The Emerging Topic “Information Governance Technologies”
The Department of Informatics is currently working on the development of new interdisciplinary research topics that focus on technical, legal, economic and social aspects of the development and use of IT. This is not only about technical concepts, but also about processes, or more generally about a framework for the use of IT, which is not only driven by technology, but also considers social, ethical and legal questions right from the start.
By information governance technologies we mean, on the one hand, the definition and socio-technical implementation of decision-making rights and responsibilities for an economically meaningful, socially acceptable and technically feasible extraction and processing of information. On the other hand, technical systems must be designed in such a way that they meet the requirements and have no or at least minimal negative secondary effects for people and society.
The basic conditions under which modern information governance takes place are:
- blurring boundaries between institutional and individual information processing,
- growing convergence of analytical and transactional information processing,
- increasingly critical dialogue on institutional information processing and
- increasing competitive relevance of processing large amounts of information.
The technology-relatedness is made clear by the fact that the design of information processing processes would no longer be conceivable without the innovations of technology and informatics.
Further development of the Department
As society becomes increasingly dependent on information technology, so too does the responsibility that computer scientists bear. Critical infrastructures such as energy supply, transport and traffic can no longer do without reliable information technology (IT). Communication and information systems themselves have become a critical infrastructure.
The Department of Informatics has a long tradition in researching the interactions between technology and society. In addition to socially oriented information technology, these were and are in particular topics such as technical data protection and the social responsibility of the computer scientist.
In courses such as “Informatics in Context”, prospective computer scientists at the University of Hamburg learn that the design of IT systems can have far-reaching effects on society. So far, however, these topics have mainly been considered from a purely technical perspective. The focus “Information Governance Technologies” is intended to take a holistic view from an IT perspective. Prospective computer scientists should recognize that responsible action is necessary.
The importance of the “context” becomes clear, for example, in the field of tension between freedom and inner security. Modern media and communication services such as Twitter and Facebook were instrumental in the success of the Arab Spring 2010 and the associated democratisation process. Participation and co-determination processes also change in the political environment through the use of computers. Online elections are increasingly being seriously considered for democratic elections, although neither a social consensus nor suitable technical solutions exist to date.
Demographic change, in particular the change in the age structure, will also require new technical solutions for the care of the elderly and the sick in the future. Service robots can never replace humans, but they are also conceivable in such socially sensitive areas. Even speech recognition, as used to control smartphones today, could in future serve as a substitute for conversation for people who would otherwise be left alone and lonely. In any case, technical solutions have long been feasible. gateways.
Interfaces
Information governance defines the rules of secure and reliable information processing, i.e. provides normative requirements (data protection laws, protection of trade and company secrets, protection and risk management at organisational and operational level) which are to be implemented in information technology within the scope of the scope for design. On the other hand, technology design and technical innovations have a direct impact on information governance, in that new technical possibilities also require new rules within and between the actors (examples of recent years here are the strong spread of social networks and mobile terminals and their repercussions on data protection and IT security in companies).
Efficient and established management frameworks such as COBIT (Control Objectives for Information and Related Technology), COSO (Committee of Sponsoring Organizations of the Treadway Commission) or ITIL (IT Infrastructure Library) now exist in the area of IT governance. These are supplemented, for example, in the more specific area of security management by “best practices” such as ISO2700x or BSI basic protection. However, these approaches often lack a scientifically founded perspective and system. The more a company relies on IT processes to create value, the more dependent it is on the error-free and reliable functioning of IT systems and the traceability of correctness properties. For this reason alone, modern approaches to information governance must open up more and more to a scientific and research-oriented perspective.
Modern information governance now goes so far that normative requirements (e.g. privacy by design) directly influence the design of technology. We therefore also see a growing importance of information governance in connection with technology design, i.e. information governance technologies.
Architecture of a field of research “Information Governance Technologies”
Information governance is required at various levels of an IT system: The design of services must be based on the applicable laws and guidelines for data processing (e.g. data protection laws). At the data level, technical aspects of division are generally relevant, but can have repercussions on information governance. For example, if data is to be stored efficiently and cost-effectively “in the cloud”, appropriate protection mechanisms and availability requirements must be defined. The same applies to the infrastructure level (networks and computers).
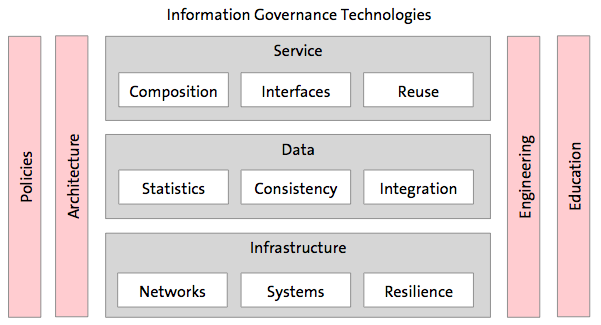
Within the framework of the design of services and data, their processing and storage as well as infrastructures, methods for the design and operation of systems (architecture and engineering) that interact with rules (policies) and design knowledge (education) develop within the framework of a governance evolution. There are strong interfaces (starting points) in information governance research with other disciplines such as economics, social sciences and law. This underlines the social relevance of the topic of information governance.
Levels
Services Level
Composition of secure services. The composition and interaction of secure (software) services and components does not directly lead to a secure overall system. Although trusted computing solutions already exist for individual aspects (e.g. secure booting), there is a lack of universal description languages for secure components and interfaces, their interaction and security features.
Design of secure user interfaces of services. With the increasing heterogeneity, mobility and interactivity of people and devices, the secure design of user interfaces of services is less a question of technical possibilities. In addition to primary system functions, safety-critical functions (e.g. user and device authentication) must also be understandable, error-free, safe and reliably operable. Since systems will no longer only be mobile, but also autonomous (including mobile robots), information, control and intervention possibilities in such systems are important safety functions, the design of which has so far been the subject of little research.
Data Level
Statistical theory of network data. Information governance poses the fundamental question of how data should be handled in a responsible manner. One basic aspect of this is always that you first have to assess how reliable your own data actually is. Today, modern company data is often available as a networked structure. Here, the network aspect is not an “unwanted accessory”, but the network structure itself contains important information (examples: social networks as a basis for targeted advertising; dependencies in rules and regulations that are to be recognized and modeled). On the other hand, network data—like other data—is the result of random processes and is subject to natural fluctuations. For example, the members of a social network can be seen as a random sample of all possible customers. Analyses can now be performed on this random data, e.g. the cluster structure can be determined or dependencies modeled. A fundamental question now is whether the findings obtained in this way only represent “random noise” in the network, or can be explained by “true effects”. It is of immense importance to distinguish between these two cases. This requires a statistical theory of network data.
Correctness, consistency. With regard to the correctness of information processing processes and the consistency of the resulting data, control mechanisms and protocols tailored to the respective requirements must be developed. For complex (cross-organizational information processing processes, suitable templates (modules) must be defined wherever possible, which in turn implement information governance policies. These include monitoring components that enable compliance with policies in operational business and provide indicators of when exceptional situations exist and support a corresponding reaction. The latter can often—but not always—be automated, so that there is a limited degree of automation.
Dynamic information integration and delivery. The data volumes to be used are not only extraordinarily large, heterogeneous and distributed (fragmented), but also extremely dynamic in their creation, change and visibility (especially against the background of the inclusion of the Internet). It is correspondingly time-consuming to integrate information taking into account its semantics (e.g. using Semantic Web approaches) as required and in a timely manner and to make it available in the right places in the business processes. Here a stronger involvement of the user is necessary, for example, for purposes of interactive conflict resolution or the supply of meta information, so that a medium degree of automation and interaction is available in each case.
Infrastructure Level
Design of information and communication networks. Questions such as deletion on the Internet and technical possibilities for implementing the &dquo;right to oblivion” (EU basic data protection regulation) are to be dealt with here. The use of malware (Trojan horses, computer worms such as Stuxnet and Flame) to secure state authority raises completely new questions about the use of information technology. If on the one hand the Federal Constitutional Court postulates the new basic computer right, on the other hand the Cyberwar is already in full swing.
Use of private and/or mobile devices in sensitive business and government organizations. New forms of procurement and use of computers in the private and business sector (e.g. Bring Your Own Device) lead to new risks and demand new protection options such as separation of private and communication on one and the same device using secure virtualization. However, this also changes the individual usage behavior of information and information systems. Consumerization, for example, describes a development in which individual and institutional IT are increasingly intertwined, e.g. through the simultaneous use of private and professional information services on one's own smartphone for professional and private purposes. These changed patterns of use and types of communication, with which preferably digital natives flow into companies and society, often stand in clear contrast to the organisational and technical principles of designing complex information systems established in research and practice today. The spread of mobile devices and everyday technologies in particular is creating more and more services that process information directly from and for citizens. There are considerable areas of conflict in the design of these services, e.g. between information-based individualisation and the risk of discrimination against information and information sources. This information processing is based on decision-making rights and duties of responsibility, which on the one hand must be made transparent and on the other must be designed.
Aspects
The research topics in the area of Information Governance Technologies cover the three above-mentioned levels of services, data and infrastructure. In addition to the research topics on various levels, there are those that cross or link different levels. These include aspects of policies, architecture, engineering and education.
Aspect of Policies
Information governance defines the rules of information processing to be applied in services, data and infrastructure. For some areas, there are approaches to specifying and monitoring rules. How can rights and obligations be specified as information-centered and level-spanning as possible? How can their implementation be ensured effectively and efficiently?
Policies are also often rigid. The principle applies that certain data is basically worthy of protection - irrespective of how much individual individuals or institutions have already disclosed to information elsewhere. How can policies be adapted to the level of information and knowledge about individuals and institutions? How can they also adequately reflect the dynamics of information sharing, e.g. to re-examine or question original releases or restrictions in the event of significant changes to the information?
Aspect of Architecture
The technical possibilities and limits of information governance are largely defined by the architecture of information systems. Which architectural patterns can be used to implement certain principles of information governance? What are the consequences of certain architectures or architectural patterns for information governance? Architectural questions arise in particular when the centring of information processing on an institution (e.g. company) is abolished in favour of a company network. Which procedures can companies in networks use to coordinate decisions about their information systems in order to ensure the useful and secure exchange of information in the company network? Which procedures can be used to effectively involve small and medium-sized enterprises (SMEs)? In this context, an Ecosystem Architecture Management would have to be defined.
In an extended form, these questions arise primarily against the background of the integration or separation of private and institutional information. Private and professional information processing is increasingly intermingled on end devices. On the one hand, this opens up opportunities for user innovation if users achieve better results in information processing through privately acquired and used services than through institutionally specified services. On the other hand, institutional services and their data are subject to special requirements for normative reasons. Previous architectures do not take enough account of this overlap area, so that new approaches are required here.
Aspect of Engineering
The development methods used in particular have a considerable influence on the use of opportunities and avoidance of information-related risks. To what extent are information governance requirements reflected in these methods? How can such requirements be taken into account?
In very early phases, the challenge of assessing opportunities and risks in information-based business models is a major challenge for development methods.
A special aspect here are above all economic test procedures. How can the testing of business processes, services, data and infrastructures be more automated with new software tools and services? Which auditing procedures can be used to reduce the costs of the audit while maintaining the same quality?
Aspect of Education
Of course, in a core informatics the design questions of informatics must take centre stage. Nevertheless, the context is important for the training of responsible and educated computer scientists.
Therefore, in addition to the hard technical and algorithmic skills of the computer scientist, application, media and data protection skills as well as ethical skills are increasingly in demand. The design knowledge to be imparted must be broadly based.
Starting with the interdisciplinary Carl-Friedrich-von-Weizsäcker Peace Lecture “Cyber-Security—Cyber-War—Cyber-Peace”, organized by the Department of Informatics together with the Center for Science and Peace Research (ZNF) and the Institute for Peace Research and Security Policy (IFSH) in the winter semester 2013, the discussion has already initiated an aspect of responsibility. Contributions on other areas, e.g. the development and management of data-driven IT services for consumers in connection with economics or in the humanities in the field of eHumanities, such as related ethical questions of big data evaluation with methods of machine learning, could follow.
Form the Future
The dramatic changes in the use of IT pose considerable challenges for individuals and institutions in dealing with information, which can only be mastered to a very limited extent with proven IT models, methods and tools. Therefore, new approaches tailored to these changes need to be explored, how institutions and the individuals in exchange with them can design complex information systems.
Information Governance Technologies raise highly interdisciplinary questions that can only be answered in connection with law, social sciences and economics. However, computer science is also particularly in demand here, because on the one hand the ability to analyse computer systems is indispensable and on the other hand a targeted further development of computer systems and computer science methods is also necessary in order to be able to also technically realise a sustainable extraction and processing of information. From the point of view of computer science, a socio-technical perspective is indispensable for this, because methodological and technical progress ultimately has to face up to evaluation in individual and institutional contexts of use.
A key question for Information Governance Technologies could be:
How do we use the opportunities of data-driven innovation while preserving informational self-determination?
or, shortened a little:
How do we become owner of our data again?
Central to this development will be new approaches for the development of software, its integration with the context of use through the design of socio-technical systems and IT security and data protection aspects at all levels of development and use.