et al., 2007).
These resources, however, have also major limitations in that they focus essentially on relational knowledge between entities, as opposed to covering factual information, episodic events and actions, and their prototypical descriptions (i.e., semantic frames) that are typically encoded within documents. Accordingly, with this project, we present a research program aimed at addressing the limitations of existing state-of-the-art knowledge repositories and providing a methodology to create a new kind of knowledge base that combines the best of both worlds, namely symbolic, explicit semantic (e.g., ontological) information with statistical, distributional semantic representations of concepts, entities, and their relations.
Our vision, ultimately, is to effectively ground these large amounts of machine-readable knowledge within open-domain text representations, in order to enable truly semantic, high-end intelligent applications. With this project, we tackle the preliminary, yet fundamental step of producing a knowledge base which is suitable for this long-term goal: our resource and the methodology to create it, which constitute the main outcomes of the project, have the potential to open up radically new models of document content, as well as bridge the gap between core semantic techniques and their application as key components of complex, high-end intelligent systems.
The state of the art in knowledge acquisition and representation show that these issues are not adequately handled up to now. Crucially, we argue that novel, better knowledge repositories can be acquired by combining different, yet complementary strains of re- search. The field of Natural Language Processing (NLP), in fact, has moved steadily in recent years towards robust and wide-coverage statistical models of natural language meaning. Research on Information Extraction (IE), in the meanwhile, has focused on the task of automatically acquiring very large amounts of ma- chine-readable knowledge from the Web with as little human supervision as possible. Finally, the field of Semantic Web has concentrated on ways to represent and process complex knowledge models, as well as best practices for managing structured data in a way that they can be shared on the the Web, i.e., Linked Open Data (LOD). In this project, the goal is to show how these different contributions can be all leveraged together, in order to bridge the gap between heterogeneous, yet complementary sources of semantic information and knowledge.
To overcome the limitations of state-of-the-art approaches to knowledge harvesting and representation, we propose a research project focused around the key objective of developing a methodology to automatically create a novel kind of knowledge repository, which combines a formal ontological backbone with large amounts of statistical distributional semantic information. Arguably, knowledge- based and distributional semantic methods are two complementary approaches: thus, their combination is expected to bring together the best of both worlds and produce better knowledge sources. The project focuses on three main objectives:
- Creating a new repository of machine-readable knowledge, combining (a) the clean structure and explicit semantics of ontologies with (b) the coverage of semantic distributional methods.
- Exploiting the combination of ontological knowledge and distributional semantic information from our resource, in order to enable large-scale, open-domain semantification of documents, thus advancing the state-of-the-art in text semantification.
- Extending the depth of information stored within a wide-coverage knowledge repository by expanding the standard entity- and property-centric models with frame information – i.e., generalizations of actions and events taking place between entities.
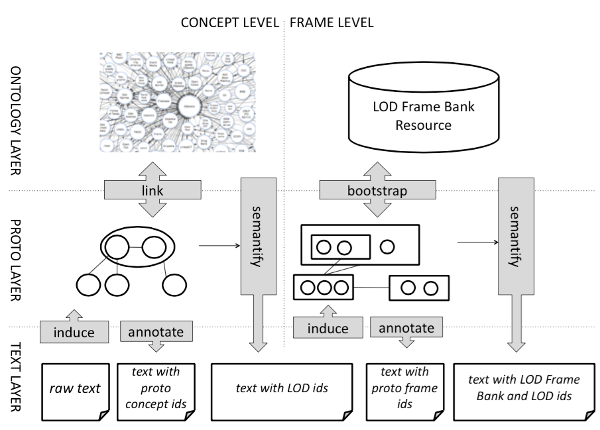
The following figure illustrates overall architecture of the project. In the first phase, we start with large amounts of raw text and develop fully unsupervised methods for the automatic induction of proto-concepts, and their inclusion in a hierarchically organized proto-ontology. In the next step we aim at developing a battery of approaches – ranging from simple baselines to more complex global optimization methods – to link the proto-concepts to a reference knowledge base (e.g., any of DBpedia, YAGO or Freebase). As a result of this, we obtain a so-called hybrid aligned resource, made up of a core, ontological content and structure, which is complemented with wide-coverage distribu- tional semantic representations. Next, we project this back to text corpora and use our extended ontology to annotate documents with their concept representations, namely any of the proto-concept and ontology URIs. We further use these semantically annotated sentences to automatically harvest predicate-argument structures from text, and generalize them into proto-frames, namely distributionally-induced conceptualiza- tions of actions and events. This serves as a basis to semi-automatically bootstrap a frame- augmented ontology that formally encodes this information. This is used as reference knowledge base to annotate text data, thus providing a framebank consisting of a gold-standard, manually-labeled database of texts with conceptualizations of entities and frames. In the last step, we use this very same framebank to produce a frame parser and automatically annotate large amounts of text with deep semantic, ontology- based frame information.
People
Chris Biemann: PI, TU Darmstadt
Simone Paolo Ponzetto: PI, University of Mannheim
Alexander Panchenko: postdoctoral researcher, TU Darmstadt
Stefano Faralli: postdoctoral researcher, University of Mannheim
References
- Auer, S.; Bizer, C.; Lehmann, J.; Kobilarov, G.; Cyganiak, R.; Ives, Z. (2011): DBpedia: A Nucleus for a Web of Open Data. In Proc. of ISWC 2007 + ASWC 2007, pages 722-735 Busan, Korea
- Carlson, A., Betteridge, J., Kisiel, B. Settles, B., Hruschka Jr., E.R., Mitchell T.M. (2010): Toward an architecture for never-ending language learning. In Proc. of AAAI-10, pages 1306–1313, Atlanta, GA, USA.
- Fader, A., Soderland, S. Etzioni O. (2011): Identifying relations for open information extraction. In Proc. of EMNLP-11, pages 1535-1545, Edinburgh, Scotland, UK.
- Poon, H., Domingos, P. (2010): Machine Reading: A "Killer App" for Statistical Relational AI. 2010 AAAI Workshop on Statistical Relational Artificial Intelligence 2010, pages 76-81, Atlanta, Georgia, USA.
- Schubert, Lenhart K. (2006) Turing’s dream and the knowledge challenge. In Proc. of AAAI-06, pages 1534–1538, Boston, MA, USA.
- Suchanek, F. M., G. Kasneci, G. Weikum (2007): YAGO: A core of semantic knowledge. In Proc. of WWW-07, pages 697–706, Banff, Canada.
